应用

AI 绘画神插件 LayerDiffusion 教程!直接用文本生成透明底图像!
大家好,这里是和你们一起探索 AI 的花生~
AI 绘画自出现以来一直都在不断发展完善,实现了很多我们在实际应用中迫切需要的功能,比如生成正确的手指、指定的姿势、准确的文本内容等。上周,又一个重磅新功能在开源的 SD 生态内实现了——直接通过文本直接生成透明底图像和图层!这将为 AI 绘画和设计领域带来了新的可能性,使图像形式更多样,也能给设计师带来更多便利。
今天我们就一起来了解实现这一新功能的技术 LayerDiffusion,以及如何在 SD WebUI Forge 和 ComfyUI 中利用 LayerDi

微软 Microsoft 365 版 Copilot 4 月 1 日面向高校推出,拥有 A3 / A5 许可证可免费用
微软今日宣布将面向更多的教育用户提供 Copilot 及 AI 工具包,希望为教育工作者提供免费的 AI 功能以节省时间。微软表示,具有商业数据保护功能的 Microsoft Copilot 现已嵌入所有 Microsoft 365 教育产品中,包括零成本许可证,将提供给所有 18 岁及以上的教师和高校学生,并将在今年春季启动针对年轻学生的私人预览计划。微软还表示将为高校用户提供一项新优惠:专为保护学生设备而设计的 Microsoft Defender for Endpoint 将提供折扣价。从 2024 年 4

Stable Diffusion ComfyUI 进阶教程(一):Controlnet 线条预处理器
前言:我们在前面的基础教程中已经知道怎么去连接 Controlnet 了,接下来我们就要去了解一下不同的 Controlnet 预处理器以及 Controlnet 模型分别有什么效果和作用;
我们先从最常用的“线条预处理器”开始,这也是我们最常用的预处理器之一,我们做动漫转真人、真人转动漫、线稿上色等效果时必用的一个预处理器;
我们会在“Controlnet 预处理器-线条”线条里面发现 14 个不同的预处理器,插件作者一直在更新,也许过段时间大家会看到更多的预处理器。一、线稿
1. Canny 细致线预处理器:①

“一夜变天”,ChatGPT奇迹也将发生在机器人领域
机器之能报道编译:吴昕条条大路通罗马(AGI),虽然方式不同,但我们可以期待非具身 AGI 和具身 AGI 大致同时出现。作为一家炙手可热的人形机器人赛道选手,1X 前阵子秀了一把 EVE 的新成果 。昨天,一直在 X 平台比较活跃的 1X AI 副总裁 Eric Jang 写了一篇文章,公开了其对AI 和机器人技术发展方向的一些预测。两年前,谷歌高级研究科学家 Eric Jang 离开 Google Robotics,加入 1X Technologies(原名 Halodi Robotics)负责 AI 工作。

独家|前百度搜索老将赵世奇从华为离职,回归百度
赵世奇是一名老百度人,在2010年博士毕业后加入百度,一待就是十年,2020年离开百度加入华为做终端云搜索,职级为T22,担任华为终端云服务搜索与地图BU总裁。 赵世奇生于1981年,辽宁抚顺人,在哈工大一路本硕博,从硕士起就主要研究自然语言处理,师从刘挺。 2005年去到微软亚洲研究院实习,在周明的指导下研究聊天机器人,期间发布了数篇顶刊,成绩卓然,2007年又被微软亚洲研究院返聘实习,成功发表了两篇ACL,入选优秀实习生。

刚刚,OpenAI官方发文驳斥马斯克,自曝8年间邮件往来截图
「不幸的是,人类的未来掌握在■■■的手上。」最热科技公司 OpenAI 对全球首富马斯克,这场史诗大战进入了新的高度。刚刚,OpenAI 用一篇长文《OpenAI and Elon Musk》,正式驳斥了马斯克的所有指控。标题简洁,但内容却相当吸引眼球。OpenAI 直接晒出了八年来各位创始团队成员与马斯克的往来邮件截图,并反复重申 OpenAI 对成立使命的不懈追求。文章开篇表示:「OpenAI 的使命是确保 AGI 惠及全人类,这意味着既要构建安全、有益的 AGI,又要帮助创造广泛的利益。我们正在分享我们在实现

Claude 3被玩出自我意识了?AI社区轰动,我们买会员来了次实测
读者福利:Claude 3模型现已在亚马逊云科技的Amazon Bedrock正式可用。Amazon Bedrock 也是目前第一个以及唯一一个提供 Claude 3 Sonnet的托管服务方。此外,亚马逊云科技还向读者开放了2000个体验名额,感兴趣的读者可以点击文后链接注册体验。本周一,Anthropic 发布了新一代大模型系列 Claude 3,遥遥领先快一年之久的 GPT-4 终于迎来了强劲的对手。Claude 3 的强大之处,不仅体现在各种基准测试上,它似乎还实现了一些神奇的突破。昨天,Anthropic

Stable Diffusion 3论文终于发布,架构细节大揭秘,对复现Sora有帮助?
在众多前沿成果都不再透露技术细节之际,Stable Diffusion 3 论文的发布显得相当珍贵。Stable Diffusion 3 的论文终于来了!这个模型于两周前发布,采用了与 Sora 相同的 DiT(Diffusion Transformer)架构,一经发布就引起了不小的轰动。与之前的版本相比,Stable Diffusion 3 生成的图在质量上实现了很大改进,支持多主题提示,文字书写效果也更好了(明显不再乱码)。Stability AI 表示,Stable Diffusion 3 是一个模型系列,参

ICLR 2024 | 为音视频分离提供新视角,清华大学胡晓林团队推出RTFS-Net
视听语音分离(AVSS)技术旨在通过面部信息从混合信号中分离出目标说话者的声音。这项技术能够应用于智能助手、远程会议和增强现实等应用,改进在嘈杂环境中语音信号质量。传统的视听语音分离方法依赖于复杂的模型和大量的计算资源,尤其是在嘈杂背景或多说话者场景下,其性能往往受到限制。为了突破这些限制,基于深度学习的方法开始被研究和应用。然而,现有的深度学习方法面临着高计算复杂度和难以泛化到未知环境的挑战。具体来说,当前视听语音分离方法存在如下问题:时域方法:可提供高质量的音频分离效果,但由于参数较多,计算复杂度较高,处理速度

专访纽约城市大学田英利教授:用多通道、多模态的方法「看懂」手语
与聋哑人交流,是一件成本很高的事情。 首先要看得懂手语,其次是会打手语。 在全球任何一个国家,手语都被归属为一门“小语种”。

第一波!2024年3月精选实用设计工具合集
大家好,这是 2024 年 3 月的第 1 波干货合集!这一期干货合集开头就是两个面向设计师的在线社区,随后是一款帮助创意工作者制作交互游戏的 APP,紧跟其后的 2 款 AI 工具,最后一个工具则是一名资深自由设计师的精选设计工具合集。
当然,在此之前记得看看往期干货中有没有你感兴趣的素材:下面我们具体看看这一期的干货:
1、相对小众的国际设计师社区
Dirbbble 这种单纯分享作品的设计师社区还无法满足你,那么这个名为 Read.cv 的国际设计师社区应该会是你的菜,这里就像一个由高纯度设计师群体组成的 S

百度Comate开放插件生态,智能代码助手定制化时代来临
3月1日,百度旗下智能代码助手Baidu Comate 又添两大重磅能力:“Comate ” 开放平台、AutoWork “私人研发助理”,为行业首家免费开放试用。本次发布,Baidu Comate 将更加贴合软件研发现场,通过易用的研发平台、丰富的插件基础能力、自主定制能力以及企业接入私域知识与自有能力等,更好满足企业定制化开发需求,助力企业低成本打造适合自己企业的智能代码助手,大幅提升软件研发体验和效率。“Comate ” 开放平台实现了将企业私域知识、第三方能力与编程现场深度结合,直接触达研发人员第一工作

新能源时代,国产3D视觉「冲击」保守的汽车行业
在改革开放背景上成长起来的汽车产业,经历了飞速发展,但大量中外合资车企的涌入,也铸就了行业保守的底色,天然对国产供应商比较排斥。 汽车制造业是机器视觉成熟应用的行业之一,但长期以来,国内传统燃油车产线上,举目皆是国外的视觉设备,且占据着最优质的应用场景。 日益茁壮的国产视觉厂商,在车厂有关“进口”、“技术认可”、“成熟应用案例”等的权衡中,不免落入下风。

对手还在卷Demo,他们已经开卷CEO了
机器之能报道编辑:吴昕你们卷Demo,我们卷CEO,奔量产。乍一看好像在做俯卧撑,其实是在充电。Digit工作几小时后就要充电,目前的动作速度也比人类员工慢得多。人形机器人竞争继续升温。Figure AI 掷出 6.75 亿美元融资重磅消息后,另一家深受比尔·盖茨青睐的人形机器人初创公司 Agility Robotics 于周一宣布,前微软高管 Peggy Johnson 将接任公司 CEO,联合创始人兼前 CEO Damion Shelton 将转任总裁。这也是 Agility Robotics 加速商业化的又一

生成式 AI 时代,手机正在进行一次全栈革新?
手机行业的第三次重大变革开始了。最近一段时间,AI 与大模型技术突飞猛进。春节刚过,前沿方向上就迎来了新一轮突破。 OpenAI 的 Sora 一下子把 AI 视频生成的进度条拉快了半年。在大模型的应用领域,技术落地应用的速度也在加快。目前各家大厂的新一代旗舰手机已经悉数登场,它们绝大多数都搭载了大模型,能实现很多前所未有的功能。 图片来自高通骁龙 8Gen3 宣传片: 2024 年入局 AI ?答案似乎很明确。
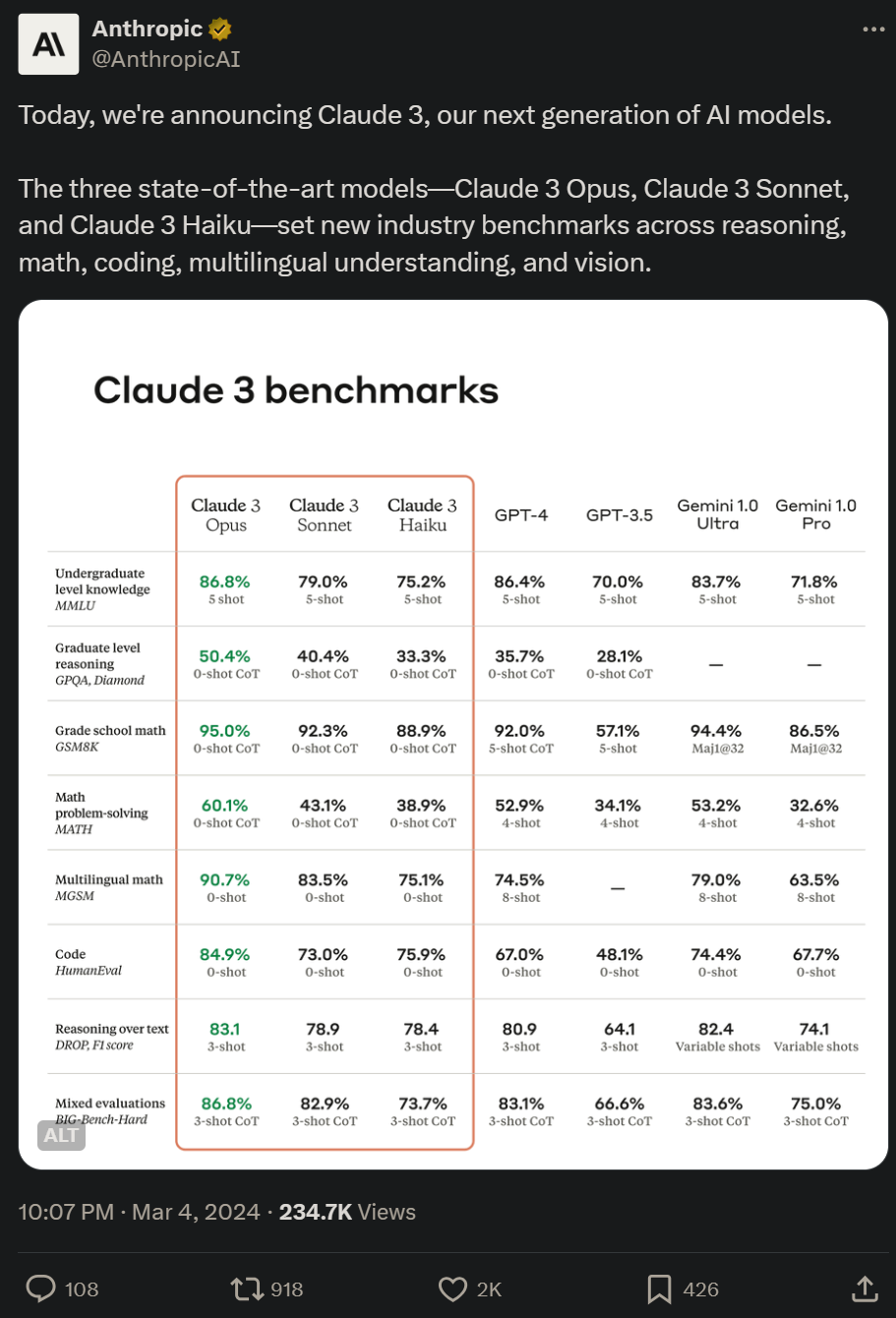
GPT-4时代已过?全球网友实测Claude 3,只有震撼
性能比 GPT-4 强很多。大模型的纯文本方向,已经卷到头了?昨晚,OpenAI 最大的竞争对手 Anthropic 发布了新一代 AI 大模型系列 ——Claude 3。该系列包含三个模型,按能力由弱到强排列分别是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。其中,能力最强的 Opus 在多项基准测试中得分都超过了 GPT-4 和 Gemini 1.0 Ultra,在数学、编程、多语言理解、视觉等多个维度树立了新的行业基准。Anthropic 表示,Claude

0.5秒,无需GPU,Stability AI与华人团队VAST开源单图生成3D模型TripoSR
最近,文生视频模型 Sora 掀起了新一轮生成式 AI 模型浪潮,模型的多模态能力引起广泛关注。现在,AI 模型在 3D 内容生成方面又有了新突破。专长于视觉内容生成的 Stability AI 继图片生成(Stable Difussion 3 上线)、视频生成(Stable Video 上线)后紧接在 3D 领域发力,今天宣布携手华人团队 VAST 开源单图生成 3D 模型 TripoSR。TripoSR 能够在 0.5s 的时间内由单张图片生成高质量的 3D 模型,甚至无需 GPU 即可运行。TripoSR 模

ICLR 2024 Oral:长视频中噪声关联学习,单卡训练仅需1天
在 2024 世界经济论坛的一次会谈中,图灵奖得主 Yann LeCun 提出用来处理视频的模型应该学会在抽象的表征空间中进行预测,而不是具体的像素空间 [1]。借助文本信息的多模态视频表征学习可抽取利于视频理解或内容生成的特征,正是促进该过程的关键技术。然而,当下视频与文本描述间广泛存在的噪声关联现象严重阻碍了视频表征学习。因此本文中,研究者基于最优传输理论,提出鲁棒的长视频学习方案以应对该挑战。该论文被机器学习顶会 ICLR 2024 接收为了 Oral。论文题目:Multi-granularity Corre
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉