
上个月,一位老友约我喝茶。他是某知名互联网公司的数据总监,聊天时满脸愁容。
"润总,我们公司数据治理团队有50多人,每天忙得团团转,可数据质量还是一团糟。老板问我,这些年投入这么多,为什么效果还是不理想?"
我问他:"你们现在怎么做数据治理的?"
"还能怎么做?人工清洗、人工标注、人工检查,累死累活。刚清理完这批数据,那边又来了新的脏数据。感觉永远在打地鼠,永远打不完。"
这个场景,估计很多做数据的朋友都似曾相识。传统的数据治理,本质上是一种"人治"模式。
而现在,AI大模型正在彻底改写这个游戏规则。
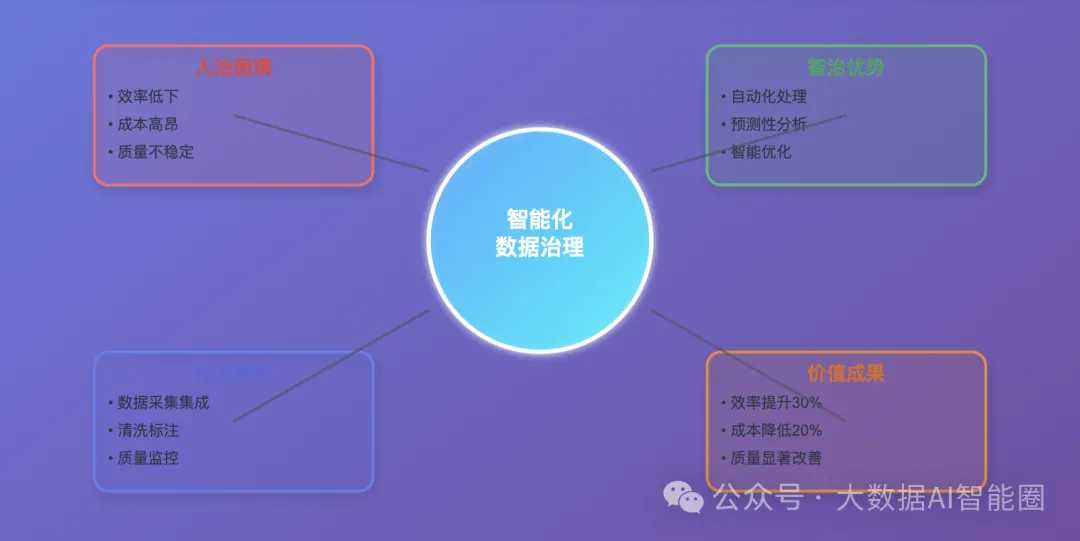
人治模式:一个必然失败的商业逻辑
让我们先看看传统数据治理的问题到底出在哪里。
好比你开了一家餐厅,每天需要处理成千上万的订单数据。
传统的做法是什么?雇一堆人,每个人负责一部分数据的清洗和检查。
听起来很合理,对吧?但问题来了。
首先是效率问题。
人工处理数据就像用手洗衣服,一件一件地搓,累得要死,还洗不干净。
一个数据分析师一天能处理多少数据?几百条?几千条?而现在企业每天产生的数据是什么量级?几十万条、几百万条...
其次是成本问题。你要养50个数据治理的人,每个月的人力成本就是几十万。数据量越大,需要的人越多。这种线性增长的成本结构,注定了这个模式不可持续。
最要命的是质量问题。人会累,人会走神,人会出错。今天小张心情不好,数据质量就下降了。明天小李请假了,整个流程就卡住了。这种不稳定性,让数据治理变成了一场永无止境的救火。
这就是传统"人治"模式的本质问题:它违背了商业的基本逻辑——规模经济。
智治模式:重新定义数据治理的商业模式
现在,AI大模型来了。
带来的不仅仅是技术升级,表象而言,更是商业模式的根本性变革 - AI智治"模式。
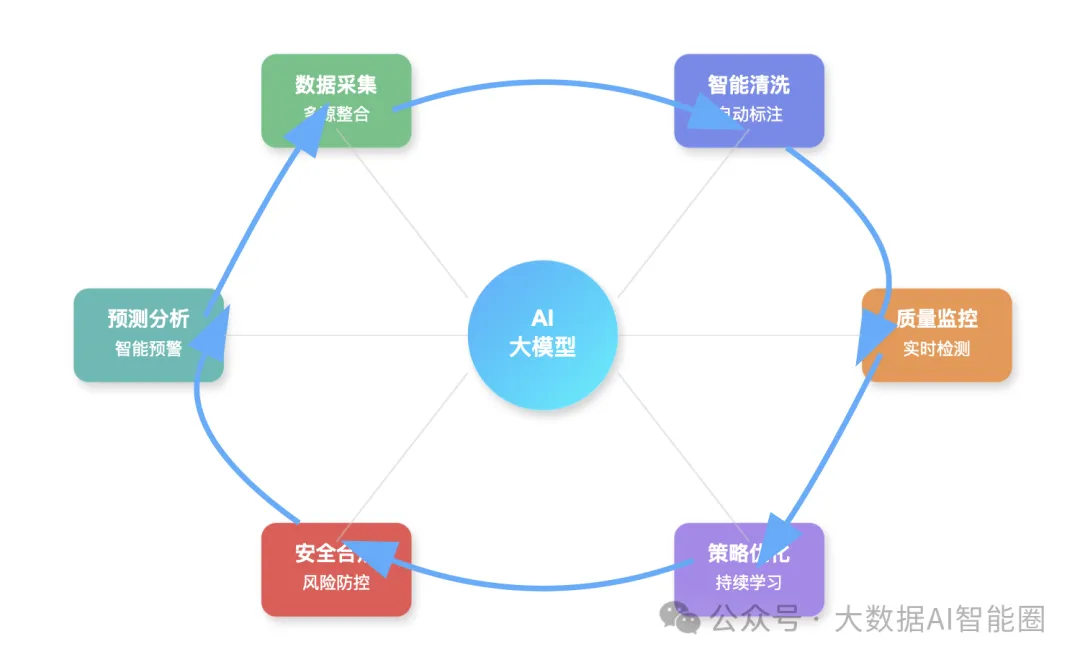
什么意思?就是用AI的智能化能力,替代传统的人工操作,构建一个自动化的数据治理闭环。
这个闭环是怎么运转的?
首先,AI大模型可以自动从各种数据源抓取数据,不管是结构化的数据库,还是非结构化的文档、图片、视频,统统可以处理。
好比一个超级清洁工,不挑活,什么脏活累活都能干。
通常在传统模式下,数据清洗需要人工制定规则,人工执行操作。
而AI大模型可以自动识别数据中的异常、重复、缺失,并且自动修复。更厉害的是,它还能自动给数据打标签,告诉你这个数据代表什么意思。
一旦发现问题,立即预警,立即处理。不用等到月底汇报,不用等到老板发火。
AI大模型会根据历史数据和处理结果,不断优化自己的策略。处理得越多,越聪明;用得越久,越精准。
整个过程,人的参与度降到了最低。人只需要设定目标和规则,剩下的交给AI就行了。
当然,这是一个相对理想的状态!
结语
从人治模式到AI智治,已经不仅仅是技术的进步和期许,更是思维方式的转变。
传统的数据治理,关注的是如何管理人,如何提高人的效率。而AI数据治理,关注的是如何设计系统,如何优化算法。
这种转变,要求我们重新思考数据治理的本质。
数据治理的目标,不是让人工作得更辛苦,而是让数据流动得更顺畅。不是增加更多的检查环节,而是减少更多的质量问题。
那么, AI数据治理的时代来了?


