
译者 | 朱先忠
审校 | 重楼
简介
模型蒸馏是一种机器学习新技术,其基本思想是让较小的模型(学生)模仿较大的模型(老师)的行为。当前,已经存在几种方法可以实现这一技术(将在下文中展开具体介绍),但其目标都是在学生模型中获得比从头开始训练更好的泛化能力。
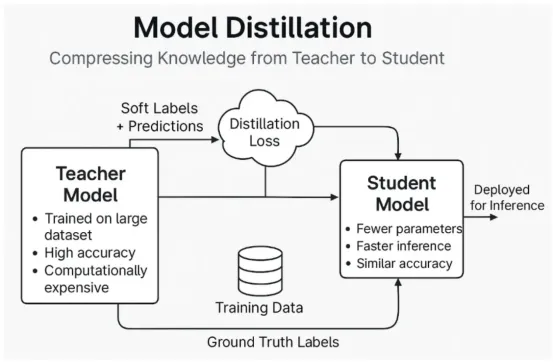
模型蒸馏示例:学生(较小)模型使用蒸馏损失函数从教师模型中学习,该函数使用“软标签”和预测(使用OpenAI GPT4o生成的图表)
一、为什么模型蒸馏很重要?
模型蒸馏是开发和部署大型语言模型(LLM)的关键技术。它解决了与这些模型的大小和复杂性相关的如下几个挑战:
- 资源效率:大型模型(例如具有1750亿个参数的GPT-3)需要大量计算资源进行训练和推理。这使得它们的部署和维护成本高昂。相反地,蒸馏可减小模型大小,从而降低内存使用量并加快推理时间,这对于硬件功能有限的应用程序尤其有益。
- 部署在边缘设备上:许多应用程序需要实时处理和低延迟,尤其是在智能手机或物联网设备等边缘设备上运行的应用程序。精简模型更加轻量,可以部署在此类设备上,从而无需依赖持续的云连接即可实现AI功能。
- 降低成本:由于能耗和专用硬件的需求,运行大型模型的成本很高。通过将模型蒸馏为较小的版本,公司或组织可以显著降低运营费用,同时保持相当的性能水平。
- 提高训练效率:通过蒸馏得到的较小模型需要更少的数据和计算能力来针对特定任务进行微调。这种效率加快了开发周期,使资源有限的研究人员和从业者更容易利用先进的人工智能模型。
为了说明模型蒸馏的影响,请考虑大型模型与其蒸馏模型之间的以下基准比较:

表1:大型语言模型与精简模型(较小)之间的示例比较。注意:这些数字仅供参考,实际性能指标可能因实施和硬件而异
在此示例中,蒸馏模型实现了与GPT-3相当的准确率,同时显著减少了参数数量和推理时间。这证明了蒸馏如何使AI模型在实际应用中更加实用且更具成本效益。
到目前为止,我们已经理解了为什么蒸馏如此重要。现在,让我们更深入地了解模型蒸馏的细节。
二、什么是模型蒸馏?
想象一下,你正在向一位世界级专家(老师)学习一个复杂的主题,比如量子物理学。这位专家无所不知,但他们使用复杂的语言,需要很长时间才能解释清楚。现在再想象一下,另一个人——一位伟大的沟通者(学生)——向这位专家学习,然后以一种更简单、更快捷的方式教你相同的内容,而不会丢失核心信息。这就是模型蒸馏背后的主要思想。
更正式地说,模型蒸馏是一个过程,其中训练一个较小、更高效的模型(称为学生)来复制一个较大、更强大的模型(称为老师)的行为。目标是让学生更快、更轻松,同时在相同的任务上仍然表现良好。
蒸馏类型
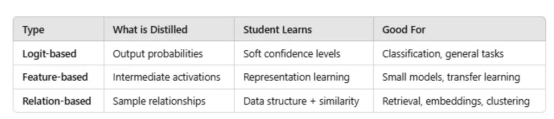
模型蒸馏并不局限于教学生最终的答案是什么。学生可以通过多种方式向老师学习。以下是三种主要类型:
1.基于Logit的蒸馏(软标签):学生模型从老师的概率分布中学习
我们不只是对学生进行正确答案(硬标签)的训练,还让它了解老师对每个答案的信心程度——这些被称为软标签或软目标。
为什么要使用软目标?
假设你正在训练一个模型来对动物进行分类:
- 输入是一张狼的图像。
- 老师输出:
[Wolf: 1.0, Dog: 0.0, Cat: 0.0, Fox: 0.0]
- 学生不仅知道应该说“狼”,还知道狗和狐狸有些相似。这种额外的细微差别有助于学生学习更好的决策界限。
相比之下,仅使用硬标签进行训练将会是这样的:
[Wolf: 1.0, Dog: 0.0, Cat: 0.0, Fox: 0.0]
没有细微差别=更难学习细微的差别。
学生学到了什么:
- 哪些类别可能或不可能
- 老师如何处理不确定性
为什么这种类型很有用:
- 软目标就像一个更平滑的训练信号,特别是对于难以学习的例子
- 鼓励学生更好地概括,而不是仅仅依靠硬标签
这是最常用的方法,尤其是对于分类任务。
2.基于特征的蒸馏:学生模仿老师的中间层表征
学生被训练模仿老师的隐藏层激活,而不仅仅是输出。
你可以将教师模型视为在内部逐步解决复杂问题。在基于特征的蒸馏中,学生模型会尝试复制教师解决问题的方式,而不仅仅是最终答案。
学生学到了什么:
- 内部推理模式
- 输入数据的分层表示
- 嵌入结构和注意力图(在Transformer中)
为什么这种类型很有用:
- 帮助学生学习更丰富的表现形式,尤其是在模型较小的情况下
- 可以提高对新任务的可转移性
- 促进多模式或复杂模型的更好对齐
此类型用于TinyBERT和MobileBERT等蒸馏技术。
3.基于关系的蒸馏:捕获多个实例之间的关系,而不仅仅是实例方面的知识
学生模型不仅从老师的输出中学习,还从老师的表征空间中不同数据样本之间的关系中学习。
基于关系的蒸馏并不关注个别的预测,而是教导学生保留数据的结构——例如,如果老师发现两个句子相似,那么学生也应该学会将它们视为相似。
学生学到了什么:
- 实例之间的相对距离和相似性
- 嵌入空间中的分组、聚类或其他结构知识
为什么这种类型很有用:
- 在度量学习、对比学习或检索任务中尤其有效
- 鼓励学生学习与老师相同的“思维导图”
- 使学生能够适应输入分布的变化
此类型用于更高级或以研究为重点的蒸馏方法(例如,RKD——关系知识蒸馏)。
小结
三、如何进行模型蒸馏(附代码示例)
第1步:加载预训练教师模型
使用Hugging Face的转换器来加载大型模型(例如DistilBERT的老师:BERT)。
复制from transformers import AutoModelForSequenceClassification, AutoTokenizer teacher_model_name = "bert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(teacher_model_name) teacher_model = AutoModelForSequenceClassification.from_pretrained(teacher_model_name)
第2步:从头开始训练学生模型
初始化一个较小的模型,例如:
复制distilbert-base-uncased。 student_model_name = "distilbert-base-uncased" student_model = AutoModelForSequenceClassification.from_pretrained(student_model_name)
第3步:实现知识蒸馏损失
在老师和学生的预测之间使用KL散度。
复制import torch import torch.nn.functional as F def distillation_loss(student_logits, teacher_logits, labels, alpha=0.5, T=2.0): hard_loss = F.cross_entropy(student_logits, labels) soft_loss = F.kl_div( F.log_softmax(student_logits / T, dim=1), F.softmax(teacher_logits / T, dim=1), reductinotallow="batchmean" ) * (T ** 2) return alpha * soft_loss + (1 – alpha) * hard_loss
第4步:使用教师的软目标训练学生模型
复制optimizer = torch.optim.AdamW(student_model.parameters(), lr=5e-5) for batch in train_dataloader: input_ids, attention_mask, labels = batch with torch.no_grad(): teacher_logits = teacher_model(input_ids, attention_mask=attention_mask).logits student_logits = student_model(input_ids, attention_mask=attention_mask).logits loss = distillation_loss(student_logits, teacher_logits, labels) optimizer.zero_grad() loss.backward() optimizer.step()
第5步:评估蒸馏后的模型
比较原始模型和蒸馏模型的准确度和推理时间:
复制import time
def evaluate_model(model, dataloader):
model.eval()
correct, total = 0, 0
start_time = time.time()
with torch.no_grad():
for batch in dataloader:
input_ids, attention_mask, labels = batch
outputs = model(input_ids, attention_mask=attention_mask).logits
predictions = torch.argmax(outputs, dim=1)
correct += (predictions == labels).sum().item()
total += labels.size(0)
inference_time = time.time() - start_time
accuracy = correct / total
return accuracy, inference_time
teacher_acc, teacher_time = evaluate_model(teacher_model, test_dataloader)
student_acc, student_time = evaluate_model(student_model, test_dataloader)
print(f"Teacher Accuracy: {teacher_acc:.4f}, Inference Time: {teacher_time:.2f}s")
print(f"Student Accuracy: {student_acc:.4f}, Inference Time: {student_time:.2f}s")结论
随着大型语言模型不断突破AI的极限,它们也带来了现实的弊端:推理速度慢、能耗高、部署能力有限。模型蒸馏通过将大型模型的功能压缩为更小、更快、更高效的版本,为这些挑战提供了一种实用而优雅的解决方案。
本文中,我们探索了模型蒸馏的缘由、内容和方式——从通过软标签学习到模仿内部表示,甚至保留数据点之间的关系。无论你是为移动应用程序、低延迟API还是边缘设备构建模型,蒸馏都是在不降低性能的情况下缩小模型的关键工具。
蒸馏技术最重要的贡献在哪里?在于这种技术不仅适用于研究实验室或科技巨头。借助Hugging Face Transformers和PyTorch等开源工具,任何人都可以立即开始蒸馏模型。
蒸馏不仅仅是为了让模型更小,而且还为了让它们更智能、更快、更易于访问。随着人工智能从集中式数据中心转移到日常设备和应用程序,蒸馏只会变得越来越重要。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Understanding Model Distillation in Large Language Models (With Code Examples),作者:Edgar


