Phantom 是一个统一的视频生成框架,适用于单主题和多主题参考,基于现有的文本转视频和图像转视频架构构建。它通过重新设计联合文本-图像注入模型,利用文本-图像-视频三元组数据实现跨模态对齐。此外,它在人物生成中强调主题一致性,同时增强了身份保留视频生成。

相关链接
- 论文:https://arxiv.org/abs/2502.11079
- 代码:https://github.com/Phantom-video/Phantom
- 主页:https://phantom-video.github.io/Phantom/
- ComfyUI:https://github.com/kijai/ComfyUI-WanVideoWrapper/tree/dev
身份保护视频生成
使用面部参考图像生成主体视频。Phantom严格保留参考面部的身份,同时根据提供的提示生成生动的视频。

单参考主题到视频生成
使用单个参考图像生成主体视频。Phantom可以保持各种主体的完整性,包括物体、衣服、动物、虚拟角色等。

多参考主题到视频的生成
使用多个参考图像生成主体视频。Phantom可以实现多个主体之间的逼真互动,例如群体互动、产品演示、虚拟试穿等。

论文介绍
 Phantom:通过跨模态对齐生成主题一致的视频
Phantom:通过跨模态对齐生成主题一致的视频
视频生成基础模型的不断发展演变,并应用于各种应用,而主题一致的视频生成仍处于探索阶段。这类人物称为“主题到视频”(Subject-to-Video),该方法从参考图像中提取主题元素,并按照文本指令生成主题一致的视频。作者认为“主题到视频”的精髓在于平衡文本和图像的双模态提示,从而深度同步地对齐文本和视觉内容。为此论文提出了Phantom,一个适用于单主题和多主题参考的统一视频生成框架。
基于现有的文本到视频和图像到视频架构,作者重新设计了联合文本-图像注入模型,并驱动其通过文本-图像-视频三元组数据学习跨模态对齐。该方法实现了高保真度的主题一致视频生成,同时解决了图像内容泄漏和多主题混淆的问题。评估结果表明,提出的方法优于其他最先进的闭源商业解决方案。特别地,该方法强调人类生成中的主题一致性,这涵盖了现有的身份保留视频生成,同时提供了增强的优势。
方法概述
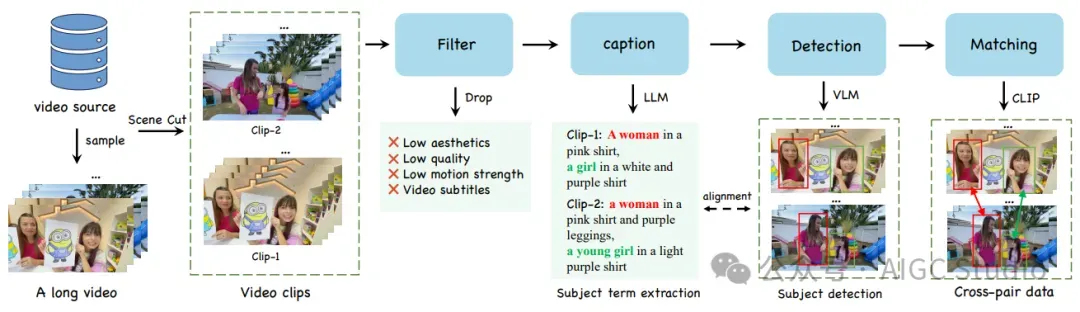 用于跨模态视频生成的数据处理流程。该流程包括过滤、添加字幕、检测和匹配阶段,用于从视频片段中提取主体并将其与文本提示对齐,从而确保视频生成的一致性。
用于跨模态视频生成的数据处理流程。该流程包括过滤、添加字幕、检测和匹配阶段,用于从视频片段中提取主体并将其与文本提示对齐,从而确保视频生成的一致性。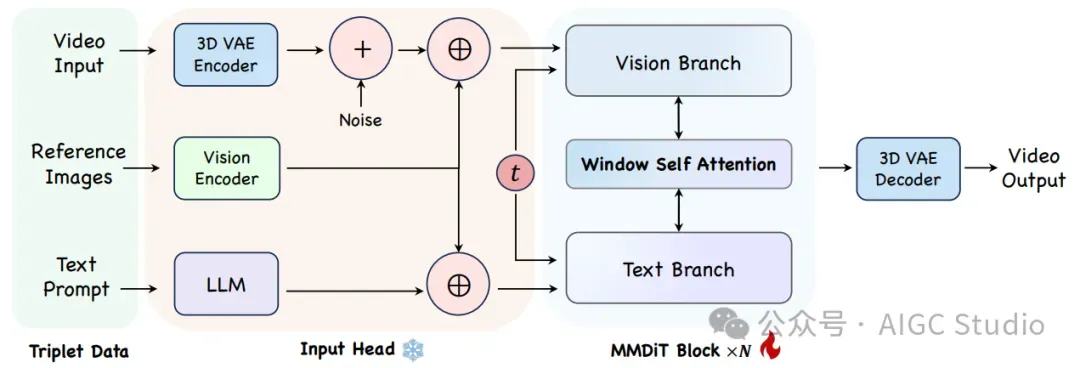 Phantom 架构概述。三元组数据在输入头处被编码到潜在空间,组合后,通过改进的 MMDiT 块进行处理,以学习不同模态的对齐方式。
Phantom 架构概述。三元组数据在输入头处被编码到潜在空间,组合后,通过改进的 MMDiT 块进行处理,以学习不同模态的对齐方式。
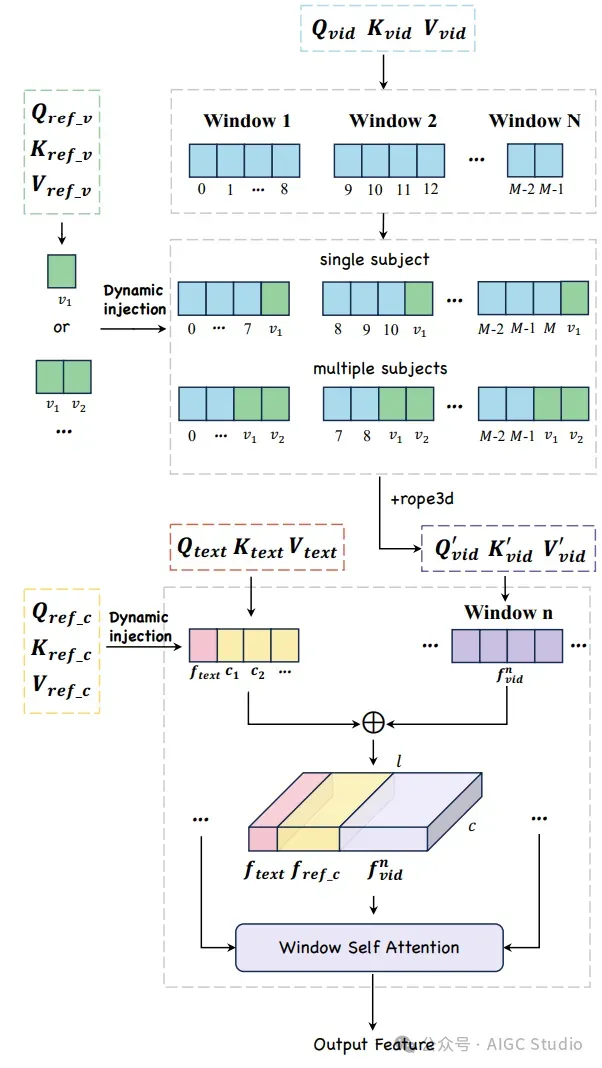
每个 MMDiT 块中针对单个或多个参考对象的动态注入策略和注意力计算
结果展示
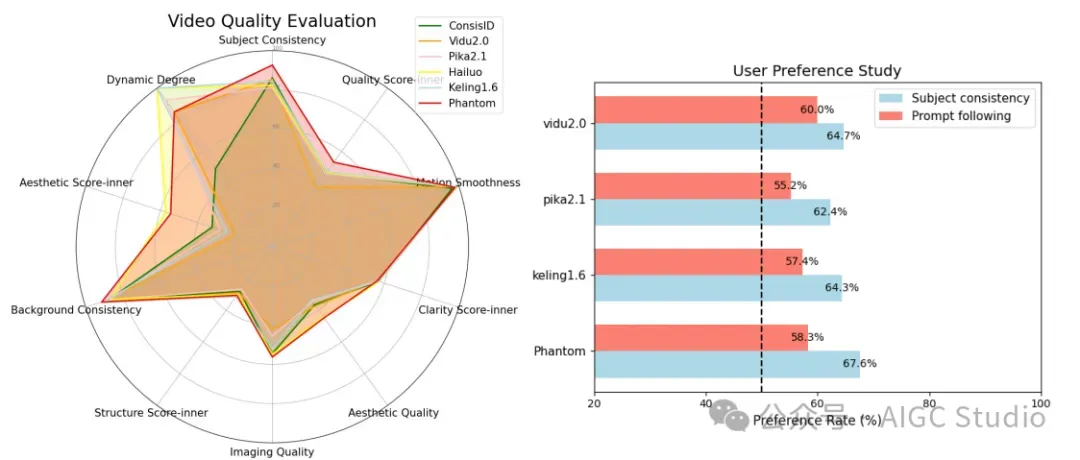 视频质量评估(左)和多主题一致性的用户研究结果(右)。
视频质量评估(左)和多主题一致性的用户研究结果(右)。
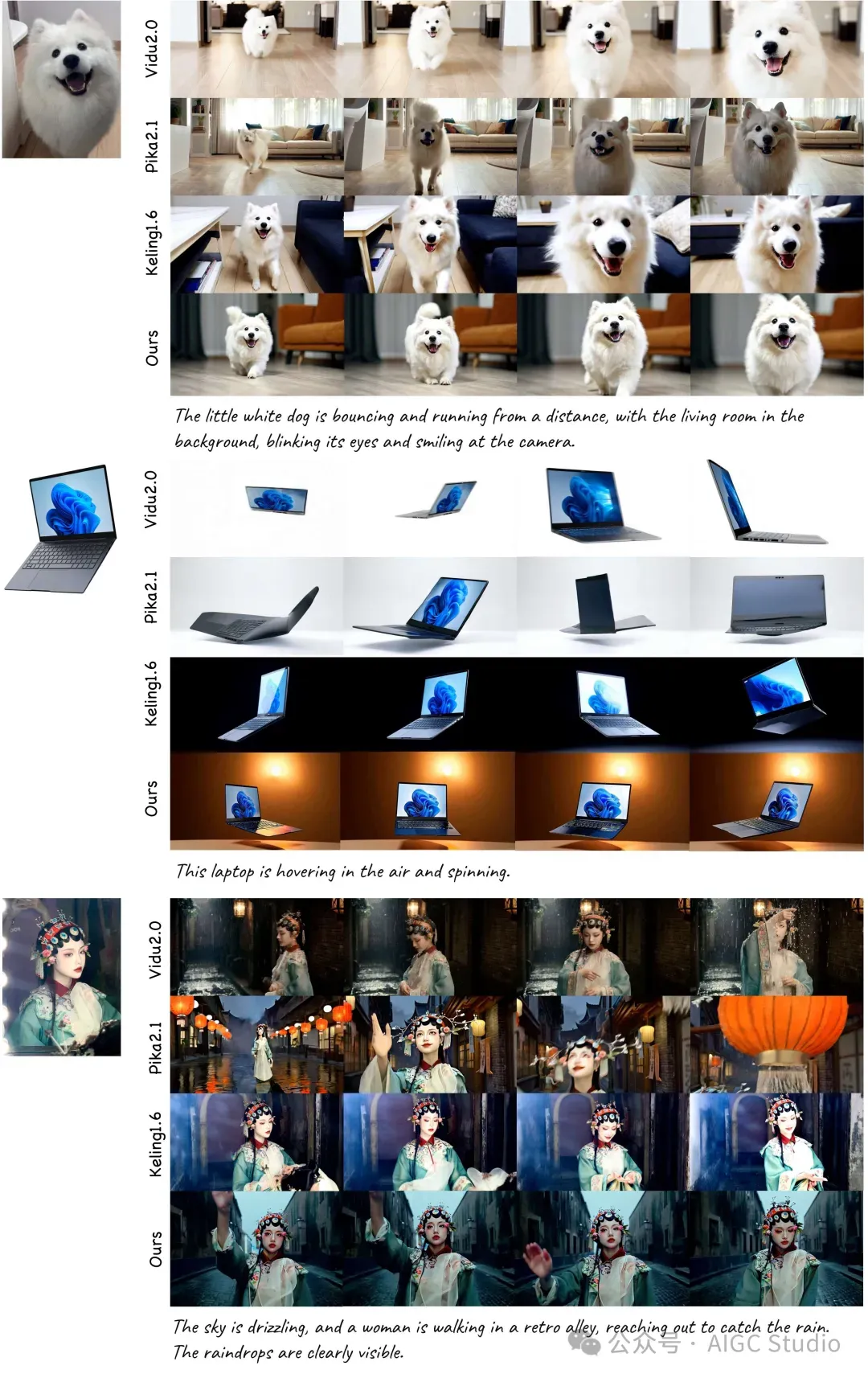
身份保护视频生成

单一参考主题到视频生成
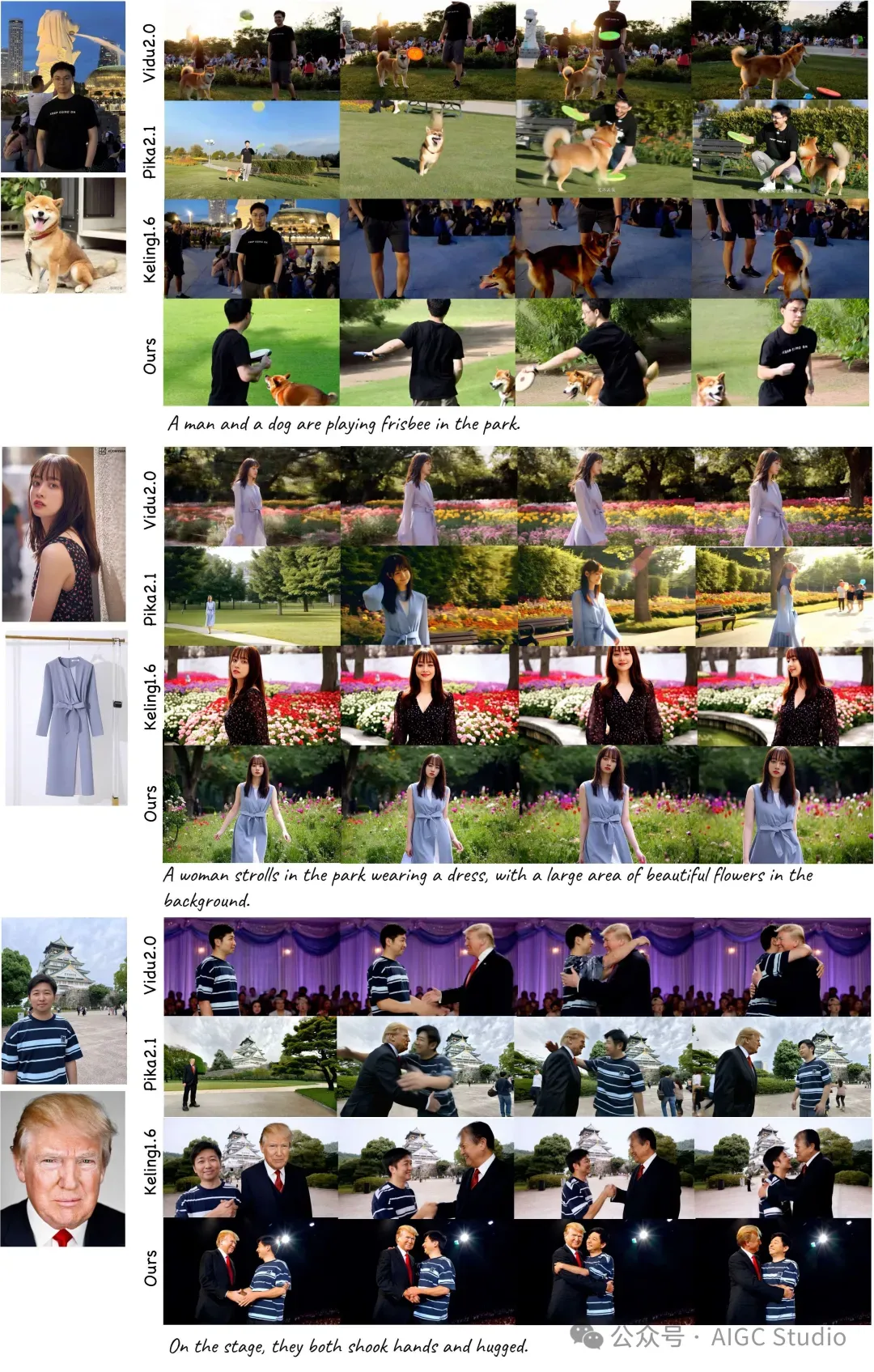
多参考主题到视频生成
结论
Phantom是一种基于文本-图像-视频三元组学习实现跨模态对齐的主体一致性视频生成方法。通过重新设计联合文本-图像注入机制并利用动态特征集成,Phantom 在统一的单/多主体生成和人脸 ID 保存任务中展现出极具竞争力的性能,并在定量评估中超越了商业解决方案。


