多模态长文档视觉问答(Multimodal Long-context Document Question Answering, 后文简称 M-L-DocQA)要求系统在给定一份可能长达数十页, 包含:文本、表格、图表、图像与版式元素的 PDF。自动定位并融合跨页、跨模态的证据,最终生成自然语言答案。
 图片
图片
这种任务常见于科研论文、上市公司年报、产品说明书、政府统计报告等场景。深入接触过RAG的读者们,想必都明白其中的技术难点。
当前的技术路线与困境
目前基本上就两条技术路线1、大视觉-语言模型直接端到端(LVLM-based)代表工作:GPT-4V、Qwen-VL、InternLM-XComposer2-4KHD 等。优点:无需显式检索,可一次性读入整图或整 PDF。缺点:
- 上下文长度受限,>100 页 PDF 必须滑动窗口或降采样,导致信息丢失;
- 幻觉严重,在多跳数值推理上错误率极高;
- 黑箱推理,难以给出可验证的证据链。
2、检索增强生成(RAG-based)代表工作:ColBERTv2、M3DocRAG、VisRAG 等。优点:可扩展至任意页数,显式返回证据,降低幻觉。缺点:
- 模态割裂——文本检索器只看 OCR,图像检索器只看截图,二者得分空间不可比,导致“图文不能互通”;
- 跨页碎片化——现有方法以单页或单段为检索粒度,无法建模“页与页之间的语义远距离依赖”;
- 证据粒度单一——要么只召回段落,要么只召回整图,缺乏“页级父页 + 文档级摘要”的多层次证据。
MMRAG-DocQA要解决问题
- 多模态连接缺失。问题关键词往往只与文本局部匹配,而真正答案却藏在图表视觉区,需要建立“文本-视觉”在同页内的语义桥。
- 跨页证据链接与长距推理缺失。答案需要把 A 页的“说明性文字”与 B 页的“数值表格”联合计算,现有方法无法显式聚合跨页语义。
MMRAG-DocQA的方案
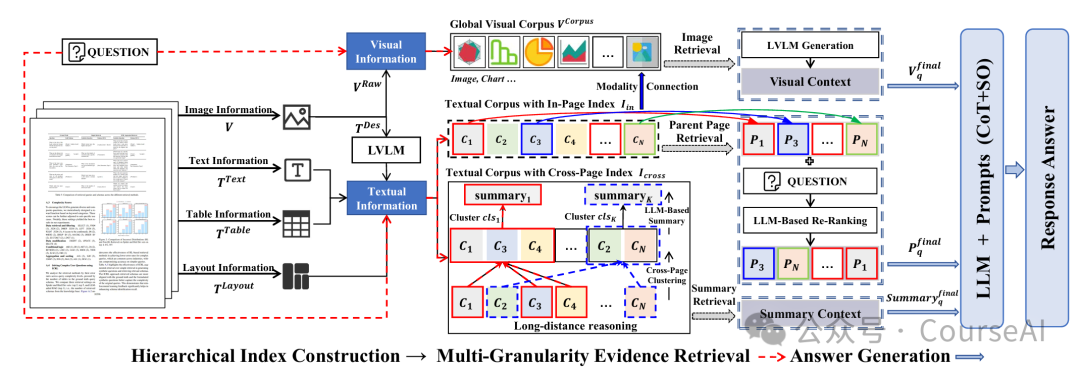
- 首次将“分层索引 + 多粒度检索”引入多模态长文档问答。
- 设计扁平化页内索引(flattened in-page index)与拓扑跨页索引(topological cross-page index),同时建模“同页异模态相关性”与“跨页远距离依赖”。
- 提出页级父页检索(parent-page retrieval)与文档级摘要检索(summary retrieval)两种互补策略,实现粗-细粒度证据互补。
分层索引构造

多粒度检索策略
- 页级父页检索(Modality Connection) 动机:答案图表与描述文字常共处一页,只要召回“相关文本段”,就能顺藤摸瓜拿到同页图像。流程:

- 文档级摘要检索(Long-distance Reasoning)动机:跨页数值对比、多跳逻辑需要“宏观语义”指引,仅靠零散段无法满足。流程:
- 在拓扑索引 I_cross 中,计算 Q 与所有节点向量的相似度;
- 取 Top-K_s 个节点,拉取对应摘要,得 Summary^final_q;
- 摘要已天然融合多页信息,可直接作为“高层证据”。
证据融合与答案生成
最终上下文 ,拼接后送入 LLM。提示模板 P_CoT 要求模型按四步输出:Step-by-step Analysis → Reasoning Summary → Relevant Pages → Final Answer[type],其中 type∈{List,Integer,String,Float},方便脚本自动提取,无需额外正则。
 图片
图片
https://arxiv.org/pdf/2508.00579v2
https://github.com/Gzy1112/MMRAG-DocQA


