Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建高效、灵活、健壮的模型技术体系。
随着深度学习模型规模的爆炸式增长,它们在各种任务上展现出令人惊叹的性能。然而,庞大的参数量和计算需求也带来了新的挑战:如何在资源受限的设备上高效部署这些模型?如何降低推理延迟以满足实时应用的需求?
模型蒸馏(Model Distillation)正是为解决这些问题而诞生的强大技术。它借鉴了人类学习过程中的“教学”理念,通过将一个大型、高性能的教师模型(Teacher Model)所学到的“知识”,有效地迁移到一个小型、高效的学生模型(Student Model)中。这样一来,学生模型便能在保持轻量级结构的同时,尽可能地逼近甚至达到教师模型的性能水平,从而实现模型压缩和加速的目的。
然而,模型蒸馏不仅是简单的模型瘦身,更是一种深入的知识迁移。但究竟有哪些行之有效的蒸馏方法,能够帮助我们训练出“聪明”又“苗条”的学生模型呢?这些方法的核心原理和应用场景又是什么?

一、模型蒸馏(Model Distillation)主要分类
模型蒸馏(Model Distillation)是一种将复杂模型(通常称为教师模型,Teacher Model)中的知识转移到更轻量、高效模型(学生模型,Student Model)的技术。根据从教师模型中提取和传递信息的方式,模型蒸馏可以分为多种类型,每种类型都采用了独特的方法来实现知识的迁移,从而在保持性能的同时显著降低模型的计算复杂度和资源需求。
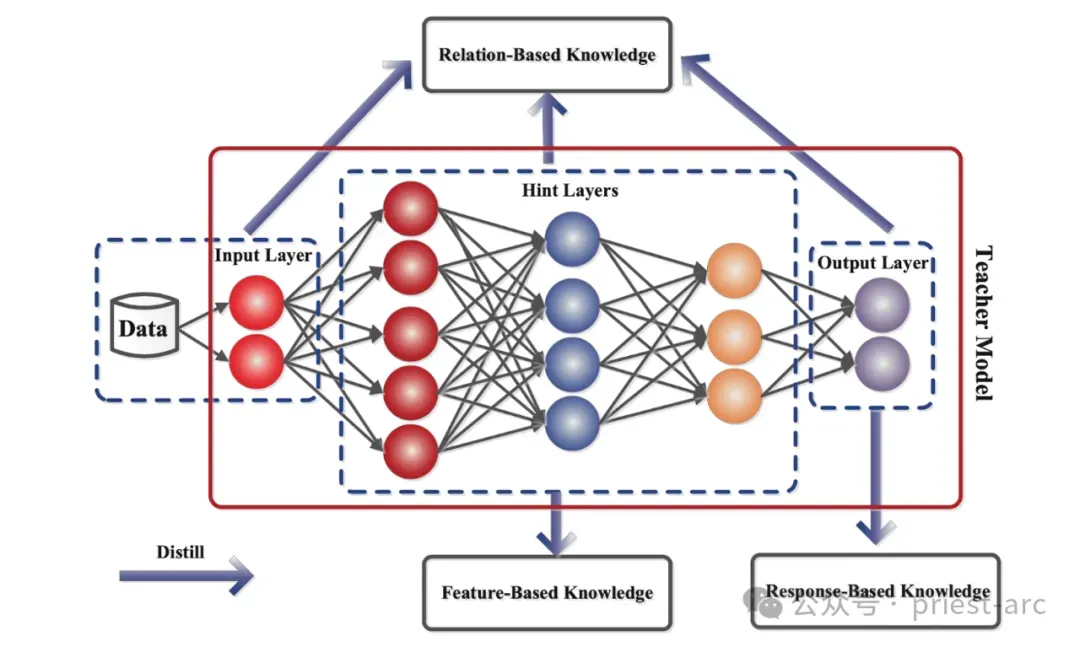
总体而言,模型蒸馏主要分为三种类型,每种类型都以不同的方式将教师模型的知识传递给学生模型,以适应不同的应用场景和性能优化需求。这三种类型分别是:
- 基于响应的蒸馏(Response-based Distillation):专注于模仿教师模型的最终输出,通常以软目标(Soft Targets)形式传递知识,帮助学生模型学习类别间的细微关系。
- 基于特征的蒸馏(Feature-based Distillation):通过提取教师模型中间层的特征表示(如激活值或特征图),指导学生模型学习更深层次的语义信息。
- 基于关系的蒸馏(Relation-based Distillation):关注教师模型内部的结构化关系(如层间关系或样本间关系),使学生模型不仅学习输出,还能捕捉模型的内在逻辑。
二、基于响应的模型蒸馏(Response-based Model Distillation)
基于响应的模型蒸馏,通常也被称为 Logit Distillation 或 Soft Target Distillation,是模型蒸馏领域中最经典和基础的方法。它最早在 Hinton 等人于 2015 年发表的论文 "Distilling the Knowledge in a Neural Network" 中被提出。其核心思想是训练学生模型去模仿教师模型的最终输出响应(通常是 softmax 层之前的 logits 或经过温度缩放后的概率分布),而不是仅仅模仿真实的硬标签(hard labels)。
基于响应的模型蒸馏是最常见且易于实现的模型蒸馏类型,它依赖于教师模型的输出。与直接进行主要预测不同,学生模型的训练目标是模仿教师模型的预测结果。这一过程分为两个步骤,如图 2 所示:
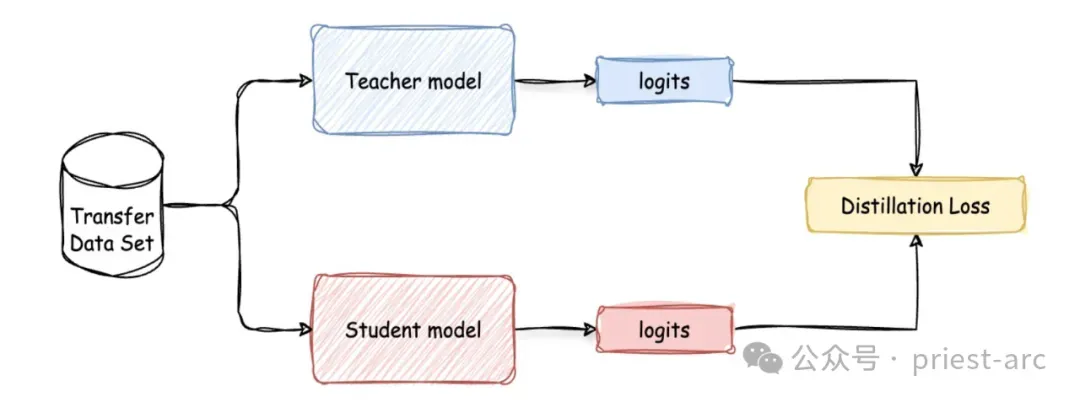
步骤一:首先,训练教师模型。或者,如前所述,也可以使用预训练模型,将其蒸馏到更小的模型中。
步骤二:其次,促使教师模型生成“软目标”(soft targets)。随后,应用蒸馏算法训练学生模型,使其预测与教师模型相同的软标签,并最小化两者输出之间的差异(即蒸馏损失,Distillation Loss,我们稍后会详细讨论)。通过这种方式,学生模型从教师模型的输出中学习,而不是直接从训练数据中学习,从而在计算能力和内存使用效率更高的同时,达到与教师模型相似的准确性。
基于响应的蒸馏过程使用一个转移数据集(transfer data set),从教师模型和学生模型中分别生成逻辑输出(logits),并根据两者逻辑输出之间的差异计算蒸馏损失,以训练学生模型。具体如图 2 所示:基于响应的蒸馏过程使用转移数据集生成教师模型和学生模型的逻辑输出,并通过计算两者之间的差异来定义蒸馏损失,以优化学生模型。
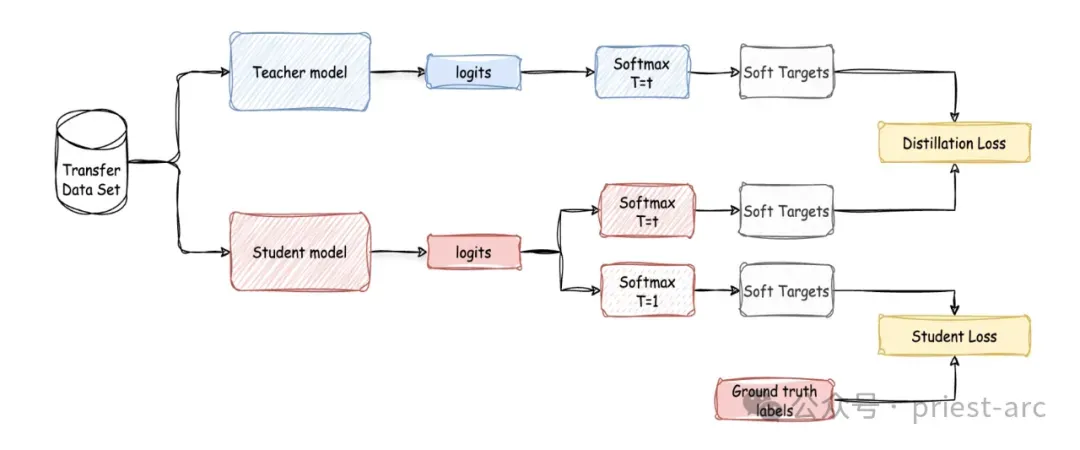
模型蒸馏的一个关键点在于软目标(soft targets)的使用。与传统的硬目标训练方法(使用独热编码的类别标签)不同,模型蒸馏采用软目标,即所有可能类别上的概率分布。
想象一下,你正在训练一个用于将动物图像分类为牛、狗、猫和鸟四种类别的模型。在传统的硬目标训练中,每个图像的标签使用独热编码。例如,对于一张狗的图像,标签为 [0, 1, 0, 0]。然而,在使用软目标的训练中,教师模型提供所有类别的概率分布。对于狗的图像,软目标可能是 [10⁻⁶, 0.9, 0.1, 10⁻⁹],反映了教师模型对每个类别的置信度。
这些软目标提供了类别间关系的细微信息,使学生模型能够更有效地学习。例如,每个概率可以通过 softmax 函数估算,该函数依赖一个温度因子 T 来控制目标的“软度”。温度因子作用于教师模型的逻辑输出之前,生成概率分布。较高的温度产生更柔和的概率分布,而较低的温度则使分布更尖锐。
随后,学生模型通过最小化其预测结果与教师模型输出之间的差异来进行训练。这涉及最小化损失函数,在训练过程中,学生模型的目标函数通常包含两部分:
1. 蒸馏损失 (Distillation Loss):
计算学生模型的输出响应与教师模型的输出响应之间的差异。常用的损失函数包括:
KL 散度 (Kullback-Leibler Divergence): 用于衡量两个概率分布之间的差异。教师和学生的 logits 都会先通过一个带有“温度”参数 (τ) 的 softmax 层进行“软化”,然后计算它们输出概率分布之间的 KL 散度。温度 τ>1 会使概率分布更平滑,提供更丰富的类别间关联信息(即教师模型的“暗知识”)。
均方误差 (Mean Squared Error): 直接计算教师和学生模型输出 logits 之间的 MSE。
2. 学生损失 (Student Loss / Hard Target Loss):
计算学生模型的输出与真实硬标签之间的差异,通常使用交叉熵损失。
最终的总训练损失是蒸馏损失和学生损失的加权求和:
Ltotal=αLdistillation+βLstudent
其中 α 和 β 是权重系数,用来平衡两种损失的重要性。通常在蒸馏训练中,温度参数 τ 在蒸馏损失和学生损失的 softmax 计算中都保持一致,但在推理阶段,学生模型使用 τ=1 的标准 softmax。
基于上述所述,完整的基于响应的模型蒸馏流程可参考如下所示:
三、基于响应的模型蒸馏(Response-based Model Distillation)
基于响应的模型蒸馏(Response-based Model Distillation)是最经典的蒸馏范式之一,其核心在于指导学生模型模仿教师模型的最终输出(如 Logits 或软化的概率分布)。这种方法具有以下优势
1. 易于实现与集成
基于响应的蒸馏方法因其概念直观和实现简单而备受青睐。其核心仅涉及修改损失函数(通过引入软目标和蒸馏损失),无需调整教师模型或学生模型的网络架构。这种设计使其能够无缝集成到现有深度学习训练流程中,例如 PyTorch 或 JAX 的标准训练 Pipeline。
开发者只需通过 Hugging Face Transformers 加载预训练教师模型(如 BERT),即可利用其 logits 生成软目标,快速启动蒸馏过程。
2. 增强模型理解力
与硬标签仅提供单一类别信息不同,教师模型的软化输出(通过较高温度的 softmax 生成)包含了丰富的“暗知识”(Dark Knowledge)。这些知识反映了样本与其他类别的相似性,例如狗和猫的概率分布可能更接近,而狗和鸟的分布差异较大。这种信息帮助学生模型更好地理解类别边界和数据结构,从而学习到更鲁棒的特征表示。
同时,结合 LangChain 的 Graph Index,学生模型可通过软目标进一步捕捉样本间关系,提升语义理解能力。
3. 显著提升学生模型性能
在分类任务中,基于响应的蒸馏能够显著提升学生模型的性能,使其准确率接近甚至达到教师模型的水平,远超直接使用硬标签训练的基线模型。这种性能提升得益于学生模型从教师模型的软目标中学习到的类别分布信息。
例如,在 CIFAR-10 数据集上,使用软目标的学生模型可能将准确率从 85%(硬标签训练)提升至 92%,接近教师模型的 94%。
4. 广泛适用于分类任务
基于响应的蒸馏方法天然适配几乎所有分类任务,包括多分类、情感分析和图像分类等,其基于概率分布的损失函数设计与分类问题高度契合。
同时结合 JAX 的 jax.vmap 向量化功能,可高效处理大规模分类任务中的批次数据,使得在教育、医疗或金融领域的分类应用中,该方法提供了灵活的解决方案。
基于响应的模型蒸馏以其简单性、性能提升和正则化效果在分类任务中表现出色,特别适合快速部署和资源优化场景。然而,其对教师模型质量的依赖、信息传递的局限性以及对非分类任务的适用性不足限制了其广泛应用。具体可参考如下:
(1) 训练过程中教师模型的高计算成本
学生模型的训练需要持续运行教师模型的前向传播以生成软目标,这显著增加了计算开销和显存占用。特别是当教师模型规模庞大(如 GPT-3)或转移数据集较大时,训练成本可能成为瓶颈。
因此,即使使用 DeepSpeed 的 ZeRO 技术优化教师模型的分布式训练,生成软目标的推理过程仍需占用大量 GPU 资源,例如对百万条记录的推理可能需要数小时。
(2) 温度因子(τ)调优的敏感性
温度因子(τ)对蒸馏效果的影响较大,需要仔细调优。较低的 τ 使软目标接近硬标签,传递的信息有限;过高的 τ 则导致概率分布过于平滑,类别间的差异变得不明显,学生模型难以学习有效的决策边界。
此外,调优 τ 通常需要多次实验,例如在 NLP 任务中,τ=2 可能适合小数据集,而 τ=10 更适合大数据集。
(3) 无法充分利用中间特征或样本间关系
基于响应的蒸馏无法捕捉教师模型中间层的特征表示(如卷积层的特征图)或样本间的关系(如样本相似性),这些信息在基于特征或关系的蒸馏中被证明对性能提升有重要作用。
今天的解析就到这里,欲了解更多关于 Helm-Import 相关技术的深入剖析,最佳实践以及相关技术前沿,敬请关注我们的微信公众号:架构驿站,获取更多独家技术洞察!
Happy Coding ~
Reference :
- [1] https://dodonam.tistory.com/364
- [2] https://medium.com/data-science-collective/understanding-model-distillation-in-large-language-models-with-code-examples-557b1012d2eb
Adiós !


