应用

OpenAI SearchGPT 官方演示大翻车,源代码竟暴露搜索机制
SearchGPT 发布刚过两天,已有人灰度测试到了。今天,网友 Kesku 自制的 demo 全网刷屏,SearchGPT 结果输出如此神速,让所有人为之震惊。当询问 Porter Robinson 出了新唱片吗?只见,SearchGPT 眨眼功夫之间,即刻给出了答案「Smile」,最后还附上了链接。再来看移动版本的回答速度,回答延迟几乎为 0。评论区下方,震惊体铺屏。但另一方面,OpenAI 当天放出的官方演示,被外媒《大西洋月刊》曝出其中的问题。在回答「8 月在北卡罗来纳 Boone 举办的音乐节」的问题时,

密苏里大学许东:大模型时代,Prompt 为生物信息学研究带来新动力丨IJAIRR
自ChatGPT在2022年横空出世,人工智能领域便迎来了一场新的革命。 大语言模型(LLMs)以其卓越的文本处理能力,迅速成为研究者和开发者的新宠。 随着这些模型的崛起,如何与它们有效交互的问题也日益凸显,提示词(Prompt)的概念逐渐成为研究的热点。

为什么AI数不清Strawberry里有几个 r?Karpathy:我用表情包给你解释一下
让模型知道自己擅长什么、不擅长什么是一个很重要的问题。还记得这些天大模型被揪出来的低级错误吗?不知道 9.11 和 9.9 哪个大,数不清 Strawberry 单词里面有多少个 r…… 每每被发现一个弱点,大模型都只能接受人们的无情嘲笑。嘲笑之后,大家也冷静了下来,开始思考:低级错误背后的本质是什么?大家普遍认为,是 Token 化(Tokenization)的锅。在国内,Tokenization 经常被翻译成「分词」。这个翻译有一定的误导性,因为 Tokenization 里的 token 指的未必是词,也可以
贾扬清点赞:3K star量的SGLang上新,加速Llama 405B推理秒杀vLLM、TensorRT-LLM
用来运行 Llama 3 405B 优势明显。最近,Meta 开源了最新的 405B 模型(Llama 3.1 405B),把开源模型的性能拉到了新高度。由于模型参数量很大,很多开发者都关心一个问题:怎么提高模型的推理速度?时隔才两天,LMSYS Org 团队就出手了,推出了全新的 SGLang Runtime v0.2。这是一个用于 LLM 和 VLM 的通用服务引擎。在运行 Llama 3.1 405B 时,它的吞吐量和延迟表现都优于 vLLM 和 TensorRT-LLM。在某些情况下(运行 Llama 系列

无视网站反 AI 抓取政策,Anthropic 爬虫机器人惹多个网站所有者不满
据 The Verge 当地时间 26 日报道,Anthropic 公司使用的 ClaudeBot 在短短 24 小时之内,就访问了 iFixit 网站近百万次,此举违反了该网站的使用条款。这一显得有些疯狂的举动,引起 iFixit 的 CEO Kyle Wiens 直接在 X(推特)上开怼,AI在线附大意如下:“如果这些请求(指访问)中的任何一个访问了我们的使用条款,那么它会告诉你我们的内容被明确禁止使用。别问我,去问 Claude!”“我知道你渴望获得数据,Claude 也真的很聪明!但是,你真的有必要在 24

蔚来发布“中国首个”智能驾驶世界模型 NWM:0.1 秒内推演出 216 种可能发生的场景
在今日下午的 NIO IN 2024 蔚来创新科技日活动中,蔚来发布智能驾驶世界模型 NWM(NIO World Model),号称是“中国首个”。据介绍,它是一个多元自回归生成式的具身驾驶模型,可全量理解数据、具有长时序推演和决策能力,能在 100 毫秒内推演出 216 种可能发生的场景,在「万千平行世界」中寻找最优路径。作为生成式模型,NWM 还能基于 3 秒的驾驶视频,生成 120 秒的想象视频。NWM 具备与生俱来的闭环仿真测试能力,已在复杂交互场景中全面测试并验证性能。AI在线从发布会获悉,蔚来还发布了智

70 年前的阿兰・图灵情书!计算机之父和一段「有罪」的罗曼史
1953 年,计算机之父 Alan Turing 和 Christopher Strachey 创作出情书生成器,科技与情感早在 70 年前以情书为载而交汇。在 20 世纪 50 年代初,曼彻斯特大学计算实验室的墙上贴满了小而奇特的情书。情书很寻常,不寻常的是,这些抒发炽热情感的情书是由冰冷算法写成的,远远早于 ChatGPT 出现 70 年。而情书背后的历史更加离奇,1952 年,早在阿尔特曼和 OpenAI 还不知道在哪儿的时候,曼彻斯特大学的两位学生,Alan Turing 和 Christopher Str

大厂实战案例!如何用AIGC快速完成IP设计?
在公司接到一个 IP 形象的设计需求?作为乙方接到了甲方的 IP 设计?想要给自己设计一个 IP 形象?我知道你很急,但是请先别急,AIGC 也能做 IP!
本文邀请大家围观设计师是如何借助 AI 快速生产出 “图图”IP 的~一、图图是谁?为什么要做?
“图图“是 58 最新开发的图库平台-图狗 TUGO 的 IP 形象,本文将为大家带来 AIGC 是如何帮助设计师更高效地进行 IP 形象设计,为 IP 设计提供全新的创作方式和灵感。
IP 形象设计作为品牌设计延伸的一种,承载着品牌的独特性与想象空间。在品牌宣传

“AI 分析师”登陆华尔街,摩根大通开始内部推广聊天机器人
据《金融时报》今日报道,摩根大通开始在公司内部推出一款生成式 AI 产品,并告诉员工这款“自有版本的 ChatGPT”可以完成研究分析师的工作。▲ 图源摩根大通报道援引摩根大通内部备忘录称,该公司已经向其资产和财富管理部门的员工提供了一个名为 LLM Suite 的大型语言模型平台。高管们告诉员工,LLM Suite 可以通过访问第三方模型帮助他们撰写、生成创意和总结文件。LLM Suite 被描述为一个“类似 ChatGPT 的产品”,用于“通用生产力”领域。知情人士表示,摩根大通今年早些时候开始向部分银行员工推

大模型厂商密集发力,谷歌也开“卷”了:Gemini 聊天机器人换上新模型,还能一键核查输出内容
Meta、OpenAI 等大模型厂商密集发力之际,谷歌也宣布了一项重磅更新 ——即日起,Gemini 聊天机器人将改由 Gemini 1.5 Flash 驱动。与之前的版本相比,窗口长度提高到了 4 倍,响应速度也更快了。按照谷歌的介绍,新版聊天机器人背后的 1.5 Flash 模型,主打的就是轻量化和速度提升。当然模型回复的质量也有提升,上下文窗口也从原先(基于 1.0 Pro)的 8k 提升到了 32k。此外新版聊天机器人还增加了“事实核查”功能,可以一键检测生成的内容是否属实,减轻模型幻觉带来的不良影响。有网

智谱 AI CEO 张鹏谈文生视频:当前可用来做影视辅助工作,若要改变电影制作仍需距离
据新浪科技报道,智谱 CEO 张鹏今日接受采访,谈到了基于生成式 AI 的文生视频技术对影视行业的冲击等话题。他表示,从 OpenAI 的 Sora 出现之后,有关话题就一直在讨论。在国外,这件事已经引起很大影响,包括好莱坞罢工等。张鹏透露,自己有一次在北京电影学院与教师一同讨论此事,众人得出了一致的看法:从技术发展角度来看,大家都认为 AI 的发展“是很好的事情”,也是“很重要的方向”,对影视行业的变化有积极意义。张鹏表示,从目前来看,“至少也觉得如果把这项技术用在直接面向最终观众的生产过程当中,可能还是不太够。

国际奥委会:最大限度发挥 AI 工具影响力,体育人才选拔方式有望得到革新
据新华社报道,在 24 日召开的发布会上,国际奥委会首席信息科技官伊拉里奥・科尔纳表示,已经确定了超过 180 个潜在的 AI 应用场景,要最大限度发挥它们的影响力。据介绍,AI 工具可以在辨别体育人才方面展现价值 —— 通过相应技术,仅凭手机软件就能在世界任何地方“发现”新的体育人才。目前,国际奥委会与英特尔正共同开发相关定制化技术,旨在帮助各国和地区奥委会创新体育人才识别和投资培养方式,相关技术已在塞内加尔完成相应测试。图源 Pexels2026 年,塞内加尔即将迎来非洲地区首个奥林匹克赛事 —— 达喀尔青奥会

推动端侧生成式AI,英特尔已经有了全方位布局
每一个垂直行业,都需要边缘AI。

字节豆包上线吴敏霞、林丹等专属智能体 奥运冠军AI分身实时陪看
2024年东京奥运会即将开幕。7月26日,智能AI助手豆包宣布携手跳水奥运冠军吴敏霞、羽毛球奥运冠军林丹、体育解说员黄健翔及体育解说员刘语熙共同打造专属奥运智能体,用户可以在豆包App中和他们畅聊奥运话题。同时,豆包网页版也将上线“AI带你解读奥运”专区,为用户提供奥运新闻早晚报、赛事回放、AI解说等内容。据介绍,上述明星智能体不仅在对话语气上模拟了几人的性格特征,同时也获得了声音授权,用户可以随时在豆包中体验与这些专业人士交流奥运赛事的乐趣。比如和激情四溢的黄健翔共同探讨足球比赛的战术布局和精彩进球;听林丹讲述羽

微软现支持开发者微调 Phi-3-mini 和 Phi-3-medium AI 模型
微软公司昨日(7 月 25 日)发布博文,宣布在 Azure 上支持开发者微调(fine-tune) Phi-3-mini 和 Phi-3-medium AI 模型,针对不同用例提高模型的性能。例如,开发者可以微调 Phi-3-medium 模型,用于辅导学生;或者可以根据特定的语气或响应风格构建聊天应用程序。Phi-3-mini 模型于今年 4 月发布,共有 38 亿参数,上下文长度有 4K 和 128K 两个版本;Phi-3-medium 模型共有 140 亿参数,上下文长度同样有 4K 和 128K 两个版本

大模型将在医疗、教育领域发力,北京发布“人工智能 +”行动计划
感谢北京市发展和改革委员会、北京市经济和信息化局北京市科学技术委员会、中关村科技园区管理委员会今日发布了《北京市推动“人工智能 ”行动计划(2024-2025 年)》。《行动计划》提出了发展目标:2025 年底,通过实施 5 个对标全球领先水平的标杆型应用工程、组织 10 个引领全国的示范性应用项目、推广一批具有广泛应用前景的商业化应用成果,力争形成 3-5 个先进可用、自主可控的基础大模型产品、100 个优秀的行业大模型产品和 1000 个行业成功案例。率先建设 AI 原生城市,推动北京成为具有全球影响力的人工

开启无缝 AI 语音聊天,OpenAI 下周开始向 ChatGPT Plus 用户推出 Alpha 版 GPT-4o 语音模式
感谢OpenAI 首席执行官山姆・阿尔特曼(Sam Altman)今天回复网友提问,表示将于下周面向 ChatGPT Plus 用户,开放 Alpha 版本 GPT-4o 的语音模式(Voice Mode),实现无缝聊天。AI在线今年 5 月报道,OpenAI 首席技术官穆里・穆拉蒂(Muri Murati)在演讲中表示:在 GPT-4o 中,我们训练了跨文本、视觉和音频的端到端全新统一模型,这意味着所有输入和输出都由同一个神经网络处理。由于 GPT-4o 是我们第一个结合所有这些模式的模型,因此我们在探索该模型的
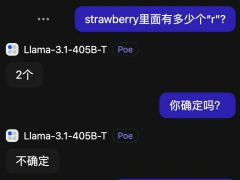
大模型智障检测 + 1:Strawberry 有几个 r 纷纷数不清,最新最强 Llama3.1 也傻了
继分不清 9.11 和 9.9 哪个大以后,大模型又“集体失智”了!数不对单词“Strawberry”中有几个“r”,再次引起一片讨论。GPT-4o 不仅错了还很自信。刚出炉的 Llama-3.1 405B,倒是能在验证中发现问题并改正。比较离谱的是 Claude 3.5 Sonnet,还越改越错了。说起来这并不是最新发现的问题,只是最近新模型接连发布,非常热闹。一个个号称自己数学涨多少分,大家就再次拿出这个问题来试验,结果很是失望。在众多相关讨论的帖子中,还翻出一条马斯克对此现象的评论:好吧,也许 AGI 比我想
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉