最近,文生视频模型 Sora 掀起了新一轮生成式 AI 模型浪潮,模型的多模态能力引起广泛关注。
现在,AI 模型在 3D 内容生成方面又有了新突破。
专长于视觉内容生成的 Stability AI 继图片生成(Stable Difussion 3 上线)、视频生成(Stable Video 上线)后紧接在 3D 领域发力,今天宣布携手华人团队 VAST 开源单图生成 3D 模型 TripoSR。

TripoSR 能够在 0.5s 的时间内由单张图片生成高质量的 3D 模型,甚至无需 GPU 即可运行。
TripoSR 模型代码:https://github.com/VAST-AI-Research/TripoSR
TripoSR 模型权重:https://huggingface.co/stabilityai/TripoSR
TripoSR Demo:https://huggingface.co/spaces/stabilityai/TripoSR
TripoSR 在 NVIDIA A100 上测试时,它能够在大约 0.5 秒内生成草图质量的带纹理 3D 网格模型,性能超越了其他开源图像到 3D 模型,如 OpenLRM。除了速度之外,TripoSR 对有无 GPU 的用户都完全可用。
TripoSR 的灵感来源于 2023 年 11 月 Adobe 提出的 LRM,这是一个用于图生 3D 的大规模重建模型(Large Reconstruction Model,简称 LRM),可以基于任意单张输入图像在数秒钟得到图像对应的三维模型。
LRM 突破性地将图生 3D 模型任务表述成了一个序列到序列的翻译任务 —— 把输入图像和输出的 3D 模型分别想象成两种不同的语言,图生 3D 任务可以被理解为把图像语言翻译成 3D 模型语言的过程。图像语言中的 “单词”(类比语言模型的 token 和视频模型的 patch)是用户输入图像切分成的一个个小块;而在 LRM 方法中,3D 模型语言的 “单词” 是一种被称为 “三平面(triplane)” 的三维表示中的一个个小块,LRM 做的事情就是把图像语言中的 “单词” 翻译成 3D 模型语言中的 “单词”,实现输入图像输出 3D 模型。
在 transformer 架构的支撑下,LRM 在一百余万公开三维数据上进行了训练,展示出了现象级的图生 3D 效果和效率,因此在学界、业界均引起了很大的轰动。然而其相关代码和模型均不开源,巨大的训练代价(128 块 A100 运行一周)也令小型研究组织望而生畏,这些因素极大阻碍了该项技术的平民化发展。
本次 Tripo AI 和 Stability AI 联合共同推出了首个 LRM 的高质量开源实现 - TripoSR,可以几乎实时根据用户提供的图像生成高质量的三维模型,极大地填补了 3D 生成式人工智能领域的一个关键空白。
根据 Stability 的博客和技术报告,该模型基于 LRM 的原始算法,通过精细筛选和渲染的 Objaverse 数据集子集以及一系列的模型和训练改进,显著提高了从有限训练数据中泛化的能力,同时也增强了 3D 重建的保真度。直至 TripoSR 的出现,学术界和开源界一直缺少一个开放、快速、且具备强大泛化能力的 3D 生成基础模型和框架。之前尽管存在如 threestudio 这样受到广泛关注的开源项目,但由于其依赖的技术(比如 score distillation sampling)需要较长的优化和计算时间,使得生成一个 3D 模型既缓慢又资源消耗巨大。Stability AI 此前在这一路线上发布的 Stable Zero123 项目及其在 threestudio 中的集成尝试,虽然取得了一定进展,但仍未能充分解决这些问题。
TripoSR 开源使全球的研究人员、开发者和创意工作者能够访问到最先进的 3D 生成 AI 模型,使各类公司能够利用 3D 内容创建更复杂的产品和服务、探索 3D 行业新的创造可能性,促进一个更加活跃和有竞争力的市场。
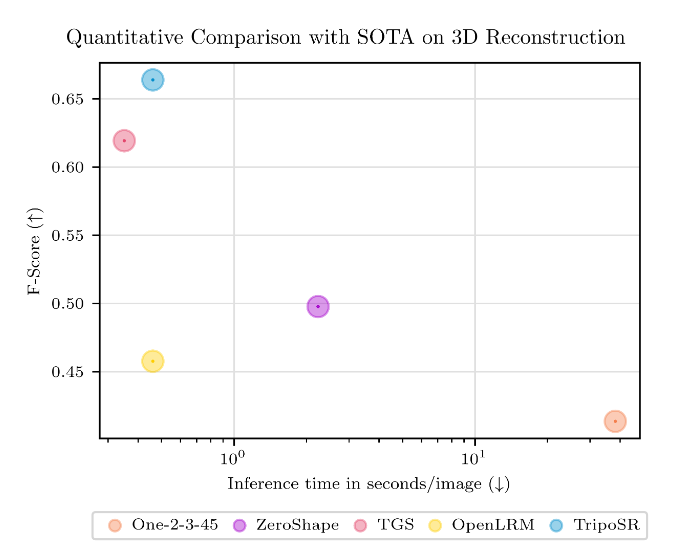
图表显示了 3D 性能的 F-Score(越高越好)与推理时间(越低越好)的关系。
3D 内容生成技术在计算机图形学和计算机视觉领域近年来经历着稳步的发展。在过去一年多时间内,特别是随着大规模公开 3D 数据集的出现以及 2D 图像视频领域强大生成模型的进步,3D 生成技术实现了巨大和快速的进步,引起了工业界广泛关注。在这一背景下,诸如 DreamFusion(由 Google Research 团队提出)等基于 score distillation sampling(SDS)的技术,虽然在多视角生成 3D 模型方面取得了突破,但在实际应用中仍面临生成时间长、难以精细控制生成模型等限制。
与此相对,基于大规模 3D 数据集和大规模可扩展模型架构的生成技术方案,如此次发布的 TripoSR,展现了在不同 3D 数据集上进行高效训练的能力,其生成 3D 模型过程仅需快速前向推理,并能在生成过程中易于对 3D 模型结果进行精细控制。该类技术的出现,不仅为 3D 生成技术的快速发展开辟了新的道路,也为业界的更广泛应用提供了新的可能性。
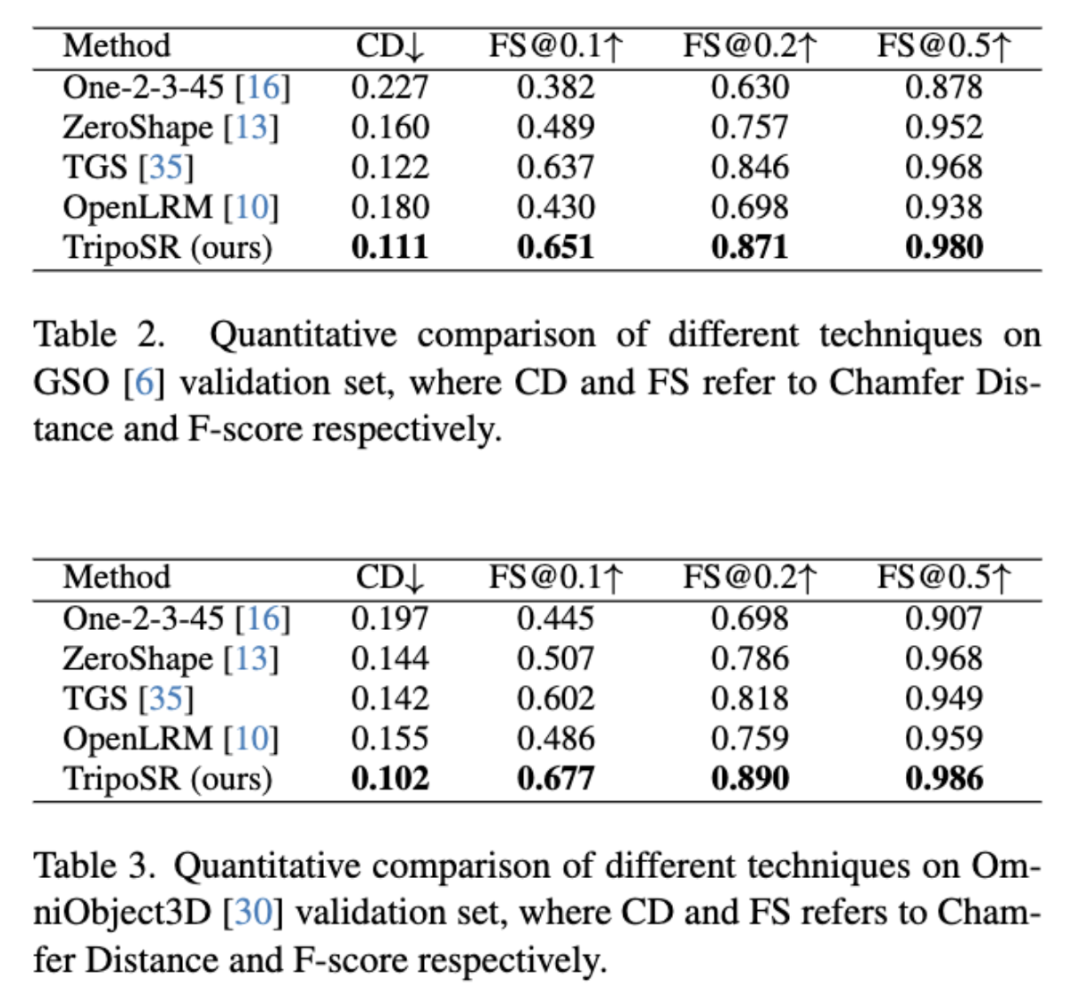

图片和数据来源:TripoSR: Fast 3D Object Reconstruction from a Single Image
值得关注的是,Stability AI 此次与 Tripo AI 联合开源。Tripo AI 背后的研究机构 VAST AI Research 作为 3D 内容生成领域的新锐研究团队,从创立之初就致力于开源社区贡献,相继开源了 Wonder3D、CSD、TGS 等优质研究工作的代码和权重。
Tripo 是 VAST 自 2023 年 12 月推出的通用 3D 生成模型(www.tripo3d.ai)。能实现 8 秒内通过文字或图片生成 3D 网格模型,并通过 5 分钟进行精细化生成,生成模型质量在几何和材质层面都接近手工水平。
根据 VAST AI Research 的博客,AI 在 3D 生成领域的长足发展需要采取一种 “通用方法”,跳出对人类经验的依赖,通过更庞大的数据、更可扩展的模型和充分利用强大计算能力来 “学习”。这一 “通用方法” 应包含多种模态训练数据的统一、多种模态控制条件的统一以及多种模态通用的生成模型基础架构。
为实现这一目标,VAST 认为需要从表示、模型和数据三个方向进行工作。其中,“表示” 的选择至关重要,需要寻找一种既灵活、又利于计算的 3D 表示形式,同时确保与现有图形管线的兼容性。此外,探索 “3D tokenizer” 也是一种有前景的方向,将 3D 表示转化为类似于语言 token 的形式,有助于将现有的理解和生成模型应用于 3D 领域。
在 “模型” 层面,VAST 的研究旨在充分利用大模型在其他模态下的先验知识、设计准则和训练经验,以增强模型对 3D 数据的学习能力。而 “数据” 层面的挑战也不容忽视,优质、原生、多样化的 3D 数据集资源的稀缺限制了模型的最终表现和泛化能力。
TripoSR 让我们看到了生成式 AI 模型在 3D 方向的潜力,我们期待 2024 年 3D 生成领域将会有更多新的探索。
参考链接:
https://stability.ai/news/triposr-3d-generation?utm_source=x&utm_medium=website&utm_campaign=blog