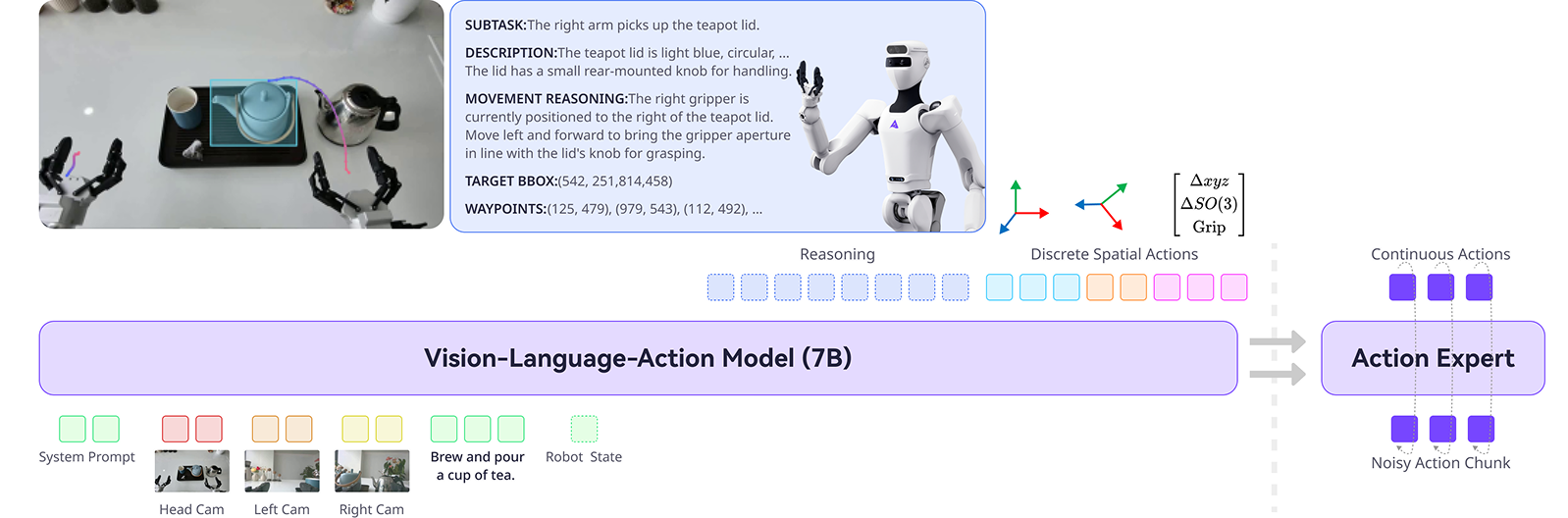
Lumo-1 是一个大规模的视觉-语言-动作(VLA)模型。该模型能够泛化到新的物体、环境和指令 - 包括涉及抽象或间接描述的指令,并且可以高效得适应新任务,包括需要推理或精确操作的任务。
Lumo-1 继承现有视觉-语言模型(VLMs)强大的多模态推理能力,然后逐步将这种能力扩展到关于物理世界的具身推理和真实世界的动作执行。训练过程遵循结构化的三阶段流程:
01.在精选的视觉-语言数据上进行VLM继续预训练,以增强具身推理技能,如规划、空间理解和轨迹预测;02.在跨本体数据和视觉-语言数据上进行联合训练;03.使用在Astribot S1(一个具有类人灵巧性和敏捷性的绳驱双臂移动操作机器人)上收集的数据进行带推理过程的动作训练。最后应用强化学习阶段进一步优化推理结果与推理-动作一致性。动作空间建模
星尘智能提出了一种紧凑的建模方式表示机器人动作序列,能够在不同的机器人和空间中泛化。这种表示方法在保持动作空间意义的同时,减少了数据收集过程中引入的无关微动作。
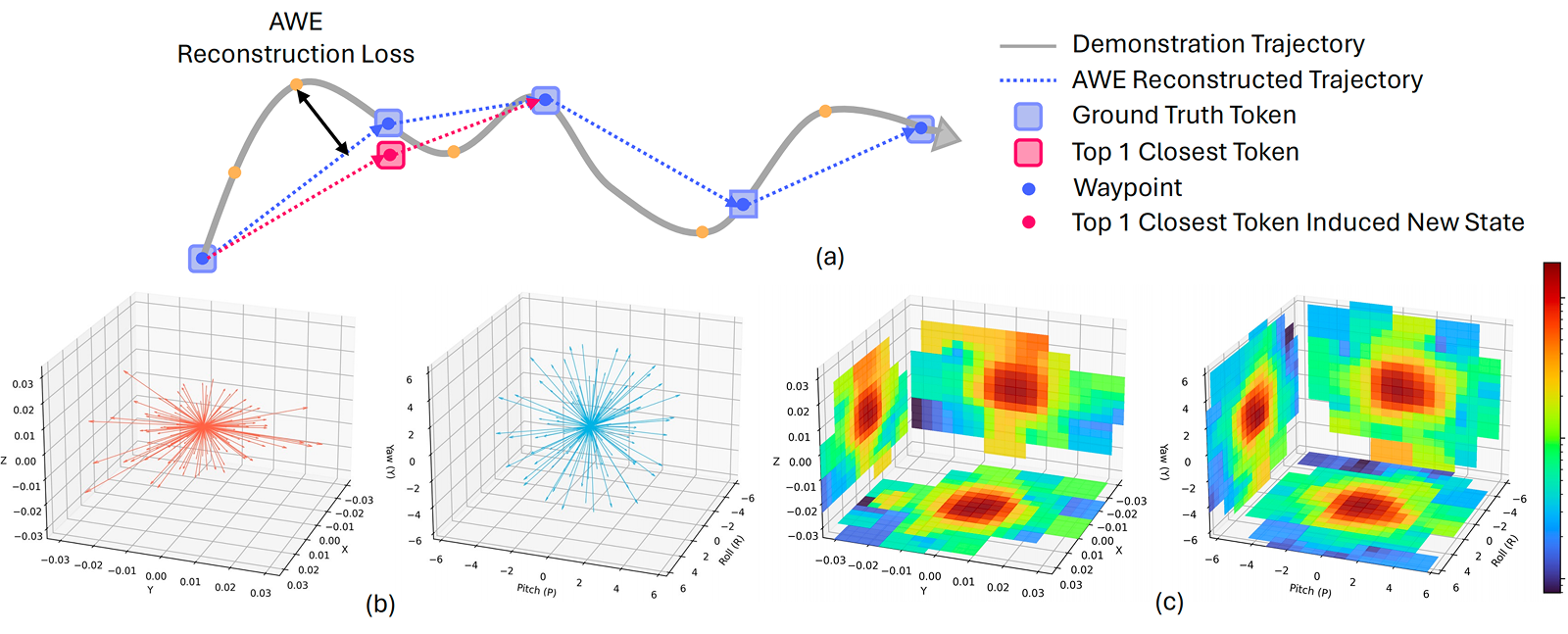
(a)机器人轨迹被分解为在可接受重建误差范围内的最短状态子序列(路径点)。(b)我们通过对大规模、多样化数据集中的增量动作进行聚类来构建元动作库,其中旋转与平移被独立处理。在训练过程中,每个时间步从元动作库中选择与目标路径点距离最近的前三个元动作之一来进行近似。(c)展示了从多样化机器人轨迹数据集中提取的增量动作投影至二维空间的概率密度。
推理驱动目标导向行为
星尘智能不依赖于轨迹记忆,而是培养一种结构化推理过程,使其能够生成有目的性和情境感知的动作。模型进行多种形式的具身文本推理:
01.抽象概念推理整合视觉观测和指令以推断隐含语义;02.子任务推理旨在推断到达最终目标的最优中间步骤;03.视觉观测描述强调对显著场景特征和可操作物体的准确识别和分析;04.运动推理包括对夹爪空间关系的文字推断,以及运动方向的阐述。模型进一步执行视觉推理,以实现基于感知的推断和运动估计。最终,动作轨迹生成被表述为动作空间内的路径点预测,从而将二维视觉理解与物理空间中的连续控制对齐。
强化学习优化推理结果与推理-动作对齐
星尘智能应用强化学习(RL)进一步优化具身推理,并增强高层语义推理与低层运动推理之间的协调。优化由多个奖励信号引导,包括视觉奖励、推理-动作一致性奖励、动作执行奖励和推理格式奖励,共同鼓励连贯且符合物理基础的决策制定。
泛化和指令遵循能力
星尘智能在与GR3一致的四种设置下评估了Lumo-1在可泛化抓取-放置任务上的表现:(1)基础设置,(2)未见环境,(3)未见指令,(4)未见物体。在所有设置中,Lumo-1始终优于基线模型,在涉及复杂指令和以前未见物体的挑战性任务上表现出特别强的优势。
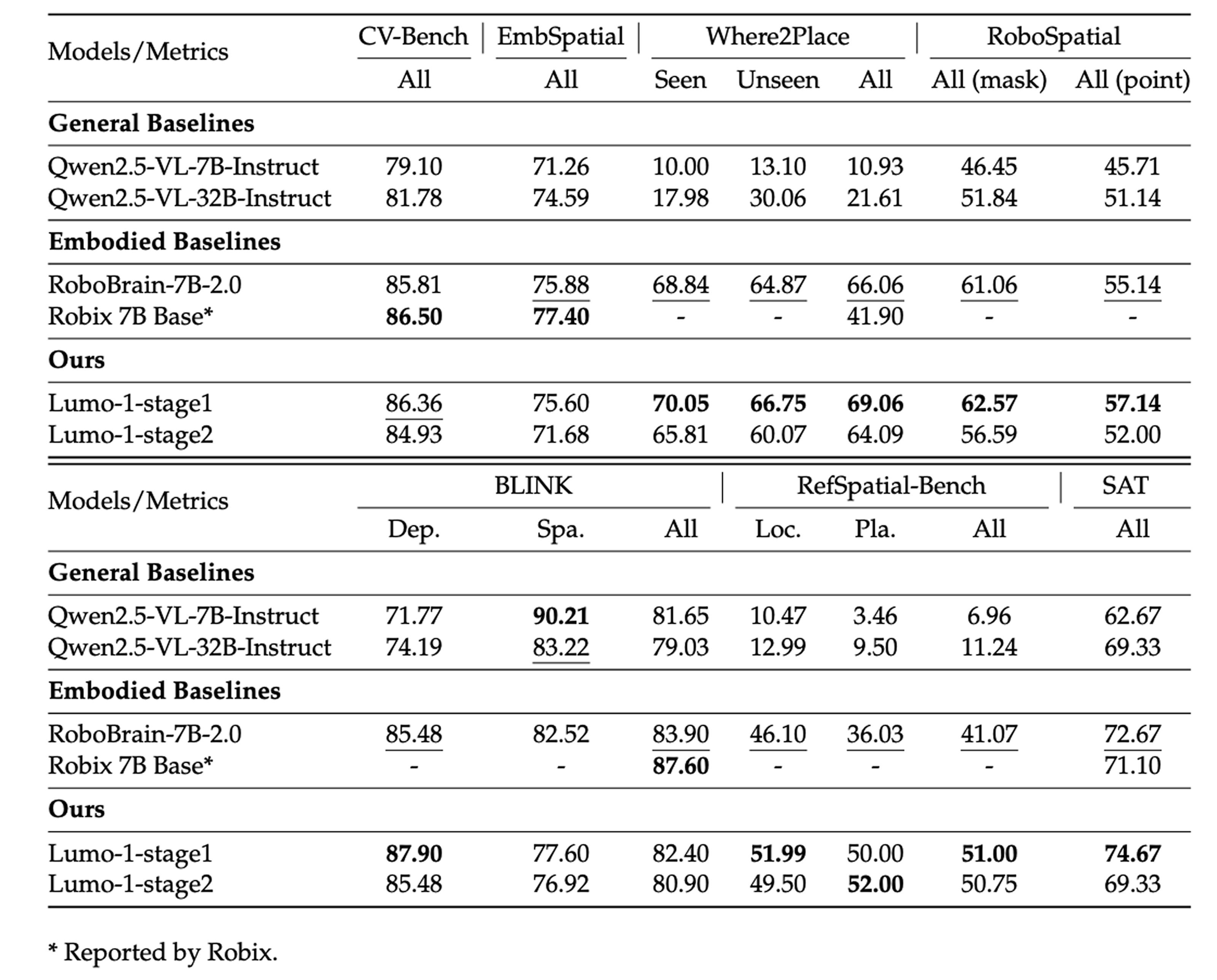
模型“大脑”能力评估
在第一阶段预训练后,Lumo-1在7个基准测试中的6个上优于其backbone模型(Qwen2.5-VL-7B-Instruct),并在大多数任务上超越了专门的具身模型RoboBrain-7B-2.0和Robix-7B。这些结果突显了Lumo-1在物体定位、空间推理和细粒度视觉理解方面的强大能力。此外,这些能力在第二阶段对多样化机器人轨迹进行协同训练后基本保持不变,表明融入动作学习不会损害模型的核心多模态感知和推理能力。
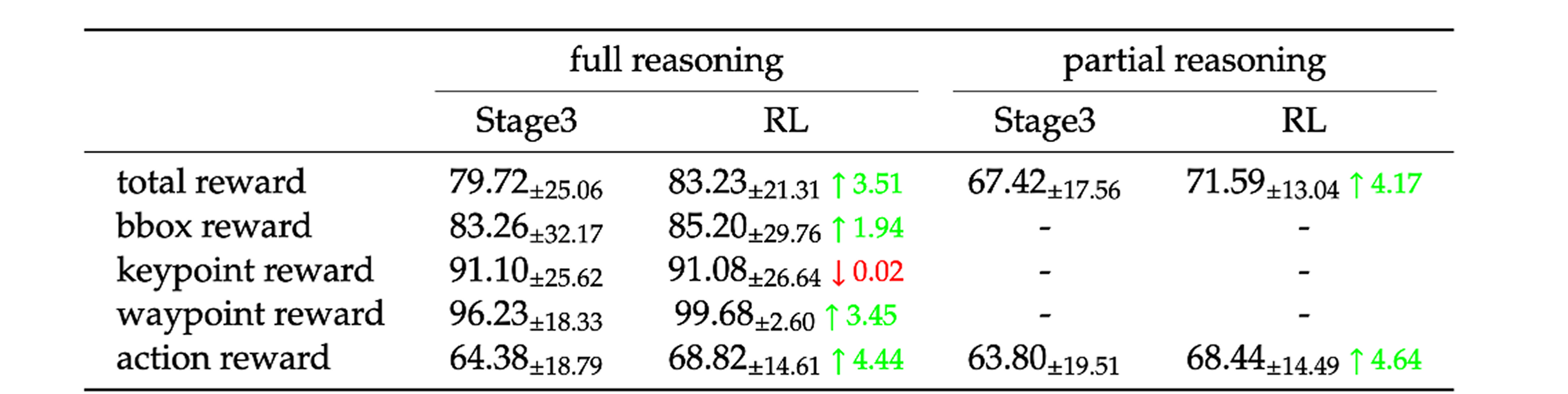
强化学习评估
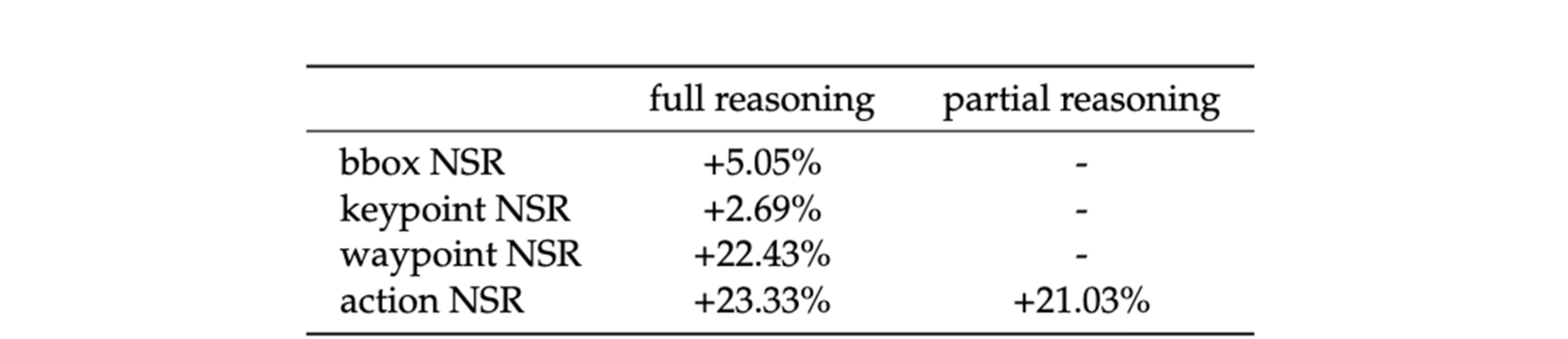
如下表所示,与第三阶段模型相比,经过RL训练的模型在几乎所有评估指标和推理模式下都持续获得更高的奖励值。特别是在完整推理模式下,RL模型在定位关键区域(如边界框、路径点和动作奖励)方面显示出显著改进。
星尘智能还引入了净优势率(NSR)指标,定义为RL训练模型优于第三阶段模型的实例数量 - 第三阶段模型优于RL训练模型的实例数量,并进行归一化。下表显示NSR值始终为正,表明RL训练模型的整体优越性,其中在路径点和动作奖励方面观察到最大的提升。这些结果表明,RL训练阶段有效地增强了模型性能,特别是在轨迹规划和动作执行方面。
Scaling Law
星尘智能采用数据受限扩展定律(Muennighoff et al., 2023),该定律使用指数衰减公式对数据和参数的有效贡献进行建模,其中数据标记的价值在每次重复时大约减少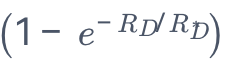 。在固定模型大小的假设下,扩展定律可以进一步简化为:
。在固定模型大小的假设下,扩展定律可以进一步简化为:
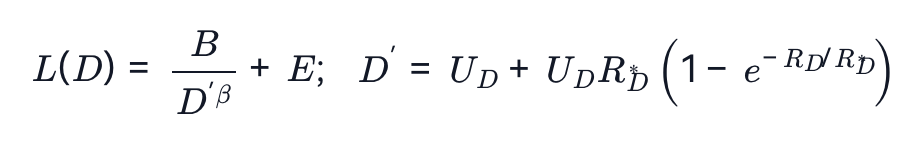
其中E是损失的渐近下界,B控制初始损失幅度,β是扩展指数。表示唯一数据的数量,是数据重复次数,是一个学习到的衰减常数,用于表征重复数据边际效用的递减特性。
星尘智能的主要观察包括:(1)扩展定律的有效性:来自数据受限扩展定律的损失预测与观察值密切匹配,证实了其在数据受限的机器人学习中的适用性。(2)数据多样性的必要性:在没有增强的情况下训练的策略在真实世界变化下表现不佳,突显了多样化训练数据的重要性。使用广泛多样性进行训练,包括提示和图像增强,可以提高对验证扰动的韧性,并减少在完全域外数据(例如,涉及背景、场景、物体)上的损失。


