译者 | 布加迪
审校 | 重楼
小语言模型(SLM)是大语言模型(LLM)的紧凑版。它们包含的参数通常少于大语言模型:大约30亿个参数或更少。这使得它们相对轻量级,推理时间更快。
SLM方面一个值得研究的主题是将它们集成到检索增强生成(RAG)系统中,以增强其性能。本文探讨了这一最新趋势,概述了将SLM集成到RAG系统中的好处和局限性。
简述SLM
为了更好地描述SLM,重要的是阐明它与LLM的区别。
- 大小和复杂性:虽然LLM可能有多达数万亿个参数,但SLM小得多,通常只有几百万到几十亿个参数。这仍然相当庞大,但生活中的一切都是相对的,尤其较之LLM。
- 所需资源:鉴于尺寸减小,SLM用于训练和推理的计算资源不如LLM那么多。这种更高的资源效率是SLM的主要优势之一。
- 模型性能:另一方面,由于全面的训练过程、数量更多的参数,LLM在准确性方面往往更胜一筹,并且能够应对比SLM更复杂的任务:LLM就像一个更大的大脑!同时,SLM在理解和生成具有复杂模式的文本方面可能存在局限性。
除了资源和成本效率外,SLM的其他优点还包括更高的部署灵活性,这是由于它是轻量级模型。另一个优点是它可以更快地微调特定领域的数据集。
至于SLM的缺点,除了对非常具有挑战性的语言任务而言局限性更大外,其通用性较差,并且在处理针对它训练的领域数据之外的语言时困难更大。
SLM与RAG系统的集成
将SLM集成到RAG系统中可以实现几个目标,比如提高特定领域应用环境中的系统性能。如上所述,针对专用数据集微调SLM的成本明显低于针对相同数据集微调LLM,并且RAG系统中的微调模型可以提供比使用通用文本训练的基础模型更准确、更符合上下文的响应。总之,SLM-RAG集成可以确保经过微调的生成器(SLM)生成的内容与检索到的信息紧密相关,从而提高整个系统的准确性。
现在不妨回顾一下基本的RAG架构是什么样子的(本文中“SLM”替换生成器内的“LLM”):
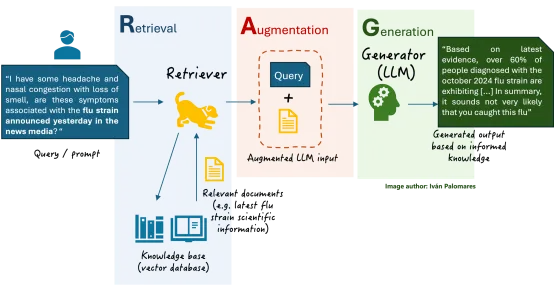
图1. RAG架构
上面讨论的SLM在RAG系统中的作用实质上是成为系统的生成器。然而,将SLM集成到RAG系统中有很多方法。一种方法是成为额外的检索器组件来增强性能,通过根据查询相关性对检索到的文档进行排名或重新排名,从而为生成器确保更高质量的输入,而生成器又可能是另一个SLM或LLM。SLM 还可能用于RAG系统中,以预处理或过滤检索到的上下文,并确保仅将最相关或最高质量的信息传递给生成器:这种方法名为预生成过滤或增强。最后还有混合RAG架构,其中LLM和SLM可以作为生成器而共存:通过查询路由机制,SLM负责处理简单或特定领域的查询,LLM 则负责处理需要更强上下文理解能力的复杂通用任务。
在RAG中使用SLM并不是各种情形下的首选方法,这种方法的一些挑战和限制如下:
- 数据稀缺:高质量、特定领域的数据集对于训练SLM至关重要,但并不总是容易找到。无法依赖足够的数据可能会导致模型性能不佳。
- 词汇限制:经过微调的SLM缺乏全面的词汇,这会影响它理解和生成具有不同语言模式的不同响应的能力。
- 部署限制:尽管SLM的轻量级特性使其适合边缘设备,但面对各种硬件确保兼容性和最佳性能仍然是一大挑战。
由此我们得出结论,对于每个RAG应用来说,SLM并不普遍优于LLM。为您的RAG系统选择SLM还是LLM应该取决于几个标准:在专注于特定领域任务的系统中,在资源受限的情况下,以及在数据隐私至关重要的情况下,SLM更适合,这使得它比LLM更容易用于云之外的推理。相反,当复杂的查询理解至关重要,并且需要检索和处理更长的上下文窗口(大量文本信息)时,LLM是通用RAG应用的首选方法。
结语
SLM提供了一种经济高效且灵活的LLM替代方案,尤其是对于简化特定领域的RAG应用程序的开发。本文讨论了在RAG系统中利用SLM的优势和局限性,阐述了小语言模型在这些创新的检索生成解决方案中的作用,这是当今AI研究领域的一个活跃主题。
原文标题:Exploring the Role of Smaller LMs in Augmenting RAG Systems,作者:Ivan Palomares Carrascosa