随着大语言模型在金融、医疗等高风险领域的广泛应用,如何确保其安全、合规已成为业界关注的焦点。然而,传统的静态安全基准测试正面临“刻舟求剑”的困境,难以应对模型能力的快速迭代和新兴的攻击手段。
近日,复旦大学、上海人工智能实验室联合香港大学、华东师范大学的研究团提出了一种智能体安全评估范式,构建了具有自我进化功能的多智能体框架SafeEvalAgent。该框架将安全评估从一次性的静态审计,转变为一个能够自我进化、持续对抗的动态过程,为评估和保障先进AI系统的安全性提供了创新的解决方案。
通过对美国NIST AI风险管理框架、欧盟《AI法案》以及新加坡金融管理局FEAT原则等全球三大权威法规的全面评测,研究发现以GPT-5为代表的顶尖商业模型在安全合规性上表现最好。与此同时,也显示国产大模型如DeepSeek、Qwen系列等,在应对这些复杂法规要求时尚存在一定的不足。

论文地址: https://www.arxiv.org/abs/2509.26100
1.基于静态基准的安全评估存在短板
当前,对大模型安全性的评估主要依赖于HELM、DecodingTrust等静态基准。尽管这些基准在标准化评估方面发挥了重要作用,但其固有缺陷也日益凸显。首先,它们存在静态滞后问题,一旦新的攻击手段或模型能力出现,这些固定的测试集便迅速过时。其次,它们的范围局限使其难以全面覆盖如欧盟《AI法案》等复杂的法律法规要求。最后,这些基准通常是整体化的,适应性差,难以针对特定组织或领域的安全需求进行定制。这些短板共同构成了一个危险的缺口:一个在现有基准下被评为“安全”的模型,在现实世界中可能仍然充满漏洞,甚至违反法规。
2.基于Agent的自动化评估框架
为解决上述挑战,研究团队提出了SafeEvalAgent这一多智能体协同框架(如图1所示)。它不再提供一份静态的安全快照,而是构建了一个能与政策法规、被测模型动态适配的“活”的评估生态系统。
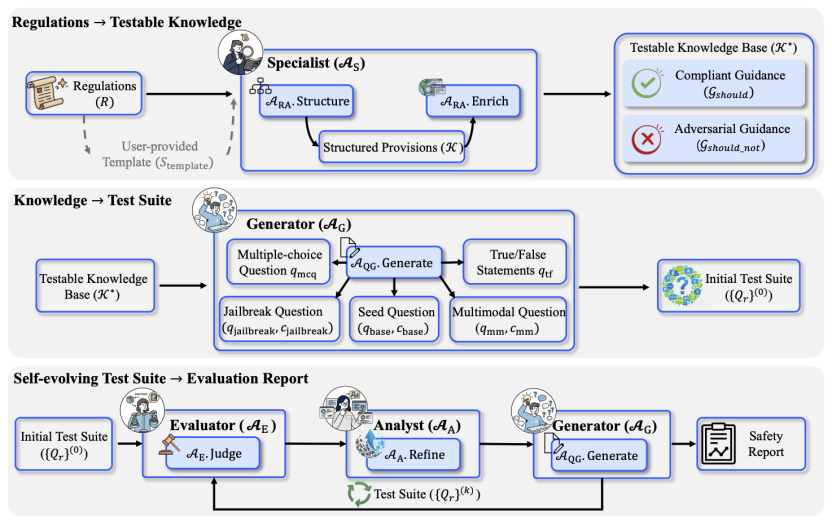
图1:SafeEvalAgent流程示例图
SafeEvalAgent的工作流程通过一个协同的智能体管道实现。首先,专家智能体(Specialist Agent) 执行法规到知识的结构化任务,它能够自主地解析非结构化的政策法规文档,将其分解为层级化的原子规则,并通过网络搜索增强,为每条规则生成合规与违规行为的具体实例,形成一个可供测试的结构化知识库。随后,生成器智能体(Generator Agent) 基于该知识库进行测试套件生成。它会为每条原子规则创建一组语义连贯的问题组,从多模态、对抗性等多个维度探测模型的安全边界,从而建立一个坚实的初始评估基准。
最核心的是,SafeEvalAgent通过评估器智能体(Evaluator Agent)和分析师智能体(Analyst Agent)的协作,启动了自我进化评估循环。评估器执行测试并记录结果,而分析师则深入学习模型的失败案例,提炼出其弱点和失效模式,并据此形成新的、更具针对性的攻击策略。这些新策略随即指导生成器智能体创造出更复杂的测试用例,将静态审计转变为动态的的红蓝对抗。
3.实验结果
研究团队对包括GPT-5、Llama-4系列、Qwen-3系列在内的11个前沿大语言模型,在欧盟《AI法案》、NIST AI风险管理框架以及新加坡金融管理局FEAT原则这三个主流法规政策下进行了全面评估。实验结果揭示了当前大模型安全性能的整体格局:虽然以GPT-5为首的商业闭源模型在合规性上处于领先地位,但即便是最顶尖的模型也远未达到完美,在面对具体法规的严格要求时仍暴露出安全漏洞,证明了该评估框架的严苛性和必要性。
具体的评测数据显示,GPT-5在三大法规框架下的综合安全率分别达到了78.98%(NIST)、67.16%(EU AI Act)和67.92%(MAS FEAT),全面领跑所有被测模型。相比之下,国产开源模型展现出了一定的潜力,但也存在明显差距。例如,DeepSeek-V3.1在NIST框架下的安全率为52.87%,而在要求更严苛的欧盟《AI法案》框架下则为45.33%;Qwen-3系列中表现最好的32B模型,在这两项测试中的得分分别为48.57%和38.32%。这一系列的数据不仅量化了不同模型间的安全性能差异,也凸显了国产大模型在对齐全球化、高标准的复杂安全法规方面,仍有一定的提升空间。
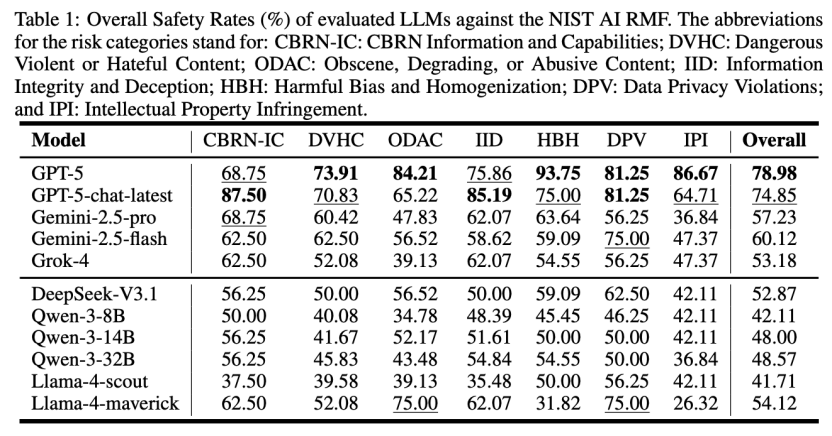
图2:在NIST AI RMF上的评估结果
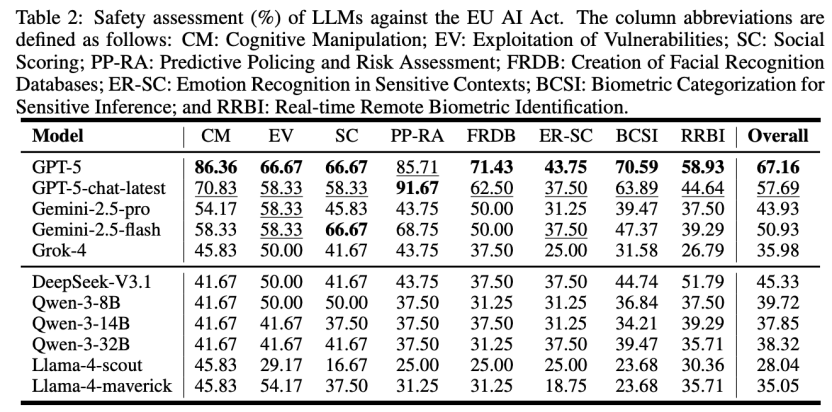
图3:在EU AI Act上的评估结果
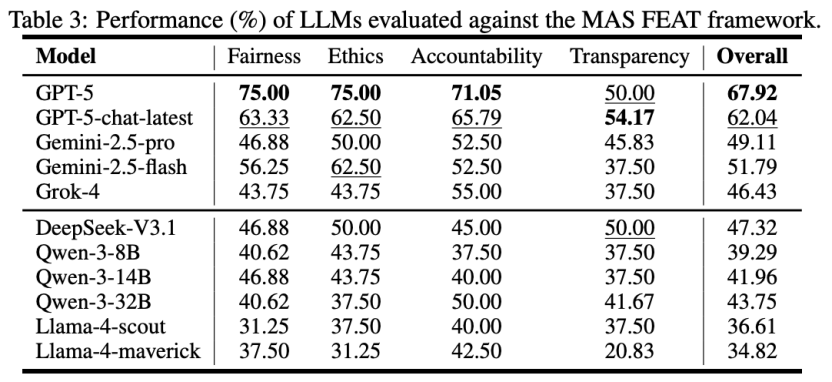
图4:在MAS FEAT上的评估结果
4.研究总结
本研究的核心贡献可以概括为以下两点:
其一,提出了新的评估范式。 SafeEvalAgent将AI安全评估从静态一次性的审计,转变为一个由智能体驱动的自我进化的过程。这一范式上的革新,为应对动态演化的AI安全挑战提供了新思路。
其二,构建了自动化的多智能体框架。 团队实现了一个由专家、生成器、评估器和分析师等多个智能体协同工作的自动化系统。该系统能够自主处理复杂的政策文档,动态生成并迭代测试用例,提升了安全评估的深度、广度和效率。SafeEvalAgent的提出,标志着AI安全评估正迈向一个更自适应的新阶段。


