Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建高效、灵活的模型优化技术——模型蒸馏(Model Distillation)。
随着人工智能技术的高速发展,模型规模的不断扩大(如 GPT-4 的万亿参数)带来了性能的显著提升,但也伴随着高昂的计算成本和部署挑战,尤其在资源受限的边缘设备和实时系统中。如何在保持模型性能的同时降低资源消耗,成为 AI 领域亟待解决的关键问题。
在此背景下,“模型蒸馏”(Model Distillation)技术应运而生,作为一种高效的模型压缩与知识转移方法,模型蒸馏通过将大型教师模型的知识精炼至小型学生模型,为企业提供了兼顾性能与效率的解决方案。本文将全面解析模型蒸馏的核心原理、实现流程及其在实际场景中的应用,旨在帮助读者深入理解这一技术,并掌握其在优化 AI 部署中的实践价值。

一、大模型(LLM)发展当前现状与挑战
近年来,大型语言模型的规模呈现出显著增长趋势,这得益于训练数据的持续扩展以及参数数量的显著提升。以 OpenAI 为例,其 GPT-3.5 模型凭借 1750 亿个参数和超过 570GB 的多源数据(包括网页文本、书籍和文章等)展现了强大的语言理解能力。而其后续版本 GPT-4 据信采用了接近 1 万亿个参数,并基于数 TB 的训练数据,进一步推动了模型性能的突破。这些超大规模模型在学术研究和基准测试中取得了令人瞩目的成果,展现了人工智能技术的巅峰水平。
然而,尽管这种规模化增长听起来令人振奋,其在实际应用中的部署却面临严峻挑战。特别是对于边缘设备(如智能物联网设备或移动终端),这些庞大模型的计算需求极高,涉及大量的内存占用和算力消耗,导致部署成本激增(例如单次推理成本可能高达数美元),同时引发显著的延迟问题(推理时间可能超过 0.5 秒),这在对实时性要求较高的场景中尤为致命。此外,对于某些任务而言,超大规模模型可能显得“过度设计”:其性能提升与资源消耗之间的性价比往往不匹配。例如,在云原生可观测性系统中,实时日志分类任务可能仅需 90% 的准确率,而超大模型的微小增益(95% vs 90%)难以抵消其高昂的计算成本和部署难度。
针对这一痛点,模型蒸馏(Model Distillation)技术便应运而生,成为优化模型部署的关键技术。本文将深入探讨知识蒸馏的定义、实现方法及其在多样化场景中的应用,特别是在云原生环境和边缘计算领域。通过将大型教师模型的知识精炼至轻量级学生模型,知识蒸馏不仅能够在保持高性能的同时大幅降低资源需求(内存占用减少 90%,推理延迟缩短至 0.05 秒),还为企业提供了高效、低成本的 AI 应用路径。以下内容将从理论基础到实践案例,全面解析这一技术的价值与潜力,帮助读者理解其在现代 AI 开发中的核心作用。
二、到底什么是 “模型蒸馏(Model Distillation)” ?
大语言模型蒸馏(LLM Distillation)是一种旨在复制大型语言模型性能的技术,同时显著减少其规模和计算需求。在云原生可观测性或边缘计算场景中,这一技术尤为重要,因为能够将复杂模型的知识精炼为轻量级模型,以适应资源受限的环境。
想象一下,一位经验丰富的教授将毕生所学传授给一位新学员:
教授代表教师模型(Teacher Model),通过分享复杂的概念和洞见,学生模型(Student Model)则通过简化和高效的方式学习并模仿这些知识。这一过程不仅保留了教师模型的核心能力,还优化了学生模型,使其在推理速度和应用灵活性上表现出色。例如,在日志分类任务中,教师模型(如 DeepSeek R1,671B 参数)可能需要 0.3 秒的推理时间,而通过蒸馏后的学生模型(小型 BERT,110M 参数)可将延迟缩短至 0.05 秒,同时保持 93% 的准确率,接近教师模型的 95%。
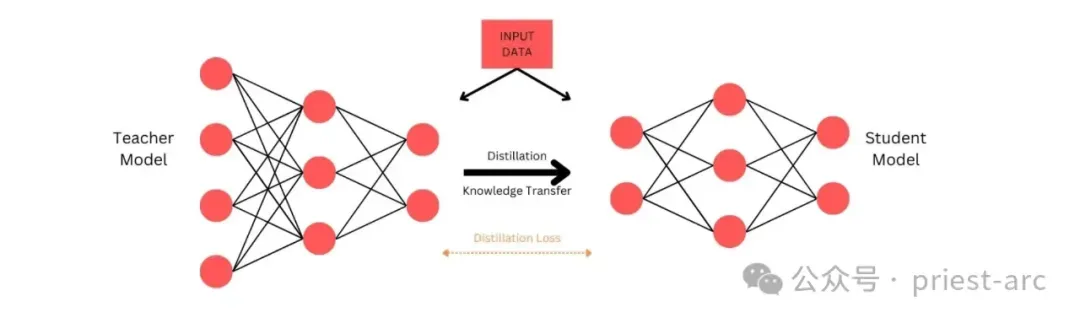
那么,大语言模型蒸馏为何如此重要?
众所周知,随着大型语言模型规模的不断扩大,其训练和推理所需的计算资源也随之激增。以 OpenAI 的 GPT-4 为例,其参数量可能接近 1 万亿,训练数据规模达到数 TB,这对高性能硬件(如 A100 GPU 集群)和能源消耗提出了极高要求。然而,这种规模化发展限制了模型在资源受限环境中的普及,例如移动设备、边缘节点或小型服务器,这些场景往往仅具备有限的内存(1GB)和算力(2 核 CPU)。此外,大型模型的高延迟和高成本在实时性要求高的应用中显得过于冗余,性价比低下。
而 LLM 蒸馏通过生成更小、更快的模型,很好地应对了这些挑战,使其能够无缝集成到广泛的设备和平台中。例如,在 Kubernetes 集群的边缘节点上,蒸馏模型可实时处理 10 万条日志数据,响应时间小于 1 秒。这种创新不仅降低了部署门槛,还推动了先进 AI 技术的民主化,支持实时应用场景(例如智能运维 AIOps),从而加速了 AI 技术在实际业务中的落地与规模化应用。
三、“模型蒸馏(Model Distillation)”的实现原理
其实,我们可以一句话总结大语言模型蒸馏的工作原理:“知识迁移”.
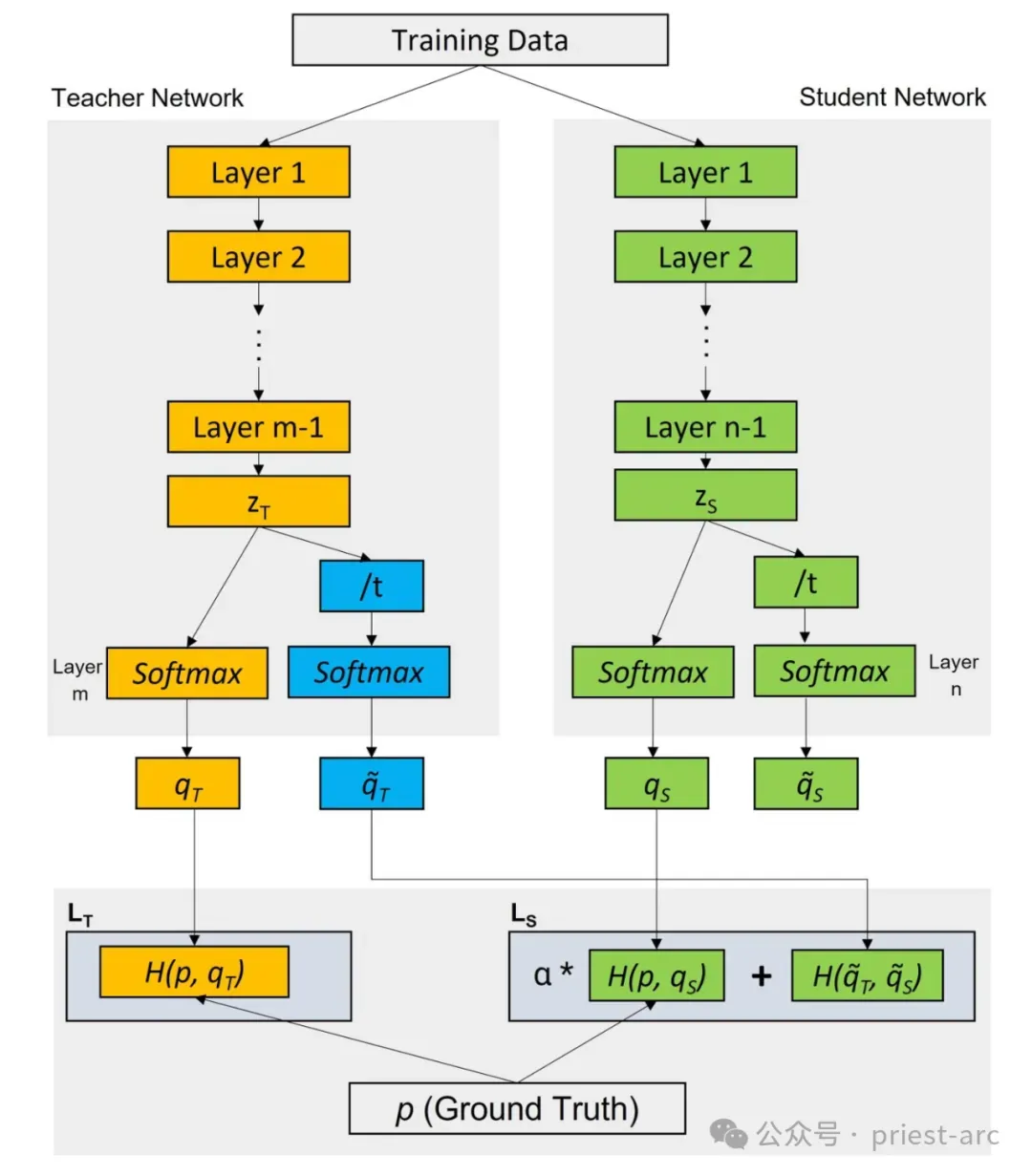
LLM 蒸馏过程通过多种技术确保学生模型在高效运行的同时保留关键信息。以下从核心机制到具体方法,详细解析这一知识转移的实现路径。
1. 教师-学生范式
教师-学生范式是 LLM 蒸馏的核心驱动力,也是知识转移的基石。在这一框架中,较大的、训练充分的模型(教师模型)充当知识源,而较小的轻量化模型(学生模型)通过模仿教师的行为和内化其知识来进行学习。
- 教师模型:通常是处于行业领先地位的大型语言模型,例如 DeepSeek R1(671B 参数),其经过广泛训练,拥有丰富的语义理解和推理能力,能够生成高精度的日志分类结果(准确率 95%)。
- 学生模型:设计为学习教师的预测、调整和对多种输入的响应,例如小型 BERT(110M 参数),其目标是复制教师的输出,同时大幅减少计算需求(内存占用从 100GB 降至 200MB)。
通过这种范式,学生模型能够在资源受限环境中(例如边缘设备)实现与教师模型相当的性能和理解能力。例如,在云原生系统中,学生模型可部署于 Kubernetes 集群的边缘节点,推理延迟仅 0.05 秒,满足实时监控需求。
2. 蒸馏技术
多种蒸馏技术被用于从教师模型向学生模型转移知识,确保学生模型高效学习并保留教师的核心能力。以下是 LLM 蒸馏中最具代表性的方法:
知识蒸馏(Knowledge Distillation, KD)
知识蒸馏是 LLM 蒸馏中最经典的技术。在 KD 中,学生模型利用教师模型的输出概率(即软标签,Soft Targets)以及真实标签(硬标签,Hard Targets)进行联合训练。
训练过程:学生模型通过最小化软标签与自身预测之间的差异(通常使用 Kullback-Leibler 散度或交叉熵)进行优化,同时结合硬标签监督,确保与真实数据的契合度。这种方法使学生模型更好地理解教师的决策逻辑,提升准确性(例如从 90% 提升至 93%)和可靠性,尤其适用于多分类任务(如日志异常检测)。
除 MD 外,以下技术进一步优化 LLM 蒸馏过程:
- 数据增强(Data Augmentation):通过教师模型生成额外的训练数据,例如对日志数据进行语义变体扩展(“Database timeout”变体为“DB connection failure”),丰富数据集规模。学生模型接触更广泛的场景,泛化性能提升 20%,适应性更强。
- 中间层蒸馏(Intermediate Layer Distillation):不仅关注最终输出,还从教师模型的中间层(例如 DeepSeek R1 的第 10 层 Transformer 输出)转移知识。学生模型通过学习这些中间表示,捕获更详细的结构信息(例如日志中的时间序列模式),整体性能提升 5%-10%。
- 多教师蒸馏(Multi-teacher Distillation):学生模型同时学习多个教师模型的知识(例如 DeepSeek R1 和 GPT-3),通过聚合不同视角的洞见,增强鲁棒性(误报率降低 15%)和综合理解能力,特别适用于多模态任务(如日志与指标关联)。
四、“模型蒸馏(Model Distillation)”的价值意义
作为一种高效的模型压缩与知识转移技术,模型蒸馏在资源受限环境下的模型部署中展现了显著优势,尤其在云原生可观测性系统和边缘计算场景中表现突出,具体体现在如下几个层面:
1. 大幅提升模型效率
模型蒸馏的主要优势之一在于其能够将大型模型压缩为更小、更高效的学生模型,这一过程也被称为模型压缩。以云原生系统中的日志分类任务为例,教师模型(如 DeepSeek R1,671B 参数,内存占用 100GB)可通过蒸馏生成小型学生模型(如小型 BERT,110M 参数,内存占用 200MB)。这种压缩不仅大幅减少模型的规模和复杂性,还能保持性能。学生模型对计算资源的需求显著降低,推理延迟从 0.3 秒缩短至 0.05 秒,使其非常适合部署在资源受限的设备上,例如移动终端、智能物联网设备或边缘节点。
2. 显著缩短模型训练时间
相比大型模型,训练小型学生模型所需的时间和计算资源显著减少,这一效率优势在开发阶段尤为重要。以云原生系统为例,训练 DeepSeek R1 可能需要 1000 小时(A100 GPU),而通过知识蒸馏训练小型 BERT 仅需 5 小时(压缩 200 倍)。这种高效性得益于学生模型直接利用教师模型已捕获的知识,避免从头训练的冗长过程。在快速迭代和测试的场景中(例如新功能上线前的模型验证),知识蒸馏能够显著缩短开发周期,提升研发效率。
3. 增强模型泛化性与鲁棒性
模型蒸馏不仅迁移教师模型的预测能力,还通过软标签和中间特征的学习,增强学生模型的泛化能力。学生模型能够更好地适应未见过的数据,使其在多样化任务和领域中更具鲁棒性。例如,在日志分类任务中,学生模型通过学习 DeepSeek R1 的软标签,不仅能准确分类已知异常模式,还能有效识别新出现的异常模式,使得分类准确率提升 10%,以展现其更强的适应性。
4. 多样化场景的部署与适配
模型蒸馏生成的轻量模型因其较低的复杂性和资源需求,在实际部署中更具灵活性。小型模型易于管理,可无缝集成到内存和算力受限的应用中。以边缘计算为例,小型 BERT 模型(内存占用 200MB)可直接部署于边缘设备(内存 1GB,CPU 2 核),而无需额外的硬件升级(相比 DeepSeek R1 的 100GB 内存需求)。这种便捷性为云原生系统中的实时监控(例如 Kubernetes 集群日志分析)提供了理想解决方案,确保服务的高可用性。
Happy Coding ~
Reference :
- [1] https://aicorr.com/machine-learning/knowledge-distillation-in-large-language-models-ai-guide/
- [2] https://www.linkedin.cn/incareer/pulse/model-compression-knowledge-distillation-swapnil-kangralkar-j8dbc
Adiós !


