应用
科大讯飞2亿成立星盾科技公司,含多项AI业务
天眼查App显示,近日,合肥讯飞星盾科技有限公司成立,法定代表人为胡国平,注册资本2亿人民币。 资料显示,该公司经营范围含软件开发、人工智能基础资源与技术平台、人工智能理论与算法软件开发、人工智能应用软件开发、网络与信息安全软件开发、大数据服务等,由科大讯飞全资持股。

超越DeepSeek-R1!阿里万相大模型登上全球开源榜首
今日,阿里巴巴股价在盘初阶段出现拉升,一度上涨超过4%,报价达到133.1港元。 这一市场表现与近期阿里巴巴在人工智能领域取得的显著进展密切相关。 据开源社区Hugging Face最新发布的榜单显示,阿里巴巴推出的万相大模型在开源仅6天后,便成功超越了DeepSeek-R1,一举登上了模型热榜和模型空间榜两大重要榜单的榜首。

中国历史研究院:本社期刊不接受生成式人工智能工具参与投稿署名
中国历史研究院 2 月 28 日发布《关于规范生成式人工智能工具使用的启事》。

AI理财兴起,投资者迎来财富管理新变革
随着国内 AI 大模型技术的快速发展,投资理财领域正经历一场前所未有的变革,越来越多的投资者开始依赖 AI 进行财富管理。 通过 “理财问 AI”,他们发现 AI 能够提供高效的投资建议和风险管理方案,从而帮助他们更好地把握市场机遇。 在这个新时代,AI 已不再仅仅是科技圈的热词,它逐渐成为了投资者手中的 “理财顾问”。

科大讯飞成立星盾科技公司 含多项AI业务
近日,合肥讯飞星盾科技有限公司在工商部门完成了注册登记,正式宣告成立。 该公司的法定代表人为胡国平,注册资本为2亿元人民币。 天眼查App显示,合肥讯飞星盾科技有限公司的经营范围十分广泛,涵盖了软件开发、人工智能基础资源与技术平台、人工智能理论与算法软件开发、人工智能应用软件开发、网络与信息安全软件开发以及大数据服务等多个领域。

天价域名再现:ai.com挂牌1亿美元,或成史上最贵域名交
据国外媒体报道,资深域名经纪人拉里·菲舍尔(Larry Fischer)正在为一位匿名客户寻求出售极具价值的域名ai.com,报价高达1亿美元,若成交将远超已知最高域名交易记录。 现年62岁的菲舍尔在域名交易领域拥有近30年丰富经验,曾促成多笔高价域名交易。 他的成功案例包括将Messenger.com出售给Facebook、Skincare.com卖给欧莱雅、Teams.com卖给微软,以及将Chat.com出售给HubSpot联合创始人达梅什·沙阿,而后者随即将该域名转售给了OpenAI。

智谱华章完成超10亿元融资 计划开源新一代大模型
近日,北京智谱华章科技有限公司宣布其最新一轮战略融资金额超过10亿元人民币。 这轮融资的参与方包括杭州城投产业基金和上城资本等,显示了市场对智谱的强大信心与支持。 作为国内最早开源大模型的 AI 公司之一,智谱的目标是在2025年成为其开源发展的关键年份。

苹果或需 2027年才能发布真正现代化、对话式的Siri版本
根据《彭博社》记者马克・古尔曼的报道,苹果公司在重建 Siri 以适应生成性人工智能的时代方面遇到了一些挑战,预计该公司要到2027年 iOS20发布时,才能推出 “真正现代化、对话式的 Siri” 版本。 不过,这并不意味着在此之前 Siri 就没有更新。 消息称,一款新版本的 Siri 预计将在今年5月推出,届时将整合苹果公司在近一年内发布的所有人工智能功能。

科大讯飞与华为联手推出全新升级星火一体机,全面提升 AI 应用能力
近日,科大讯飞与华为联合发布了全新升级的星火一体机,这款机器在算力、模型、训练和推理等方面进行了全方位的国化支持,致力于实现快速部署和开箱即用的应用体验。 此次发布的星火一体机包括4U 训推一体机和2U 推理一体机,标志着人工智能在多个领域应用的又一重要进展。 新款星火一体机的最大亮点是支持讯飞星火和 DeepSeek 双引擎的整合。
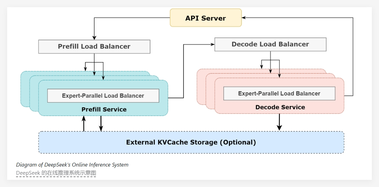
DeepSeek开源周第六天:极致推理优化系统,提高GPU计算效率
在人工智能(AI)技术快速发展的今天,DeepSeek 团队推出了其全新的 DeepSeek-V3/R1推理系统。 这一系统旨在通过更高的吞吐量和更低的延迟,推动 AGI(通用人工智能)的高效发展。 为了实现这一目标,DeepSeek 采用了跨节点专家并行(Expert Parallelism,EP)技术,显著提高了 GPU 的计算效率,并在降低延迟的同时,扩展了批处理规模。
Sesame发布超真实的AI语音产品:几乎没有AI味
语音助手逐渐成为我们生活中不可或缺的一部分,而现有的数字语音助手在与用户互动时,往往显得平淡无奇,缺乏情感和人性化的元素。 对此,Sesame 团队正在努力解决这一问题,致力于实现一种全新的 “语音存在” 概念,使得数字助手能够在交流中更真实、被理解和重视。 Sesame 的核心目标是创造一种数字伴侣,不仅仅是处理请求的工具,而是能够进行真实对话的伙伴。

科大讯飞联合华为发布全新升级星火一体机,支持讯飞星火及 DeepSeek 双引擎
科大讯飞联合华为于 2 月底发布全新升级星火一体机,推出全新的 4U 训推一体机及 2U 推理一体机,从算力、模型、训练、推理到应用,全栈国化支持,快速部署、开箱即用。
开源OCR工具olmOCR:高效实现 PDF 转文本,支持表格与手写识别
olmOCR 是一款开源的光学字符识别(OCR)工具,旨在高效地将 PDF 及其他文档转换为纯文本,同时保留自然的阅读顺序。 这款工具不仅支持普通文本的提取,还能处理表格、数学公式和手写内容,极大地方便了用户对文档的处理需求。 这款工具的核心优势在于其高准确率。

科大讯飞星火 X1 模型升级,数学能力全面对标 DeepSeek R1 和 OpenAI o1
科大讯飞表示,此次升级在数学答题效果上全面提升,尤其是应对竞赛级难题表现显著。同时,星火 X1 在中小学数学作业的批改、辅导以及题目推荐等任务上也展现出了明显的优势。

国内首个光子 AI 智能引擎在南京诞生
南京江北新区企业南京南智先进光电集成技术研究院有限公司(以下简称“南智光电”)联合南京知满科技等合作伙伴开发出国内首个光子 AI 智能引擎“OptoChat AI”,并已完成内部测试,计划 3 月正式上线,免费开放给业界使用。

智谱AI宣布完成新一笔金额超10亿元战略融资
近日,国内领先的人工智能企业智谱宣布完成了一笔金额超过10亿元人民币的战略融资。 此次融资由杭州城投产业基金、上城资本等多家投资机构共同参与,为智谱的进一步发展和技术创新注入了强劲动力。 据悉,这笔融资将主要用于推动国产基座GLM大模型的技术创新和生态发展。

荣耀发布阿尔法计划 5年投入100亿美元建设AI生态
昨晚,MWC2025全球移动大会在上海正式拉开帷幕,荣耀新任CEO李健在会上首次亮相,并正式发布了荣耀的全新人工智能战略计划——“阿尔法计划”。 作为荣耀的新掌舵人,李健在发布会上宣布,未来五年,荣耀将投入高达100亿美元的资金,与全球合作伙伴共同构建AI设备生态,标志着荣耀从智能手机制造商向全球AI终端生态公司的全面转型。 值得注意的是,这也是李健自接任荣耀CEO以来的首次公开亮相。

英语客服印度口音太重?全球最大呼叫中心运营商 Teleperformance SE 推出 AI 语音实时优化系统
全球最大的呼叫中心运营商 Teleperformance SE 推出了一款人工智能系统,可实时调整印度英语客服人员的口音,以提高沟通的清晰度。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉