一个小解码器让所有模型当上领域专家!华人团队新研究正在引起热议。
他们提出了一种比目前业界主流采用的DAPT(领域自适应预训练)和RAG(检索增强生成)更方便、且成本更低的方法。
- 相比DAPT,不需要昂贵的全参数训练;
- 相比RAG,不依赖昂贵的检索。
而且实验结果显示,其方法能够显著提升Qwen和Llama等模型在三个专门领域(生物医学、金融、法律)的效果,并使困惑度平均降低6.17分(相当于预测下一个词的正确率提升了约20%~25%)。

好好好,不卖关子了,原来这是来自上海交大、上海AI Lab等机构的研究人员提出的一个名为“Memory Decoder”的预训练记忆模块——
通过使用一个小型的前置解码器(former decoder),能够学习模仿外部非参数检索器的行为。
翻译成大白话就是,Memory Decoder就像给大模型加了一个“领域知识插件”,既高效又灵活,为大模型适应特定领域提供了一种新方法。
划重点,即插即用、无需改变原始模型参数、可以和任何共享相同分词器的大语言模型集成。
对于这一新研究,有网友激动表示,这改变了游戏规则。
下面详细来看论文内容。
随着大模型在通用任务中适应良好,业界目前均在尝试用不同方法让其更适配特定领域。
论文也是瞄准了这一目标,并提出了一种即插即用的预训练记忆模块——Memory Decoder。

和DAPT、RAG等主流方式相比,其优势相对明显:
(1)DAPT(领域自适应预训练)需要对模型全参数进行训练(即把模型整个重新训练一遍),成本高昂,且容易出现“灾难性遗忘”(即忘记之前学到的通用知识)。
(2)RAG(检索增强生成)则因需要进行耗时的近邻搜索,且处理更长的上下文,通常会导致推理速度变慢(延迟增加)。
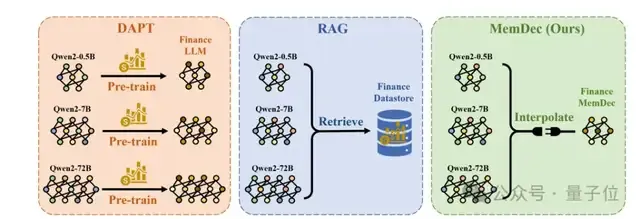
而Memory Decoder本质上是一个小型Transformer解码器(作为“记忆模块”),其核心思路为:
- 在预训练阶段,让它学习模仿一个外部检索器的行为,把特定领域的知识压缩到自己的参数里;
- 在推理阶段,把它和大模型一起使用,通过结果融合提升预测质量。
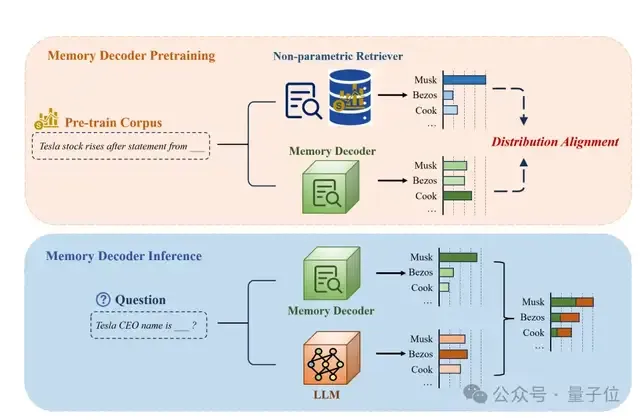
举个例子,当用户问“大众汽车的CEO是谁?”时,大模型通常可能基于通用语料,给出一个模糊的分布(如“马斯克30%,布鲁默40%,库克20%”),但未必足够准确。
有了Memory Decoder后,由于已经在预训练中学会了模仿检索器的行为,会更倾向输出“布鲁默”的分布(如“布鲁默80%,马斯克10%,库克5%”)。
最终,模型会将二者的结果进行插值融合,从而得到更可靠的答案。
这样一来,Memory Decoder就像给大模型配了一个“领域小助手”,既能避免重新训练的高成本,也能免去实时搜索资料库带来的延迟问题,真正实现了低成本、高效率、即插即用的领域增强。
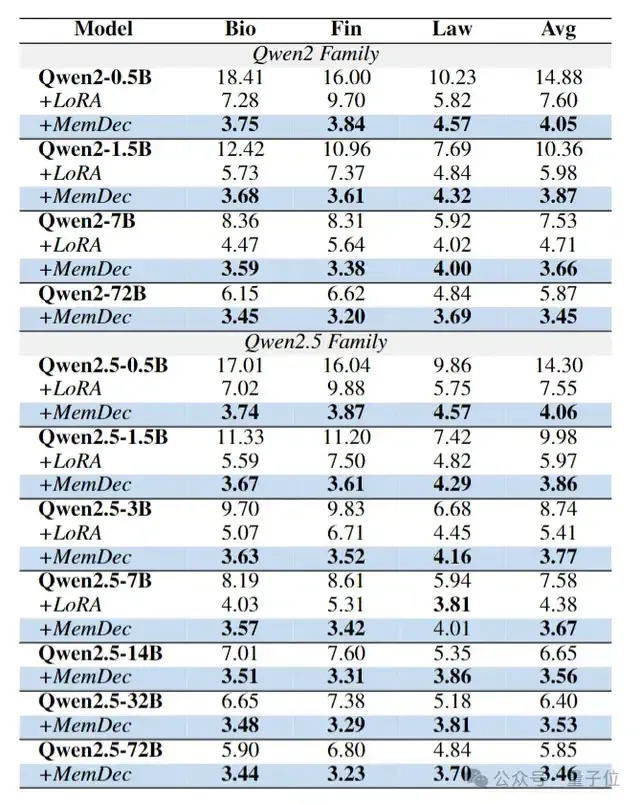
为了验证Memory Decoder的有效性,团队选用了多种Qwen(从0.5B到72B参数)和Llama系列(从1B到70B参数)的预训练语言模型,来测试其在生物医学、金融、法律这三个专业领域的效果。
之所以选这三个,主要是因为它们对模型的专业知识储备要求高,而且传统适配方法经常“铩羽而归”。
具体衡量指标则为Perplexity(困惑度)——数值越低表示模型对该领域文本的理解和预测越准确。
最终实验结果如下:
可以看到, 不管原模型参数量多大,Memory Decoder均能起到领域增强作用,而且比传统LoRA方法更有效。
更关键的是,在Qwen2.5上训练的Memory Decoder,只需极少的额外训练(仅为原始训练成本的10%),就能适配Llama系列模型——
不仅显著降低了所有Llama变体模型的困惑度,而且在生物医学和金融领域的表现持续优于LoRA方法。
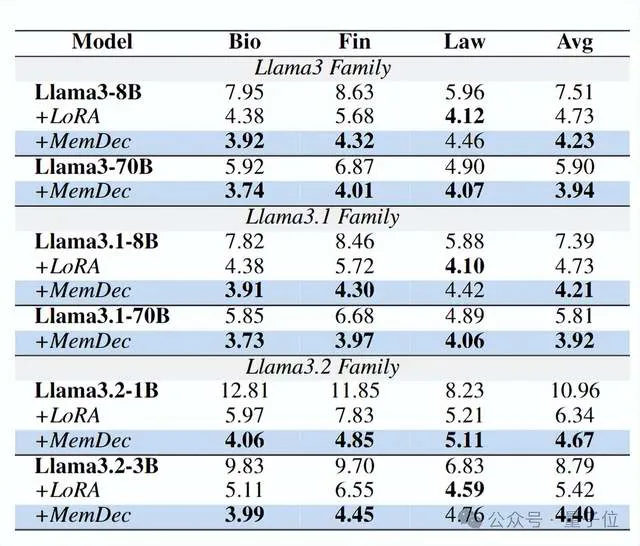
整体而言,在生物医学、金融、法律三个领域中,使用Memory Decoder的多种Qwen和Llama模型,平均降低了6.17分困惑度,初步验证了Memory Decoder的有效性。
不过作者们也在论文最后提到了其局限性:
- 训练阶段存在计算开销
训练Memory Decoder的时候,得从一个大数据库里搜很多相关信息来当“学习材料”,这个搜索过程会消耗不少计算资源。虽然每个领域只需要这么干一次,之后能给各种模型用,但训练阶段这一步依旧无法免去。
- 跨分词器适配仍需部分参数更新
要想把在A模型(如Qwen2.5)上训练好的Memory Decoder用到B模型(如Llama)上,仍需要对嵌入空间进行一些参数更新以实现对齐。
虽然跨分词器适配相比从头训练需要的训练量极少,但无法实现真正意义上的零样本跨架构迁移。
但是有一说一,Memory Decoder最大的意义或许在于,它提出了一种新的范式——
基于特别预训练的记忆组件来进行领域自适应。
这一记忆架构可以即插即用地集成到目标领域的多种模型中,并持续提升性能。
论文: https://www.arxiv.org/abs/2508.09874


