AI模型开发转向边缘,将高性能计算带到设备端。LLM在边缘面临功耗、可靠性和工业用例挑战,需SLM/VLM、分布式智能体及安全防护,谨慎部署。
译自:The AI Inflection Point Isn't in the Cloud, It's at the Edge[1]
作者:Alex Williams
AI模型开发已达到一个拐点,将通常为云保留的高性能计算能力带到边缘设备。与大型语言模型 (LLLM)[2]及其运行所需的GPU所具有的无所不包的特性相比,这是一个令人耳目一新的视角。
“[在某些时候,你会耗尽计算、电力、能源和金钱[3],” Edge Impulse[4] 的首席执行官兼联合创始人 Zach Shelby 说道,该公司是 Qualcomm Technologies[5] 旗下的一家公司。“我们希望如此广泛地部署生成式AI。它不可扩展,对吗?然后它会遇到许多可靠性问题。它会遇到电力问题。”
在边缘,根据设备的不同,功耗问题也有所差异。然而,结果是什么?这些设备可以运行各种语言模型,但LLM带来了值得注意的挑战。
AI的故事不仅仅关乎大型数据中心。我们需要边缘来运行接近模型处理数据的应用程序。跨国区域到云服务的往返行程成本高昂,并带来各种问题,使实时应用程序无法使用。
工业环境中LLM的挑战和用例
Shelby 于2019年与公司首席技术官 Jan Jangboom 共同创立了 Edge Impulse。在 Edge Impulse 于加利福尼亚州山景城的计算机历史博物馆举办年度 Imagine[6] 大会后,Shelby 曾两次与 The New Stack 进行了交谈。该公司提供一个边缘AI平台,用于收集数据、训练模型并将其部署到边缘计算设备。
Shelby说:“我们需要找到方法,使这些概率性LLM架构在无人参与或最少人工参与的应用程序中表现出更强的确定性。”
LLM在后台办公方面有多种用例,但在工业环境中,边缘则有些不同。
存在许多不同类型的架构,例如小型语言模型 (SLM)[7]、视觉语言模型 (VLM)[8] 以及其他在边缘设备上越来越有用的模型。但对于通常用于消费市场的大型通用语言模型,其用例仍不明确。
“企业在哪里看到真正的价值?” Shelby问道。“这在工业环境中LLM的早期应用中一直是个挑战。”
他说,这关乎业内人士真正信任什么:“在工业领域,我们必须有投资回报,对吧?我们必须理解我们正在解决什么问题。我们必须理解它是如何运作的。门槛要高得多。”
Shelby 说,例如,VLM正在快速成熟。
“我确实认为,随着VLM的快速成熟,我们正在发现大量的用例,因为它使我们能够进行复杂的视觉分析,这是我们通常无法用离散模型完成的。它非常有用,但需要大量的测试。你必须进行端到端测试。你必须对其进行参数化并设置这些防护栏。”
从XR眼镜到分布式AI智能体
在 Imagine 大会上,我戴上了一副扩展现实 (XR) 眼镜来查看电路板零件。通过眼镜,我可以检测到该零件,然后从一系列问题中选择要提问的问题。我使用语音提问,启用了 Whisper[9](一种语音识别服务)、YOLO[10] (You Only Look Once) 和 OpenVocabulary 进行物体检测。
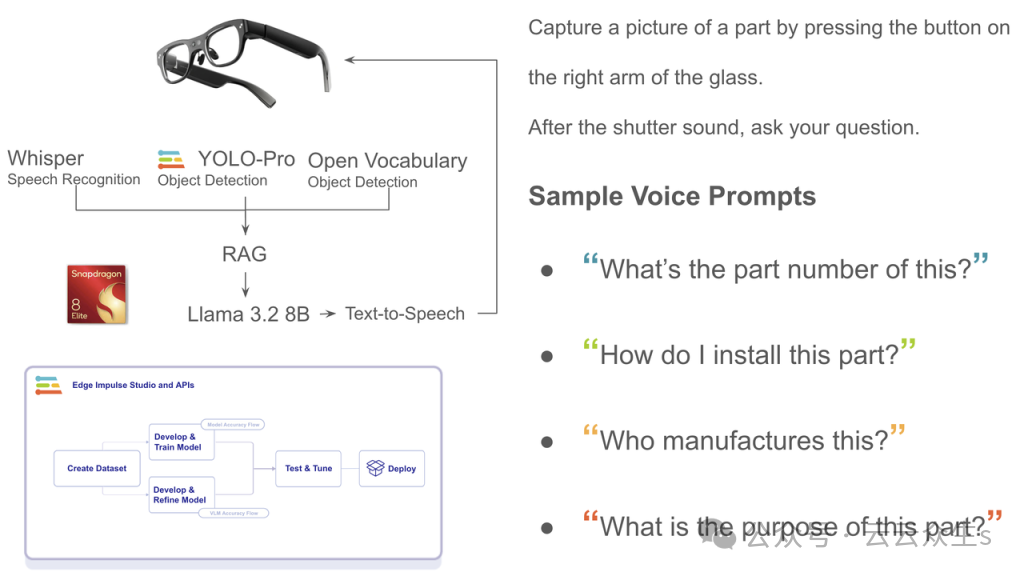 图片
图片
扩展现实眼镜的工作原理。
随后,它被馈送到一个检索增强生成 (RAG)[11] 工具中,并与 Llama 3.2[12] 集成,后者包含小型和中型视觉LLM(11B和90B),以及轻量级纯文本模型(1B和3B)。据Meta称,这些模型适用于边缘和移动设备,包括预训练和指令微调版本。
Shelby表示,下一步是什么?将智能体应用于 Edge Impulse 通过级联模型[13]实现的物理AI[14]。
工作负载可能在眼镜中运行,一个智能体解释其所见和佩戴者所说。这些数据随后可能会级联到一个AI设备[15]中,由另一个智能体执行查找。
Shelby说:“我认为这对于边缘AI技术来说真的很有趣,我们开始能够将这些智能体分布在边缘。” “这很酷。但我确实认为智能体化AI和物理AI使其易于理解。”
Shelby说,人们可以理解XR眼镜。它们展示了智能体化AI和物理AI之间的联系。
他说,小型、离散的模型,例如物体检测,在电池供电、低成本的嵌入式设备上是可行的。然而,它们无法管理生成式AI (GenAI)。为此,你需要在边缘使用功能更强大的设备。
Shelby说:“一个拥有100亿模型参数的模型,可以将其视为一个小型VLM[16]。” “或者一个小型SLM。因此,你能够做一些专注的事情。我们没有包罗万象的世界观,但我们可以做一些非常专注的事情,比如车辆或缺陷分析,一个非常专注的人类语言界面,或者一个简单的SLM来解释它。”
“我们可以在一个设备上运行它。XR眼镜就是一个很好的例子。这大概就是你今天可以生产的12到100 TOP级别的设备。”
TOP是用于描述NPU处理能力的一个术语[17]。NPU是生成式AI中使用的神经网络处理器。据Qualcomm称,“TOPS通过衡量一秒内执行的万亿次操作(加法、乘法等)数量来量化NPU的处理能力。”
Shelby说,XR眼镜可以在12到100 TOPS级别的设备上运行简单、专注的应用程序,例如使用SLM进行解释的自然语言处理。
为什么智能体化架构对边缘至关重要
除了屏幕之外,还需要智能体化应用程序,专门用于减少延迟和提高吞吐量。
Shelby在谈到使用模型分析药品包装时说:“你需要一个有多种功能同时运行的智能体化架构。” “你可能需要分析缺陷。然后你可能需要一个带有RAG支持的LLM来手动查找。这非常复杂。它背后可能需要大量数据。它可能需要非常大。你可能需要1000亿个参数。”
他指出,分析可能需要与后端系统集成以执行另一项任务,这需要多个智能体之间的协作。因此,AI设备对于管理多智能体工作流和大型模型是必要的。
任务越复杂,所需的通用智能就越多,这使得需要转向更大的AI设备。
Expanso[18] 的首席执行官兼创始人 David Aronchik 表示,边缘有三件事永远不会改变,这将影响开发人员如何在边缘设备上进行开发:
- • 数据增长。
- • 光速不会变得更快,网络也永远无法跟上,因为数据量实在太大。
- • 随着数据激增,安全和法规将继续存在,网络必须考虑多种因素。
Aronchick说,智能体化架构是数据和网络之上的一层。“随着这三件事成为现实,这意味着你必须开始将你的智能体,或者程序,或者它们可能是什么,部署出去。你必须这么做。”
Expanso 为工作负载提供分布式计算[19]。计算不是移动数据,而是走向数据本身——这对于寻求云之外计算需求的企业客户来说越来越重要。它提供了一个开源架构,使用户能够运行生成和存储数据的作业。
Aronchick说,我们将智能体化架构的工具称为什么,这谁也说不准。但与Shelby一样,Aronchick也表示延迟和吞吐量是需要解决的大问题。此外,移动数据会带来安全和监管问题。考虑到这一点,将应用程序尽可能地靠近服务器是有意义的。
确保可靠性:工业AI的防护栏
Shelby说,LLM的性质要求一个人告诉你LLM的输出是否正确,这反过来会影响如何判断LLM在边缘环境中的相关性。
Shelby说,你不能指望LLM来回答一个提示。设想德克萨斯州风景中的一个摄像头,它正对着一个油泵。“LLM可能会说,‘哦,有些露营者正在做饭’,而实际上油泵那里着火了。”
那么,如何以工程师期望的方式使这个过程可测试呢?Shelby问道。这需要端到端的防护栏。这就是为什么随机的、基于云的LLM尚未适用于工业环境的原因。
Edge Impulse 测试开发人员期望的输出模式匹配,同时了解端到端性能和准确性。这些测试在真实数据上运行。
Edge Impulse 不仅测试原始摄像头数据流,还测试物体检测器加上VLM,以及输出的分类。
Shelby说,LLM需要针对相关基础数据进行训练,例如工业机械:“然后你进行迁移学习,这就像对这些模型进行微调。”
在边缘部署LLM的谨慎方法
Shelby说,Edge Impulse 可能会将更多的神经元压缩到更小的计算单元中,因为它控制着边缘计算环境的架构。
但LLM的用例仍显示出不成熟,因此该公司正在为工业用例开发边缘约束。基础模型至关重要。该公司使用基本预处理模型,在数据从摄像头抵达后立即对其进行处理。
在LLM方面需要谨慎,设置防护栏并测试开发人员体验和可用性,以便LLM能够部署到现场。
Shelby说:“我们非常谨慎地一步一步地做,比如我们还没有引入我们的LLM。” “我们仍在努力确信这些模型如何在工业中安全使用。”
对于在风力发电机塔上工作的人来说,基于文本的输入可能没问题。不过,还有其他输入方法,例如语音接口,Shelby表示该公司正在研究将其作为一种交互方式,例如将SLM与Whisper等语音接口结合使用,以更好地理解问题或自动使用自然语言进行维护。
Shelby说:“我们将引入这项技术,并使它对开发人员来说非常容易,但你必须比云端的炒作慢一点。” “这很有趣。所以,现在的挑战是:你如何暴露这些东西?”
“使用LLM,你打算怎么做——让你的维修工在油泵上和聊天机器人聊天吗?”
引用链接
[1] The AI Inflection Point Isn't in the Cloud, It's at the Edge:https://thenewstack.io/the-ai-inflection-point-isnt-in-the-cloud-its-at-the-edge/[2]大型语言模型 (LLLM):https://thenewstack.io/introduction-to-llms/[3]金钱:https://thenewstack.io/a-guide-to-navigating-gpu-rentals-and-ai-cloud-performance/[4]Edge Impulse:https://edgeimpulse.com/[5]Qualcomm Technologies:https://www.qualcomm.com[6]Imagine:https://edgeimpulse.com/imagine[7]小型语言模型 (SLM):https://thenewstack.io/the-rise-of-small-language-models/[8]视觉语言模型 (VLM):https://thenewstack.io/a-developers-guide-to-vision-language-models/[9]Whisper:https://github.com/openai/whisper[10]YOLO:https://www.edgeimpulse.com/blog/introducing-yolo-pro-object-detection-optimized-for-the-edge/[11]检索增强生成 (RAG):https://thenewstack.io/why-rag-is-essential-for-next-gen-ai-development/[12]Llama 3.2:https://thenewstack.io/running-llama-3-2-on-aws-lambda/[13]级联模型:https://www.edgeimpulse.com/blog/coming-soon-in-edge-ai-model-cascading-with-vlms/[14]物理AI:https://thenewstack.io/integration-of-ai-with-iot-brings-agents-to-physical-world/[15]AI设备:https://thenewstack.io/ai-at-the-edge-architecture-benefits-and-tradeoffs/[16]小型VLM:https://thenewstack.io/which-vision-language-models-should-you-use-for-your-apps/[17]TOP是用于描述NPU处理能力的一个术语:https://www.qualcomm.com/news/onq/2024/04/a-guide-to-ai-tops-and-npu-performance-metrics[18]Expanso:https://www.expanso.io/[19]Expanso 为工作负载提供分布式计算:https://thenewstack.io/a-startup-complements-kubernetes-docker-and-wasm-at-the-edge/


