掀桌,拔网线,彻底拉黑!
本周二,AI领域的两大巨头撕破脸。
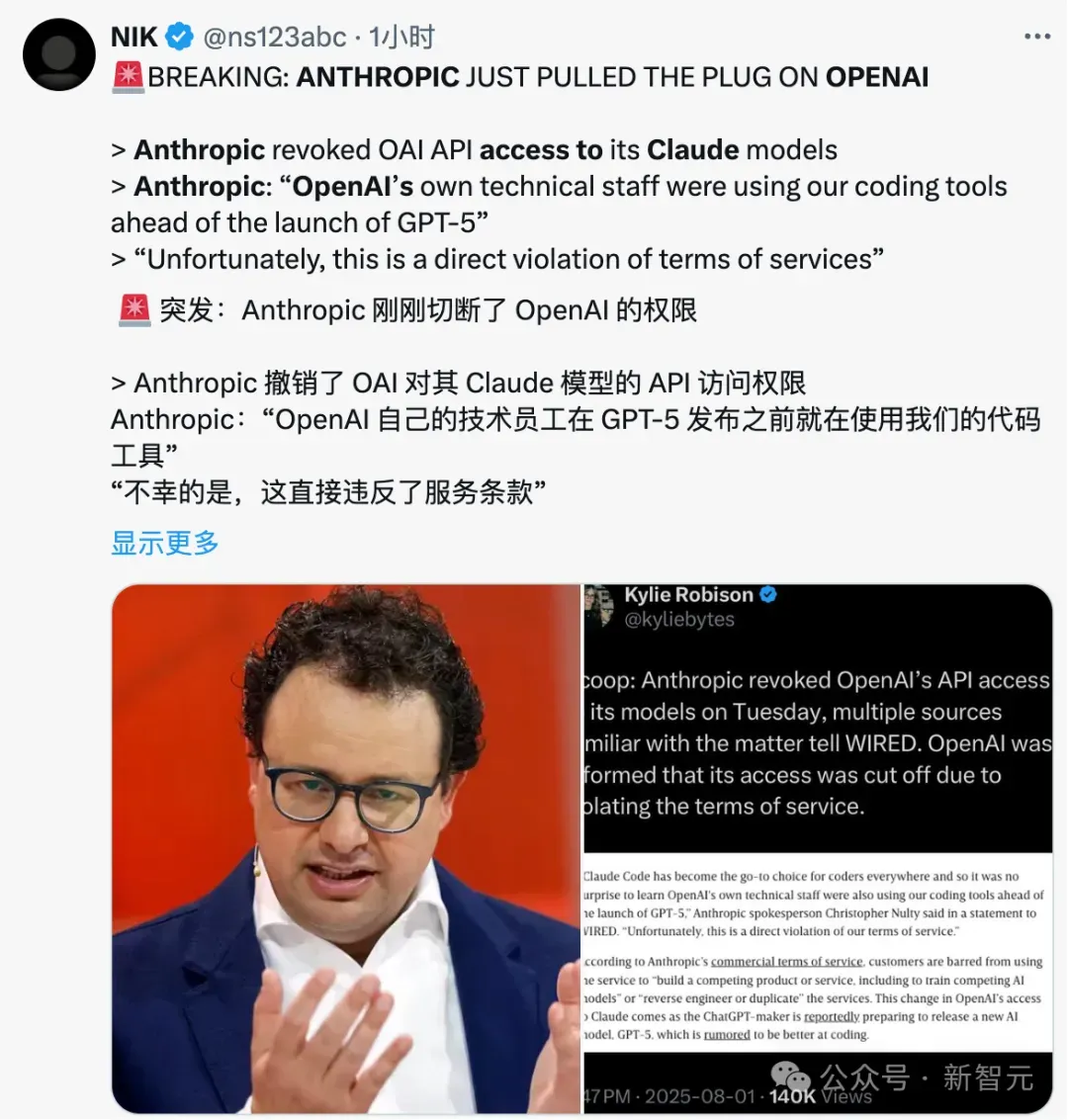
据多位知情人士爆料,Anthropic公司已经切断了OpenAI对其所有大语言模型的API访问权限。

换句话说,OpenAI被老对手Anthropic彻底「拉黑」了。
Anthropic给出的理由简单粗暴:OpenAI公然违约!
Anthropic的发言人Christopher Nulty发表了一份火药味十足的声明:
Claude Code(Anthropic旗下编程工具)现在是全世界程序员的必备神器。
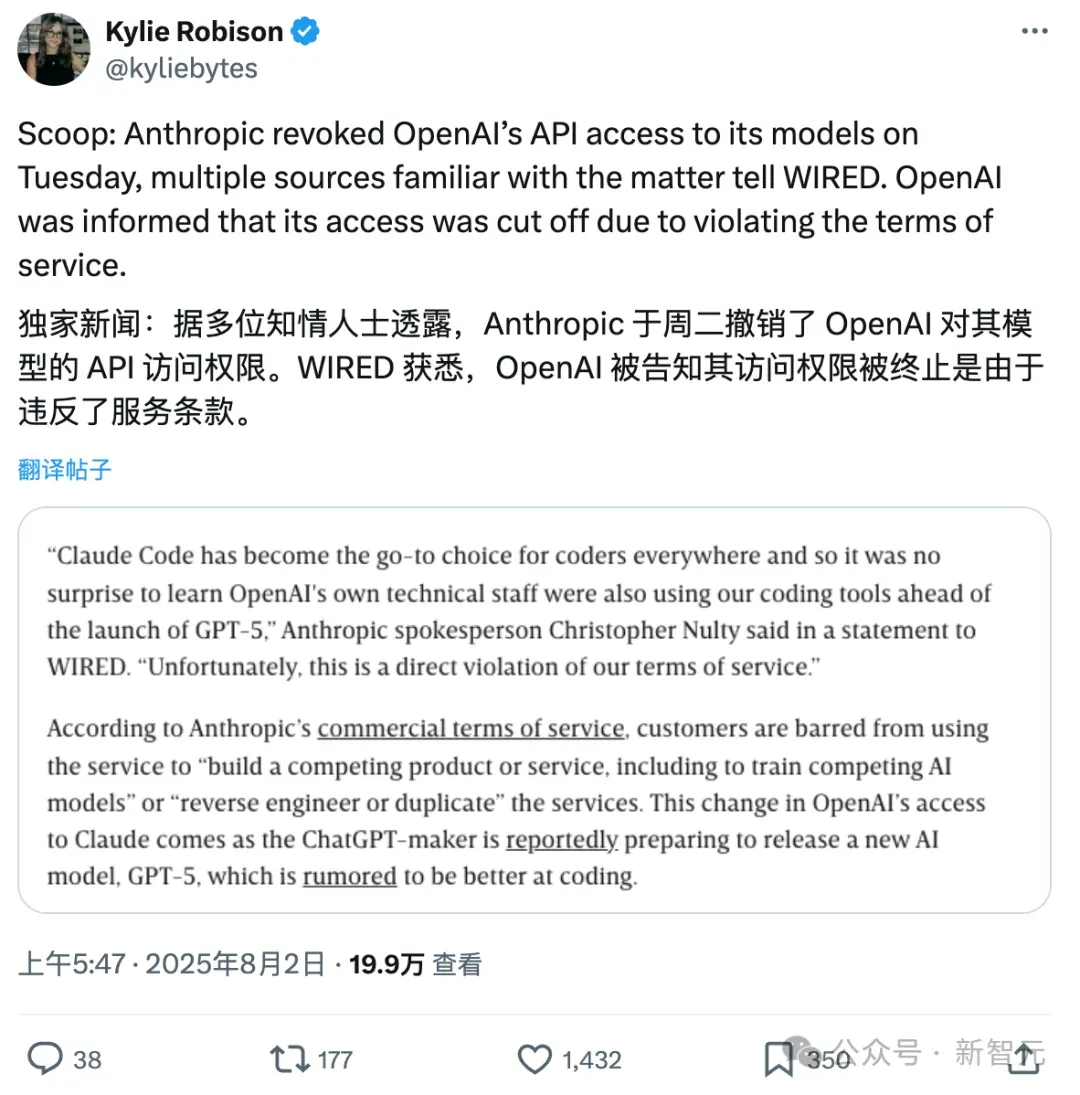
因此当我们得知 OpenAI 自己的技术人员在 GPT-5 发布之前也在使用我们的编程工具时,并不感到意外。
「但很不幸,这种行为严重违反了我们的服务条款。」
根据Anthropic的商业条款,任何客户都不得利用其服务「构建与之竞争的产品或服务,包括训练竞争性AI模型」,更不用说「逆向工程或复制」其服务了。

而这次封杀事件的背景,正值山雨欲来风满楼之际——据传,OpenAI即将发布革命性的新模型GPT-5,其最核心的卖点之一,就是超强的编程能力。
所以,正值OpenAI准备推出传闻中的 GPT‑5(据称具备更强编码能力及安全特性),Anthropic的控制API策略似乎是一次涉及竞争与安全定位的主动防御。
对于OpenAI来说,一边想靠新模型颠覆世界,一边却在「偷师」最强对手?这戏码太炸裂了!

那么,OpenAI到底在用Claude做什么?
据透露,OpenAI并非像普通用户那样使用API随便「聊聊」而已。
而是利用特殊的开发者权限(API),将Claude深度集成到了自己的内部工具中。
他们这样做的目的主要有两点:
- 摸底对手:系统性地评估Claude在编程、创意写作等方面的真实能力,与自家的AI模型进行全方位对标。
- 安全「红蓝对抗」:用各种刁钻、危险的提示词测试Claude的「底线」,比如涉及CSAM、自残、诽谤等话题,观察其反应,从而帮助OpenAI评估和调整自家模型的安全护栏。
面对突如其来的封杀,OpenAI显得既震惊又失望。

OpenAI首席沟通官Hannah Wong回应道:
通过评估其他AI系统来衡量自身进步、提升安全水平,这早已是行业惯例。
我们尊重Anthropic的决定,但说实话,这太令人失望了。
别忘了,我们自己的API可一直对他们开放着呢。
这番回应,潜台词就是:我们对你开放,你却对我们关门?太不厚道了!
有趣的是,Anthropic发言人Nulty随后又表示,公司将「继续确保OpenAI拥有用于基准测试和安全评估的API访问权限」,因为这是「行业标准」。
但这番表态与当前的封禁行为自相矛盾,Anthropic并未就此作出进一步解释。
科技巨头的「常规武器」
在科技圈,利用API接口扼杀竞争对手,早已是常规武器。
- Facebook曾对Twitter旗下的短视频应用Vine做过同样的事,并因此引发了反垄断调查。
- 就在上个月,Salesforce也限制了竞争对手通过Slack API访问其数据。
这甚至不是Anthropic第一次「拔网线」。
上个月,当传出OpenAI可能收购AI编程新贵Windsurf的消息后,Anthropic迅速切断了Windsurf对Claude的直接访问权限。(当然,那笔收购最后也黄了。)
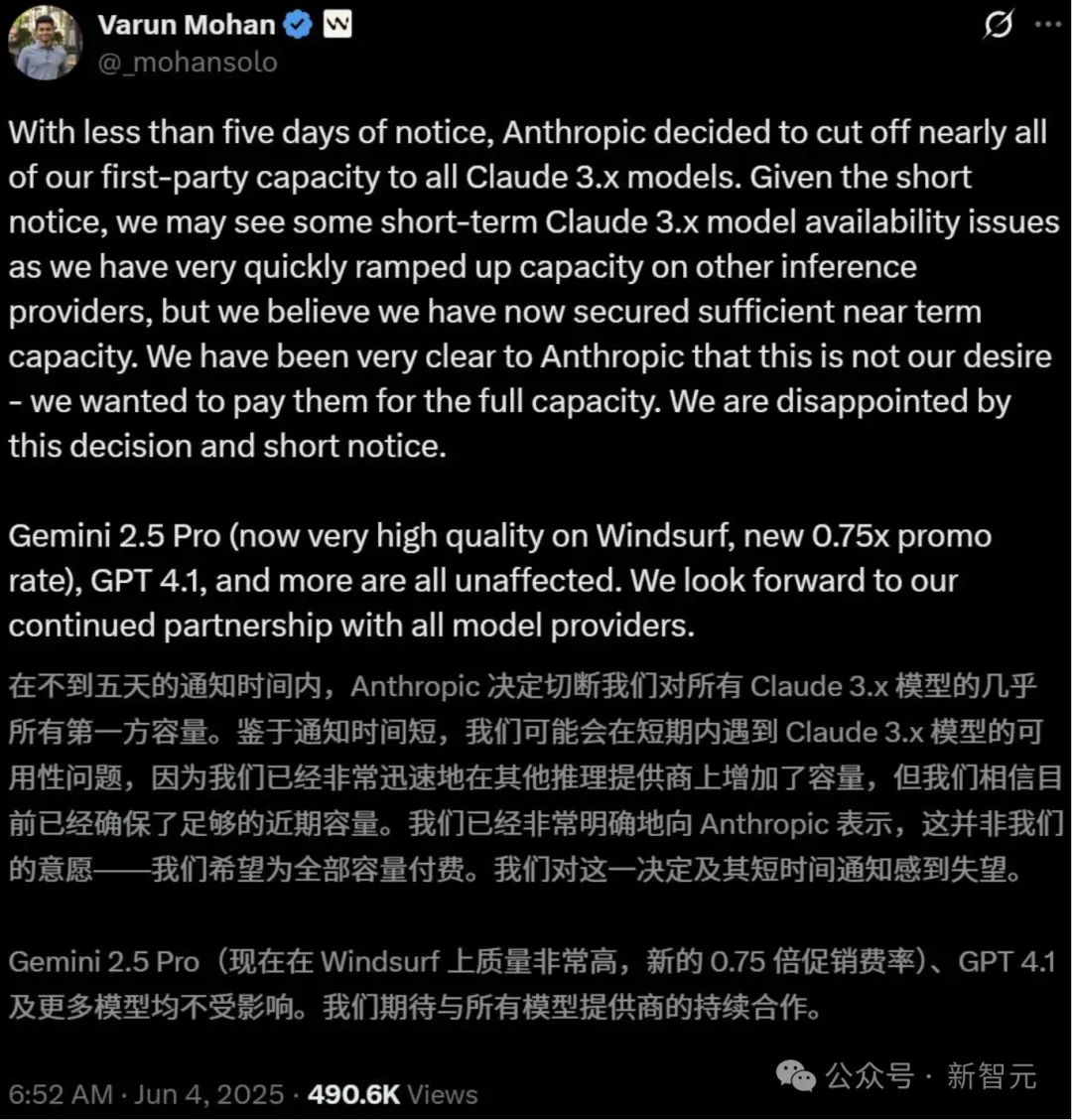
Anthropic表示他们只愿支持「长期合作伙伴」。
当时,Anthropic的首席科学家Jared Kaplan就对媒体直言不讳:「把我们当家的Claude卖给OpenAI?这事儿想想都觉得奇怪。」
关于此次争斗,有人表示,开源才是唯一解决方案。
甚至有人调侃,「GPT-5,但是由Claude Code出品」。
而就在这次封杀OpenAI的前一天,Anthropic刚刚宣布,由于用户量「爆炸式增长」以及部分用户违反服务条款,将对Claude Code实行新的使用频率限制。
Anthropic此番「拔网线」动作不仅是一场针对OpenAI的「战术打击」,更折射出AI竞争进入「数据与接口封锁」阶段。
对开发者、创业公司乃至监管机构而言,API不再只是技术细节,而是关乎市场准入与创新自由的战略资源。
一切早有预兆,这场AI王座的战争,已经彻底白热化了!


