在深度学习的世界里,我们常常被各种华丽的网络架构和前沿的应用所吸引,却容易忽略那些看似基础却至关重要的训练参数。
今天,我们要深入探讨的就是模型训练过程中的两个基础术语——Batch Size与Epoch。
这两个术语不仅决定了模型的学习效率,还直接影响着模型的性能和最终效果。
1.Epoch参数
学习的完整循环
在深度学习中,一个Epoch表示模型已经完整地遍历了整个训练数据集一次。
这就像学生完整地复习了一遍所有备考资料。
举个例子,如果你的训练集包含10,000个样本。
那么在一个epoch过程中,模型将会接触到这10,000个样本中的每一个。
这个过程不仅仅是数据的简单遍历,更是模型对数据分布认知的深化。
为什么需要多个Epoch?
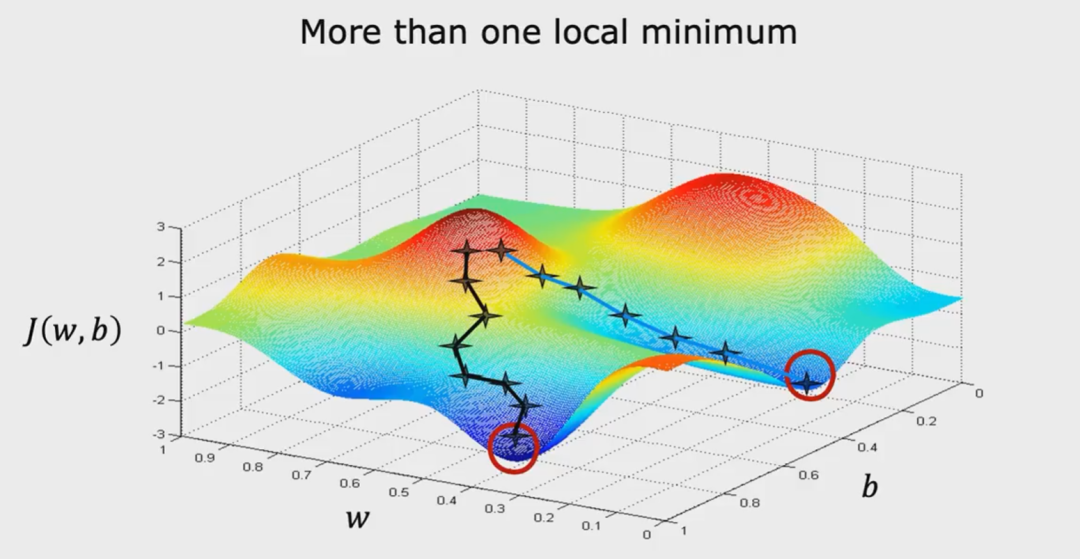
模型很少通过一次完整的数据遍历就能学得很好。 这就像人类学习——我们通常需要反复阅读材料多次才能真正掌握。
模型也需要多次遍历数据集来逐步调整其内部参数,逐步降低预测误差。
 图片
图片

Epoch参数的选择
选择适当的epoch数量需要平衡多方面因素:
Epoch过少的风险:
- 模型欠拟合,无法捕捉数据中的基本模式
- 模型参数未能充分优化,表现不佳
- 类似于学生没有充分复习就参加考试
Epoch过多的风险:
- 模型过拟合,过度记忆训练数据中的噪声
- 模型失去泛化能力,在新数据上表现差
- 类似于学生死记硬背而缺乏真正理解
实践中,我们通常使用早停(Early Stopping) 技术,监控模型在验证集上的表现,当验证误差不再改善或开始上升时停止训练。
2.Batch Size参数
如何控制深度学习的节奏
Batch是同时处理的一组样本,这些样本的平均梯度被用于一次模型参数更新。
Batch Size就是这个组中包含的样本数量。
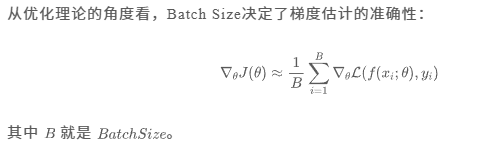
为什么需要Batch?
在深度学习的早期,有两种极端的训练方式:
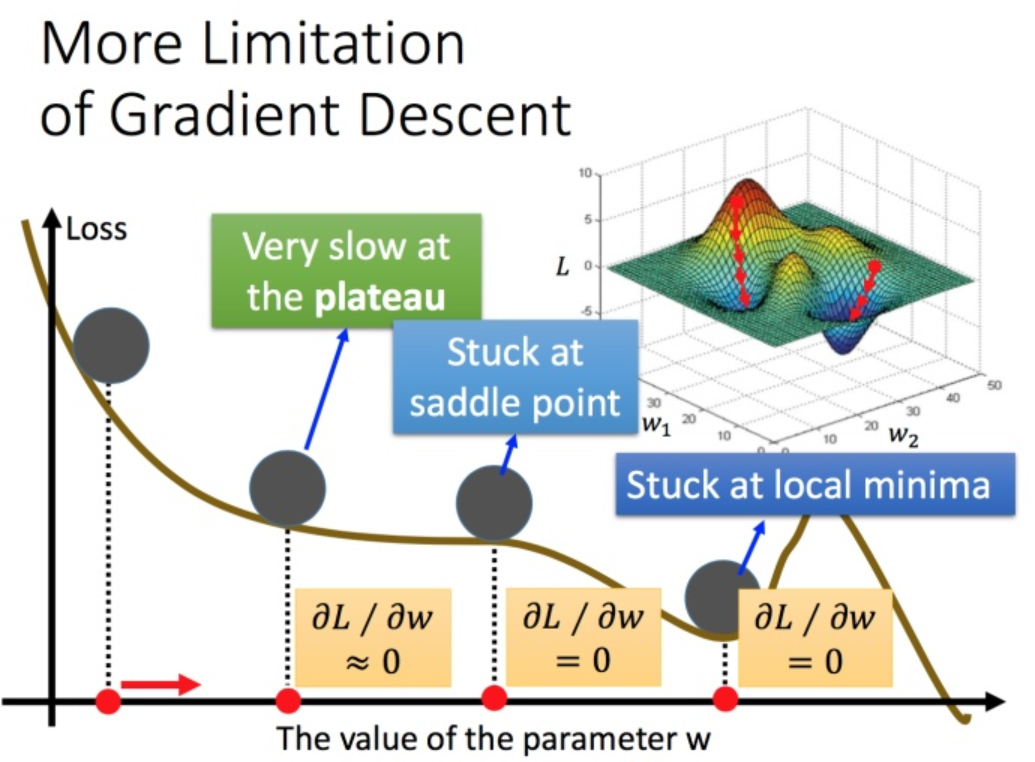
批处理梯度下降(Batch Gradient Descent):
- 使用整个数据集计算梯度
- 每次更新方向准确,但计算成本高昂
- 内存需求大,容易陷入局部极小点
 图片
图片
随机梯度下降(Stochastic Gradient Descent):
- 每次只用一个样本更新参数
- 更新噪声大,收敛不稳定
- 计算效率高,但波动性强
而小批量梯度下降(Mini-batch Gradient Descent) 则找到了完美的平衡点——它既保持了计算的效率,又提供了相对稳定的梯度估计。
Batch Size的多维度影响
选择Batch Size需要在内存使用、训练速度和收敛性能之间权衡。
- 内存方面,大Batch Size需更多GPU内存,受限于硬件。
- 速度方面,大Batch Size可提升硬件利用率和训练速度,但边际收益递减。
- 性能方面,小Batch Size利于泛化,大Batch Size使训练更稳定,但可能影响最终收敛质量。
因此,在选择Batch Size时,需要综合考虑内存限制、训练效率和模型性能等多方面因素,以找到最适合当前任务和硬件条件的Batch Size。
3.参数协同作用
如何更好的进行选择
迭代(Iteration) 是理解Batch Size和Epoch关系的关键桥梁。一次迭代指的是模型处理一个batch并更新参数的过程。
 图片
图片
它们之间的关系很明确:在一个epoch中的迭代次数 = 训练样本总数 / Batch Size
例如,有10,000个训练样本,Batch Size为100:
一个epoch中的迭代次数 = 10,000 / 100 = 100次
总参数更新次数 = Epoch数量 × 每个epoch中的迭代次数
另外,Batch Size和Epoch共同决定了训练的动力学特性:
- 小Batch Size + 多Epoch:缓慢但稳定的学习,通常泛化更好
- 大Batch Size + 少Epoch:快速收敛,但可能泛化能力较差
- 中等Batch Size + 适中Epoch:平衡训练速度和模型性能
结语
Batch Size和Epoch的选择远非简单的技术决策,而是经验、理论和直觉的结合。
真正的专家不仅了解其数学原理,更能根据具体问题、数据特性和硬件条件做出精妙的调整。
深度学习的训练既是一门科学,需要严谨的理论指导;也是一门艺术,需要经验的积累和直觉的培养。


