1. 研究背景与问题定义
基于扩散的大型语言模型(DLLMs)作为自回归模型(ARMs)的重要扩展,正在成为生成式AI领域的重要创新方向。与传统ARMs按预定义顺序顺序生成标记的方式不同,DLLMs提供了并发标记生成、更高输出多样性、增强全局一致性以及更好的生成文本可控性等优势。近期的突破性模型如LLaDA、Mercury和Gemini Diffusion都凸显了DLLMs的潜力。
然而,当前的掩码扩散模型(MDM)存在一个关键限制:无法有效捕获并发预测的标记之间的依赖关系。这导致在标记间依赖性较强的推理任务中性能下降。例如,在预测"A poker hand that consists of two English words is: a a"的后续两个词时,适合的预测应为"high card"、"two pair"、"full house"或"straight flush"。这些词对之间存在强依赖关系,但MDM在并发预测时会独立采样,无法考虑这种依赖性,从而可能产生不合理的组合。
2. 变分掩码扩散(VMD)模型
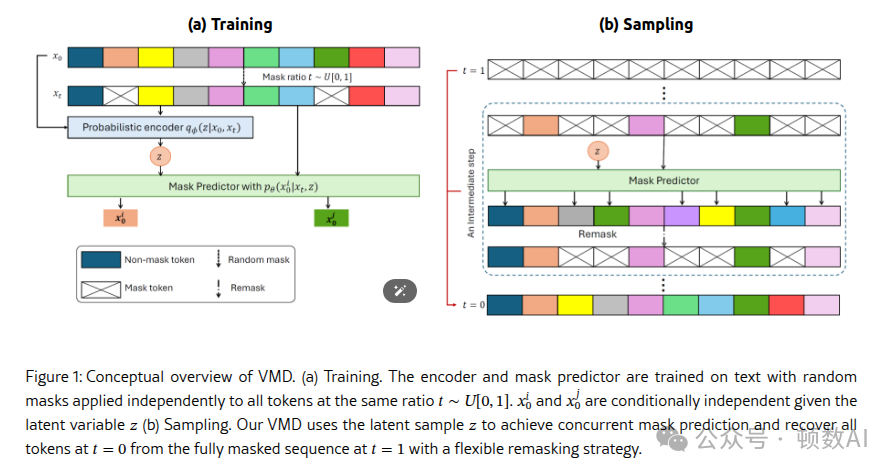
为解决上述问题,研究者提出了变分掩码扩散(Variational Masked Diffusion, VMD)框架,通过引入潜在变量来建模并发预测期间的联合标记分布。VMD的核心思想是:通过潜在变量模型捕获任意联合分布,而不仅仅是可因式分解的分布。
 图片
图片
2.1 基本变分公式
VMD的基本公式为:
复制其中z是全局潜在变量,不依赖于标记位置i。这使得模型能够在标记之间建立联合分布。条件于潜在变量z,标记可以独立采样,但边缘化潜在变量后,能够从正确的联合分布中获得样本。
训练目标函数(NELBO)为:
复制其中p(·)是潜在空间的先验分布,qϕ(·|x0,xt)是由可训练参数φ参数化的近似后验分布。
2.2 块扩散公式
为了解决大规模标记序列中的依赖建模问题,VMD进一步引入了块扩散公式。将标记x分为B个连续块,每个块长度为r,总序列长度L=Br。每个块使用一个潜在变量zb。数据对数似然可以因式分解为:
复制这种方法结合了自回归和扩散模型的优势,在块内使用变分扩散,块间使用自回归处理。通过调整块大小B(或等效的r),可以在自回归变分模型和变分掩码扩散模型之间进行插值。
2.3 重新掩码策略
VMD考虑了两种重新掩码策略:
- 基于概率的置信度:cprob.i = pθ(x0i=v1|xt,z),其中v1是词汇表中最可能的值
- 基于边际的置信度:cmarg.i = |pθ(x0i=v1|xt,z) - pθ(x0i=v2|xt,z)|,其中v1和v2是两个最可能的值
这些策略通过潜在变量提供了更全局的上下文,相比传统MDM的局部置信度指标更为有效。
3. 实验结果与分析
3.1 控制合成数据实验
3.1.1 两标记序列实验
研究者首先在两标记序列上进行了实验,包括确定性依赖、非均匀分布和可变依赖强度三种设置:
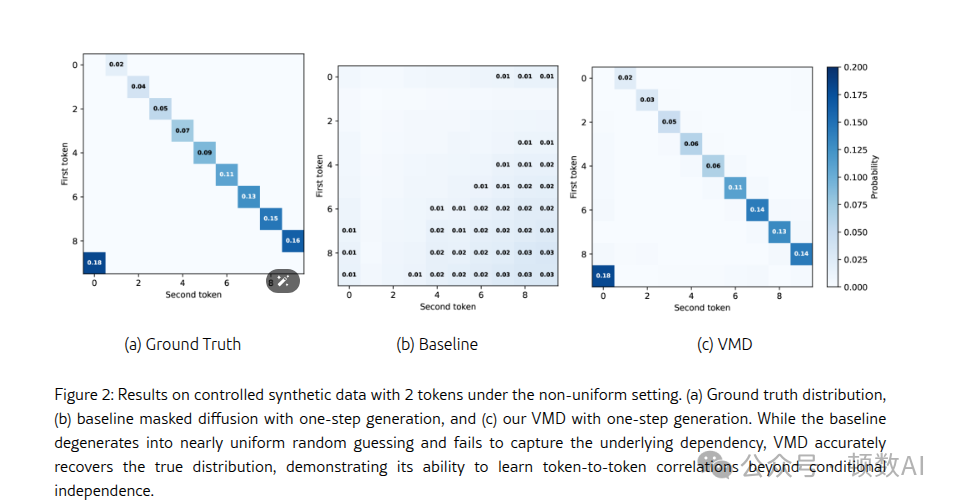
- 确定性依赖:数据为{(k,k+1mod10)}k=0→9,第二个标记完全由第一个决定。标准MDM在并发解码时退化为随机猜测(约10%准确率),而VMD能可靠地生成正确对。
- 非均匀分布:分布为P((k,k+1mod10))=(k+1)/55,k∈{0,...,9}。VMD更准确地从目标分布中采样。
- 可变依赖强度:通过参数p控制依赖强度,VMD在整个依赖强度范围内都能准确建模真实数据分布。
3.1.2 四标记序列实验
在四标记序列实验中,研究者构建了两个数据集:
- D1:包含10个唯一序列{(k,k+1,k+2,k+3mod10)}k=0→9,具有强标记依赖性
- D2:{(k,k+1,l,l+1mod10)}k,l=0→9,第一个长度为2的块与第二个块独立
结果显示,在并行解码所有四个标记时(B=1, NFE=1),标准MDM表现类似随机猜测(D1为0.1%,D2为1.1%),而VMD达到了显著更高的准确率(D1为81.5%,D2为64.4%)。
3.2 数独数据实验
数独是一个9×9网格的逻辑谜题,需要填充空白单元格,使每行、每列和每个3×3子网格都包含1到9的所有数字。这种全局和局部依赖性使其成为评估生成模型捕获标记依赖能力的良好基准。
实验结果表明,VMD在各种采样方法和NFE值下都优于基线模型。特别是在较低NFE值时,VMD的优势更为明显,表明它能更高效地生成有效解决方案。
3.3 文本数据实验
在text8数据集上的实验(包含维基百科的前1亿个字符),VMD达到了比标准扩散基线(SEDD, MDLM)更低的困惑度,并在两种块大小上都比BD3-LM有轻微但一致的改进。特别是在块大小为4时,VMD达到了2.858的困惑度,这是基于扩散模型中的最佳结果。
 图片
图片
4. 技术细节与实现
4.1 模型架构
VMD的编码器和解码器都采用了类似于BD3-LM的架构,但进行了修改以包含潜在信息。为确保公平比较,解码器主干与基线保持相同,而编码器的层数进行了调整,使其架构镜像解码器但参数数量减半。
在数独实验中,模型使用了DiT架构,编码器和解码器分别有4层和6层Transformer层。每个块分配了一个128维的潜在向量,通过共享的自适应层归一化模块注入到解码器的每个DiT块中。
4.2 训练细节
- 合成数据:批量大小10,000,训练2,000步,使用Adam优化器,固定学习率1e-3
- 数独:批量大小1,024,学习率1e-3,余弦学习率调度器,300个周期
- 文本:批量大小512,使用AdamW优化器,学习率3e-4,恒定学习率调度,2,500步预热
4.3 推理过程
推理过程遵循块扩散方法,应用KV缓存以提高采样效率。每个生成的块x0b存储在缓存中,这意味着训练期间使用的前缀上下文x0<b对应于累积的键和值(K1:b-1,V1:b-1)。解码器对块b的预测因此仅依赖于当前噪声输入xtb、潜在变量z≤b和来自早期生成块的缓存上下文。
5. 与相关工作的比较
VMD与其他离散扩散模型和非自回归模型相比具有以下优势:
- 相比标准掩码扩散模型(如LLaDA、LLaDA-V),VMD能更好地捕获并发采样标记之间的依赖关系
- 相比BD3-LM,VMD在保持块自回归结构的同时,进一步提高了并行采样的效率和准确性
- 相比其他非自回归模型(如BERT),VMD通过潜在变量提供了更丰富的文本表示
6. 未来展望
VMD为掩码扩散模型开辟了新的研究方向,未来可能的发展包括:
- 多层次潜在变量:引入层次化潜在变量结构,以更好地捕获不同抽象级别的依赖关系。例如,可以设计一个包含句子级、段落级和文档级潜在变量的模型,每个级别负责不同范围的依赖建模。
- 条件生成增强:将VMD扩展到更复杂的条件生成任务,如文本到图像、跨模态翻译等。潜在变量可以作为不同模态之间的桥梁,促进更一致的跨模态生成。
- 可解释性研究:探索潜在空间的语义意义,开发可视化和分析工具,帮助理解模型如何表示和利用标记间依赖关系。这可以通过潜在空间的降维分析和特定语言现象的干预实验来实现。
- 计算效率优化:开发更高效的推理算法,减少VMD的计算开销。可能的方向包括自适应采样策略、稀疏注意力机制和模型量化技术。
- 应用扩展:将VMD应用于更多需要强依赖建模的任务,如程序合成、数学推理和科学发现。特别是在需要保持全局一致性的复杂推理任务中,VMD的优势可能更为明显。
这些方向不仅具有理论创新性,也有实际应用价值,可以进一步提升生成模型在复杂依赖建模方面的能力,推动生成AI向更智能、更一致的方向发展。
7. 结论
变分掩码扩散(VMD)模型通过引入潜在变量,成功解决了标准掩码扩散在并发标记预测中无法有效捕获依赖关系的问题。在合成数据、数独谜题和文本数据上的实验都证明了VMD的有效性,特别是在标记间依赖关系重要的场景中。VMD不仅提高了生成质量,也增强了对依赖关系的感知,凸显了将变分推理集成到掩码扩散中的价值。
参考资源
- 论文链接:https://arxiv.org/abs/2510.23606
- 代码实现:https://riccizz.github.io/VMD


