你是否曾经问过简单问题,却得到AI长篇大论的回答?或者问复杂问题时,AI却草草了事?今天我要和大家分享一项突破性研究,它让AI学会了"什么时候该思考,什么时候该直接回答"。
 图片
图片
1、AI的思考困境:要不要动脑子?
现代的大语言模型(LLM)已经能够通过"思维链"(Chain-of-Thought,简称CoT)进行复杂推理。简单来说,这种方法让AI像人类一样,先列出解决问题的步骤,再得出最终答案。
但这种方式存在一个明显问题:无论问题简单还是复杂,AI都一律使用详细推理。就像你问朋友"1+1等于几",他却认真地写下:"首先,我们有数字1,然后再加上数字1。根据加法定义,1+1=2。"——这显然太浪费时间了!
这种"过度思考"带来三大弊端:
(1)产生大量冗余token(AI输出的基本单位)
(2)增加内存占用
(3)显著提高计算成本
2、Thinkless:教会AI"适时思考"的利器
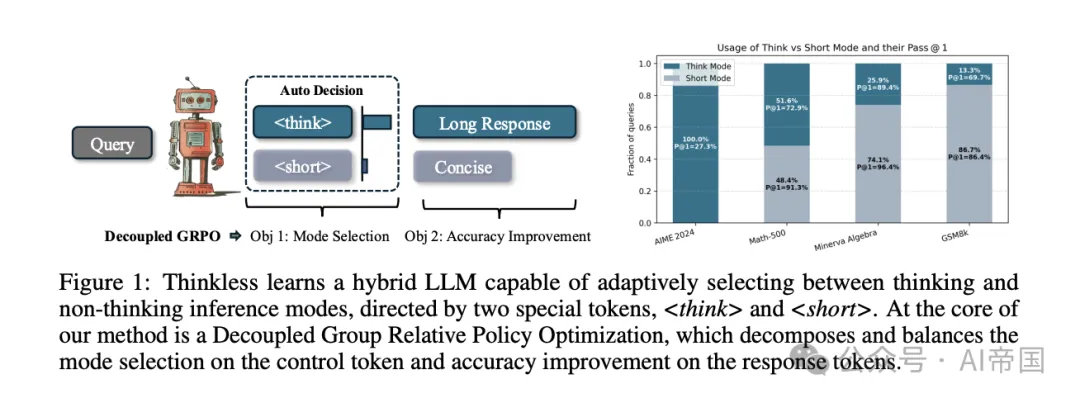
论文提出一个关键问题:AI能否学会根据任务复杂度和自身能力,决定何时该思考?
研究者开发了Thinkless框架,它巧妙地使用两个控制标记:表示简洁回答,表示详细推理。通过强化学习,AI可以自主决定对特定问题使用哪种回答模式。
3、Thinkless是如何工作的?
 图片
图片
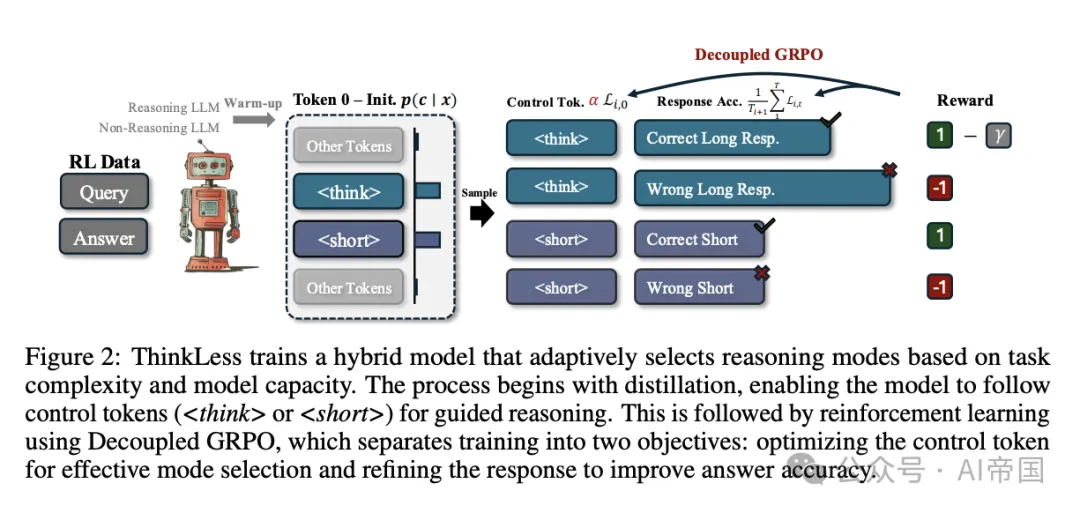
这个框架通过两个阶段训练AI:
(1)热身蒸馏阶段
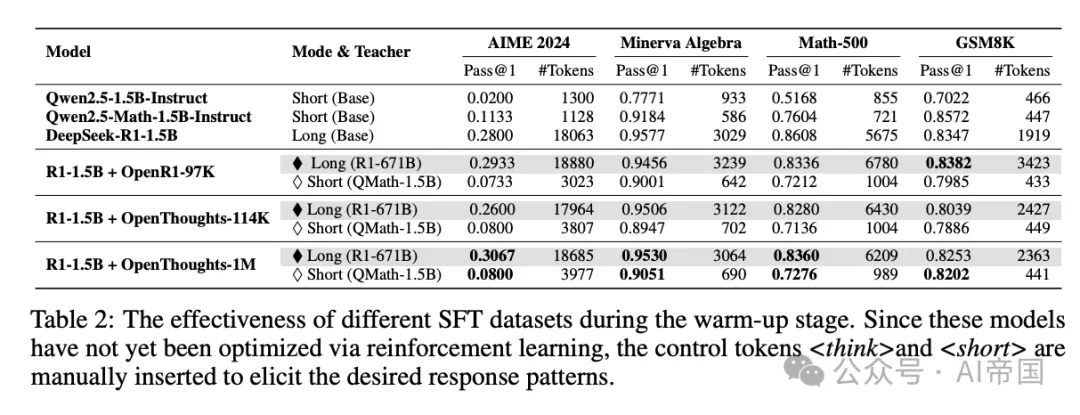
首先,模型从两位"专家"那里学习:一个擅长详细推理的模型和一个擅长简洁回答的模型。这个过程就像一个学生同时向两位风格不同的老师学习,掌握两种回答方式。
这个阶段建立了控制标记和回答格式之间的明确映射,为后续的强化学习提供多样化的输出基础。
(2) 解耦群体相对策略优化(DeGRPO)
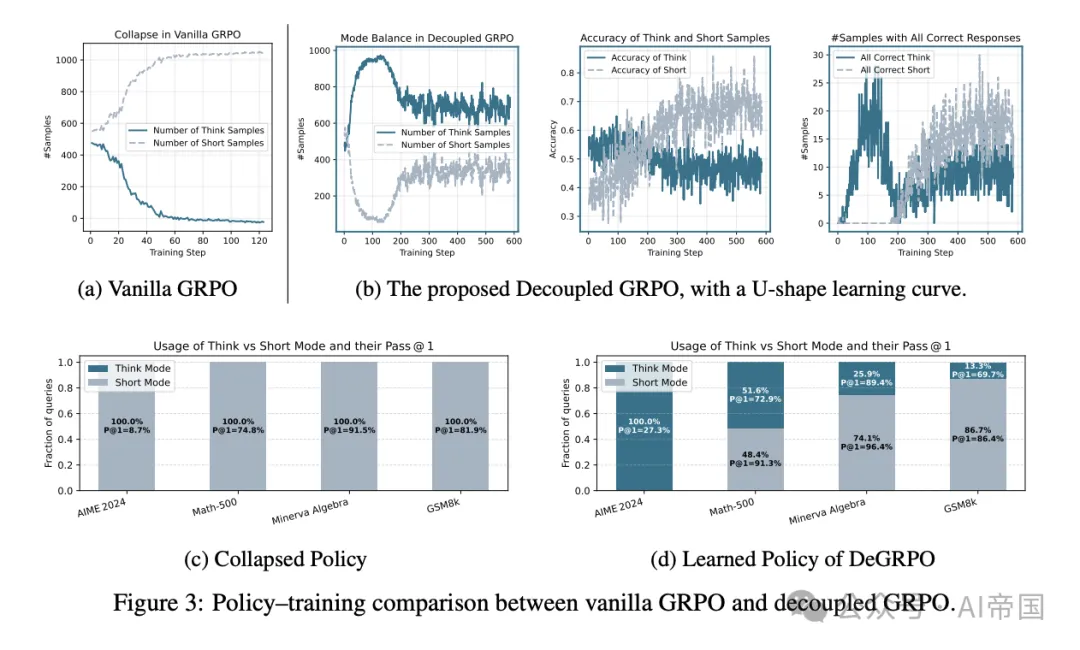
这是Thinkless的核心创新。研究者发现,传统的优化方法会导致"模式崩溃"——模型可能完全倾向于使用其中一种推理模式,失去灵活性。
DeGRPO巧妙地将学习目标分解为两部分:
1)模式选择:控制模型如何根据当前准确率调整策略
2)准确率提升:改进回答内容,提高选定推理模式下的答案正确性
这种解耦设计避免了模式崩溃,使模型能够学习出准确的输出和情境敏感的推理策略。
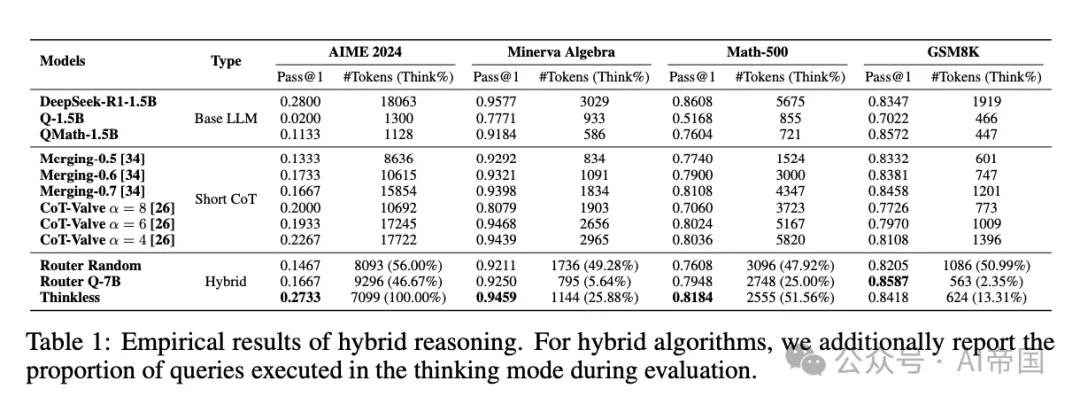
3、效果:节省50%-90%的计算资源
经过训练,Thinkless模型学会了准确识别简单查询,并使用更高效的非思考模式回应。在多个基准测试中,它实现了令人印象深刻的结果:
1)在MATH-500、Minerva Algebra和GSM8K数据集上,长形式推理的使用减少了50%-90%
2)在更具挑战性的AIME任务上,模型自然地采用了更高比例的长形式推理
这意味着AI变得更加"聪明"——它知道什么时候详细思考,什么时候直接回答。这大大降低了推理成本,同时保持了任务性能。
 图片
图片
 图片
图片
 图片
图片
4、结语
研究者在训练过程中发现了一些有趣现象:
U形学习曲线
在训练初期,模型倾向于使用长链推理,因为这种方式通常能带来更高的准确率。但随着训练进行,短链回答的准确率逐渐提高,模型开始更多地探索简短推理的可行性。
这种行为表现为短链输出比例随时间的上升,许多短回答在训练后期达到完美准确率。同时,长链回答的准确率下降,这并非模型推理能力下降,而是因为更多困难问题被分配给了长链模式。
控制标记的权重影响
控制标记的权重决定了模式选择的学习速度。权重过高会导致模型过快更新策略,可能过早将某些样本分配到长链模式,而没有给短模式的性能提升留出足够空间。
实际案例展示
当Thinkless面对不同复杂度的问题时,它如何做出决策?
(1)简单问题:"计算123 + 456" 模式选择:短回答模式() 回答:"579"
(2)中等复杂度问题:"一个球的体积是多少,如果它的表面积是100平方厘米?" 模式选择:取决于模型对自身能力的评估 可能的短回答:"球的体积约为166.67立方厘米"
(3)复杂问题:"证明任意三角形的内角和等于180度" 模式选择:思考模式() 回答:详细的几何证明步骤...
Thinkless研究虽然取得了显著成果,但仍有进一步改进空间:
(1)改进热身阶段:探索更好的混合模型构建策略,如合并技术或轻量级微调方法
(2)扩展到更多领域:目前主要在数学问题上验证,未来可扩展到更广泛的领域
(3)更复杂的决策机制:开发能考虑更多因素的决策系统,如用户偏好、环境约束等
Thinkless研究向我们展示了AI系统中一个重要的思想:不是所有问题都需要同等深度的思考。这一点与人类思维极为相似——我们在日常生活中也会根据问题复杂度调整思考深度。
这项研究不仅大幅提升了AI系统的效率,更向我们揭示了构建更智能、更自然AI系统的方向。未来,AI将更懂得"张弛有度",在需要时深入思考,在可以时直接回答,从而提供更自然、更高效的用户体验。
论文标题:Thinkless: LLM Learns When to Think
论文链接:https://arxiv.org/abs/2505.13379


