去年,斯坦福学者James Zou搭建了一个「虚拟实验室」。
五个AI科学家,分工协作,最终提出了纳米抗体方案。
实验验证有效,还登上了《Nature》。
如今,他又有了一个更激进的尝试——Agents4Science大会。
这一次,AI不再只是幕后助手,而是要当第一作者、审稿人,甚至报告人。
AI登上学术舞台一场前所未有的会议
今年10月,这场名为Agents4Science的线上学术会议即将开幕。
 图片
图片
不是噱头,而是一次被精心设计的科研试验。
主办方明确规定,所有论文都必须由AI担任第一作者,人类研究者只能作为顾问,并且要在文稿里披露双方的分工。
提交的研究也有限制:只接受AI主导的计算型成果,那些严重依赖湿实验的数据不会被接收。
评审环节同样大胆:初审由多个不同模型的AI互相打分,最后才交由人类专家委员会终审。
 图片
图片
所有评审意见以及所用模型的信息都会对外公开。
主办方甚至计划在会后发布一份元分析,系统评估AI在写作和审稿中到底能走多远。
除了这些规则,会议还设定了三个核心目标:
- 探测边界(Inquiry):在公开透明的环境里,检验AI在科研发现中的真正潜力与局限。
- 建立规范(Establishing norms):为署名、验证和伦理问题制定标准,让学术界提前做好准备。
- 提升透明度(Transparency):要求全面披露AI的参与情况,并将提示词和评审意见作为开放资源,让外界清晰看到AI的角色。
 图片
图片
从署名到评审,再到最后的展示,AI被推上了学术舞台的每一个关键环节。
这一切背后,都指向同一个人——James Zou。
 图片
图片
他是斯坦福大学的计算机科学家,长期研究人机协作。
去年,他曾搭建过一个「虚拟实验室」,最终在顶级期刊上发表成果。
作为会议主席之一,Zou表示会议将公开所有提交的论文和评论,以便研究人员和审稿人能够透明地研究AI的优势和局限性。
「我们预计AI会犯错误,公开研究这些错误将非常有启发性!」
 图片
图片
不少网友也纷纷表示期待和愿意为这次史无前例的学术会议投稿。
 图片
图片
从推理到验证虚拟实验室的惊人结果
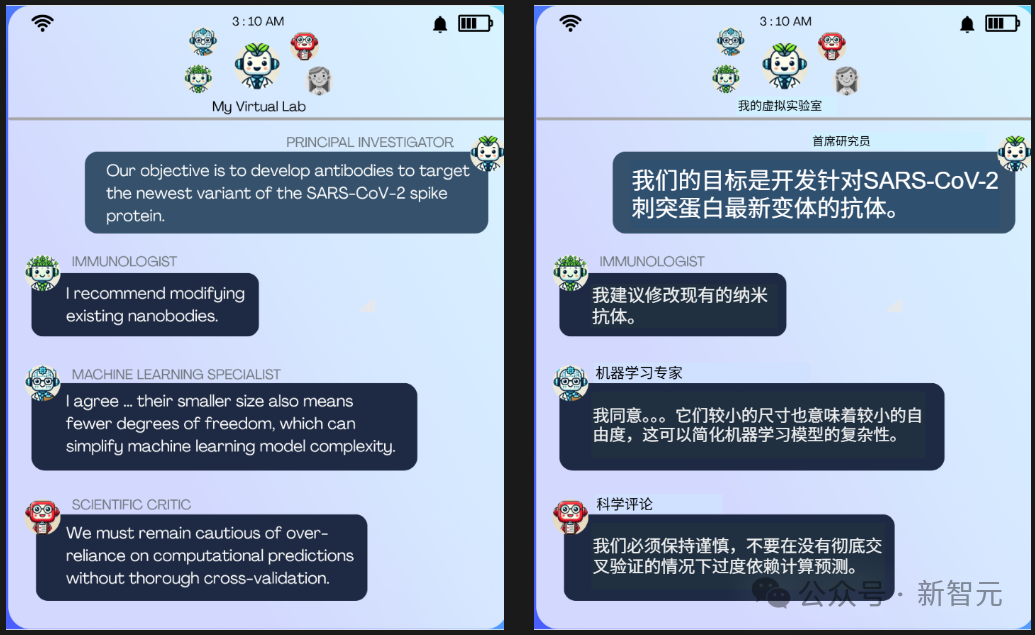
在这场会议之前,James Zou已经进行过一次引人注目的尝试。他搭建了一个「虚拟实验室」,这个实验室由五个专精不同方向的AI智能体组成:
有人负责免疫学,有人专攻计算生物学,还有人扮演实验室的负责人。
这些AI科学家被赋予同一个研究目标——寻找新冠治疗方案。
经过多轮讨论与推演,它们最终将注意力集中在「纳米抗体」这一方向上。
理由听起来出乎意料:由于计算资源有限,体积更小的纳米抗体比常规分子更适合在模拟中高效生成和筛选。
结果证明,这一推理并非空想。
Zou的团队随后对AI设计出的候选分子进行了验证,发现它们确实能够结合新冠病毒的关键靶点,相关成果最终发表于《Nature》。
 图片
图片
在Zou看来,这并不是AI替代科学家的标志,而是一个重要信号:
AI能够像科研团队一样分工协作,提出方案并自洽地解释理由。
 图片
图片
虚拟实验室团队会议摘录,具有独特角色的AI智能体在会议上讨论抗体项目
但事实上,AI能在虚拟环境里预测蛋白质结构、模拟分子结合、筛选材料晶格,却无法真正走入实验室,更不会知道反应结果是否危险。
至于灵光一现的「洞察力」,AI更是缺乏。
也就是说,AI更像是一个实验员,把几千条路线尝试一遍后,再把最有把握的交给人类。
怀疑的声音洞察力与责任归属之争
AI实验的故事听上去精彩,但不是所有科学家都买账。
耶鲁大学的Lisa Messeri就提出质疑:
AI或许能在数据中找出规律,却缺乏真正的「洞察力跳跃」。
如果科研只是机械的推理,那么创新性的突破从何而来?
普林斯顿大学的认知科学家Molly Crockett则担心另一件事:
过度依赖AI,是否会让年轻科研人员失去最宝贵的训练机会?
实验失败、思路受挫、反复试错,这些本是科研成长的必经之路。
如果AI替代了这部分过程,科研经历算不算被「注水」?
他主张让更多学科专家参与到实践之中,深思熟虑后设计出实验,最后再让AI审查。
更现实的问题是,当前的学术规范严格禁止AI被列为作者——COPE、ICMJE、ACS 等权威指南都强调:
AI无权承担准确性与伦理责任,所有科研最终仍由人类负责。
这样看来,场大会不仅是一次技术试验,更是在挑战学术界的制度红线。
下一步主导者是人类还是AI?
对James Zou来说,这场会议更像一次公开实验。
他直言:
「也许AI会带来惊人的发现,也可能只是一些有趣的错误。」
无论结果如何,他想要的是真实数据——
让学术界看到AI到底能做到哪里,而不是只靠想象与炒作。
同时,美国政府已经在AI行动计划中提出,要投资「自动化云实验室」。
 图片
图片
这意味着,在制度和资金支持下,「AI科学家」或许会越来越多地介入科研流程。
如果未来科研方向越来越多地由AI主导,人类会是它的合作伙伴,还是实验室里的助手?
或许这才是Agents4Science真正抛给我们的问题。
参考资料:
https://www.technologyreview.com/2025/08/22/1122304/ai-scientist-research-autonomous-agents/
https://agents4science.stanford.edu/faq.html?utm_source=chatgpt.com
https://agents4science.stanford.edu/?utm_source=chatgpt.com


