
大家好,我是肆〇柒。当下,移动设备已成为人们日常生活与工作的核心交互枢纽。从早起解锁手机查看消息,到工作时在各类应用间切换处理任务,图形用户界面(GUI)操作的高效性与智能性正深刻影响着我们的 productivity(生产力)与 accessibility(可访问性)。目前,随着大型语言模型(LLM)与多模态大型模型(MLLM)的飞速发展,自主 AI 智能体在 GUI 领域的应用迎来重大突破。本文将聚焦一款由清华大学、中国人民大学及 ModelBest 公司联合研发的创新性移动 GUI 智能体 ——AgentCPM-GUI,深度了解其如何凭借强化微调、紧凑动作空间设计以及高质量数据集,在多语言 GUI 操作领域实现卓越性能,为移动设备智能化交互注入全新活力。也为我们落地智能体应用带来深度的借鉴意义。
移动互联网发展多年,安卓生态系统已成为全球数十亿用户每日数字任务的核心交互界面。从生活服务类应用满足衣食住行需求,到社交平台维系人际关系网络,GUI 操作的便捷性与智能性直接决定了用户使用体验的优劣。然而,现有 GUI 智能体的发展进程却受到多重严峻挑战的制约。
一方面,数据质量和规模的瓶颈需要突破。目前多数公开数据集依赖合成生成或模拟器录制,这类数据不仅噪声水平高,而且语义多样性匮乏。以模拟器录制为例,其在模拟真实用户行为时往往难以捕捉到细微且复杂的操作意图,导致模型在学习 GUI 组件精确定位、复杂推理以及长距离规划时力不从心。另一方面,推理泛化能力的短板限制了智能体在实际场景中的应用潜力。纯模仿学习范式下的模型极易对训练见过的界面模式产生过拟合现象,一旦遭遇新场景或界面布局的微小变动,原本的规划策略便瞬间失效,任务执行成功率大幅下滑。
此外,语言和区域覆盖的局限性进一步加剧了 GUI 智能体发展的不平衡。过往研究过度聚焦于英文 GUI,而对中文等非英文移动生态的关注度严重不足。以中文移动应用生态的特殊性为例,其界面设计规范、语言提示元素与交互逻辑均与英文应用存在显著差异。例如,中文应用中常用双字节字符、特殊的表情符号以及高度紧凑的布局方式,这些特性使得现有以英文为中心的 GUI 智能体在处理中文界面时出现定位偏差、语义理解错误等问题,极大地限制了其在全球多语言环境中的普适性与实用性。
为应对上述挑战,AgentCPM-GUI 被提出,其创新性的技术方案与系统设计有望重塑移动 GUI 智能体的发展格局。
AgentCPM-GUI 核心解析
基本架构与关键特性总览
AgentCPM-GUI 基于轻量级且高效的 MiniCPM-V 模型构建,拥有 80 亿参数规模,使其在保证性能的同时具备出色的运行效率。这款智能体能够以智能手机截图作为输入源,精准解析并自主执行各类用户指定的安卓任务,无缝适配中英文应用生态。其核心优势体现在以下关键特性之中:
高质量 GUI 定位能力 :通过在大规模双语 Android 数据集上的预训练,AgentCPM-GUI 深度学习了 GUI 组件的视觉特征与语义信息,从而在复杂多变的界面环境中实现对按钮、输入框、标签、图标等组件的精准定位与语义理解。例如,在面对一款全新金融类应用的登录界面时,它能迅速识别 “用户名输入框”“密码输入框” 以及 “登录按钮” 的位置与功能,为进一步的任务执行奠定坚实基础。
广泛的中文应用适配性 :针对中文移动应用生态的特殊性,AgentCPM-GUI 进行了深度优化。它能够熟练操作 30 + 款主流中文应用,涵盖地图导航类如高德地图,生活服务类如同城旅游,社交类像微信、微博,以及影音娱乐类如爱奇艺、腾讯视频等。在这些应用中,无论是复杂的多级菜单操作,还是基于中文文本内容的搜索查询,它均能应对自如,有效突破了语言障碍对 GUI 智能体发展的限制。
强化微调赋能的推理规划能力 :借助强化微调技术,AgentCPM-GUI 实现了从 “被动模仿” 到 “主动思考” 的跨越。在执行任务前,模型能够基于当前界面状态与任务目标进行多步推理,生成合理的操作序列。以在电商应用中查找特定商品为例,它会先分析当前页面布局,确定搜索框位置并点击进入,再输入商品关键词,随后根据搜索结果页面的展示逻辑进行筛选与浏览,最终定位到目标商品,整个过程体现出 strong 的逻辑推理与规划能力。
紧凑高效的动空间设计 :为提升在移动边缘设备上的执行效率,AgentCPM-GUI 设计了一套精简的动作空间。通过采用紧凑的 JSON 格式表示动作,平均每个动作仅需 9.7 个 token,大幅减少了输出长度与计算开销。例如,一个简单的点击操作可以表示为 {"POINT":[480,320]},滑动操作则表示为 {"POINT":[500,200],"to":"down"},既保证了语义的完整性,又优化了运行时的资源利用率,使其在算力有限的移动设备上能够流畅运行,响应迅速。
深度科研细节:渐进式训练方法论
数据集构建的艺术
AgentCPM-GUI 的卓越性能始于其精心构建的数据集。研发团队投入大量精力收集中文安卓应用的 55K 轨迹、470K 步骤,全面覆盖生活服务、电子商务、地图导航、社交、视频、音乐 / 音频、阅读 / 学习以及生产力等八大功能领域,确保数据的丰富性与多样性。为避免过拟合,他们还整合并去重多个公共英文数据集,形成统一的数据集框架,有力支撑跨语言、跨应用的行为建模。
在数据收集过程中,团队采用多维度的质量保障措施。一方面,利用参数化指令模板结合 GPT-4o 生成多样化的查询指令,再经人工审核去除错误与重复内容,并通过 GPT-4o 进行改写以拓展词汇覆盖范围。另一方面,在真实的安卓手机上进行轨迹采集,借助定制的数据记录器仅记录经人工确认的点击、长按、滑动、文本输入等操作及其关联的 UI 元数据,有效过滤掉模拟器录制中常见的噪声事件,确保数据的真实性与可靠性。
渐进式训练流程的精妙
AgentCPM-GUI 的训练流程遵循从感知到行动、再到推理的渐进式学习路径,包含三个关键阶段:
阶段一:视觉感知与定位预训练 :聚焦于提升模型的底层感知与定位能力。研发团队收集大量 OCR(光学字符识别)任务数据以及组件定位任务数据,使模型能够精准学习 GUI 组件与文本描述之间的空间与语义对应关系。例如,通过学习大量带有标记区域的图像与对应文本内容的数据对,模型可以准确识别出图像中特定文本的位置与内容,为后续的任务执行提供可靠的视觉基础。此阶段混合 50% 的通用多模态 SFT 数据,不仅规整了视觉模块,还让模型吸收 GUI 特定的线索,在 12M 样本的训练下,模型在视觉感知任务上展现出色的性能,但此时其在高层次任务语义理解和规划方面仍较为薄弱。
阶段二:监督微调(SFT) :基于第一阶段预训练的模型,对自然语言指令与 GUI 任务执行轨迹数据进行监督微调。这一阶段使模型学会将自然语言指令映射到具体的操作动作,生成符合语境的有效动作序列。
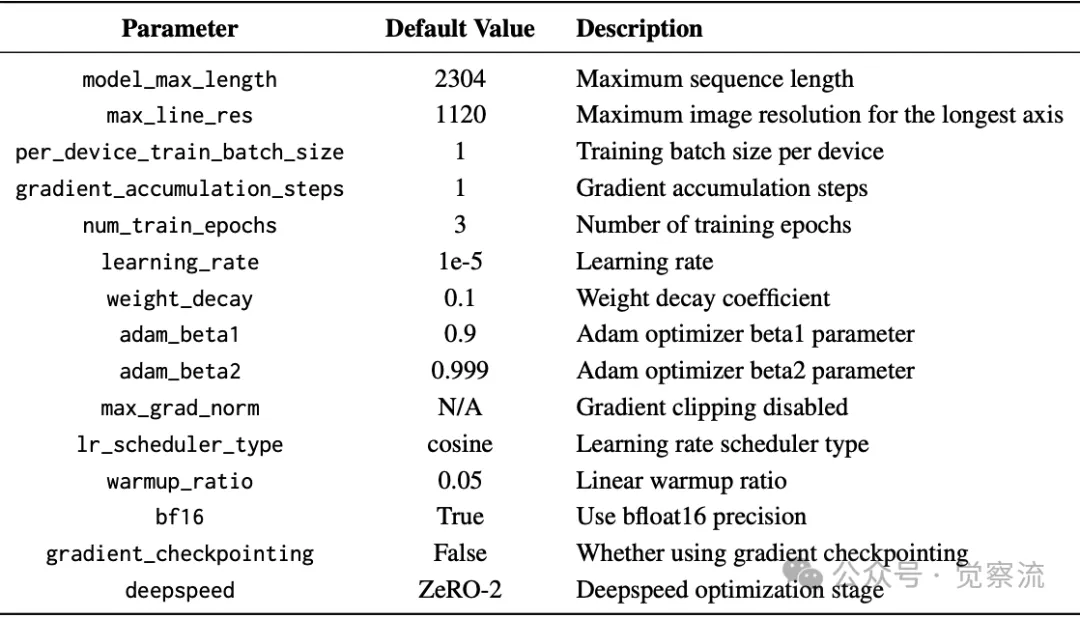
第二阶段训练参数:有监督微调
例如,当接收到 “打开应用菜单并选择设置选项” 的指令时,模型能够根据已学习的轨迹数据,生成相应的点击操作序列来完成任务。在训练过程中,为增强跨语言泛化能力并减少过拟合风险,团队将中文语料与英文语料进行混合训练,并对英文数据集进行去重处理。同时,在 SFT 阶段引入初步的思考生成,为后续强化微调阶段的推理优化奠定基础。共使用 6.9M 实例进行监督微调,使模型在中英双语环境下均能生成较为合理的操作序列。
阶段三:强化微调(RFT) :采用 Group Relative Policy Optimization(GRPO)算法对模型进行强化微调,着重提升其推理决策能力。
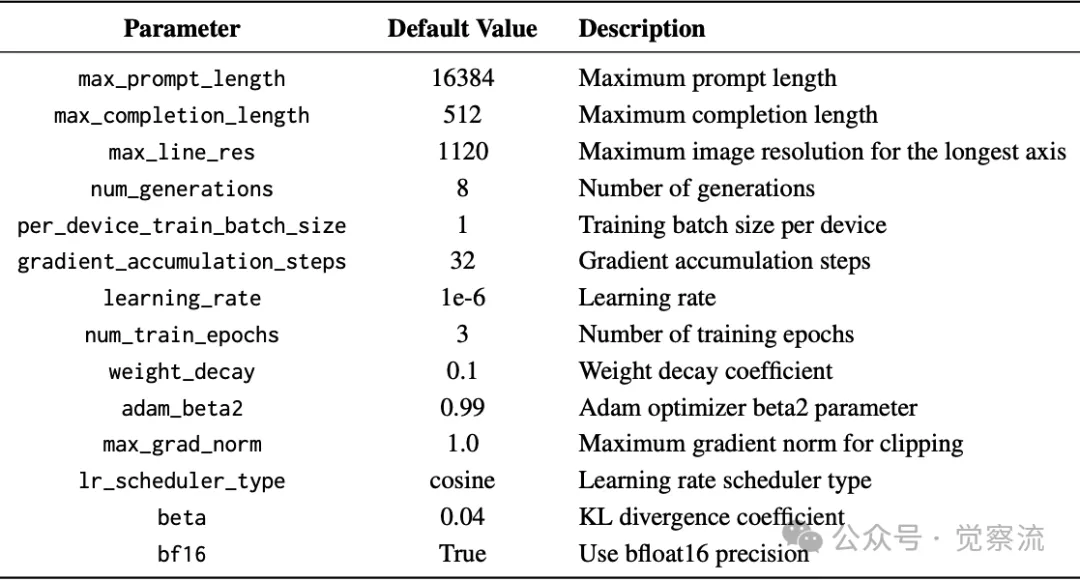
第三阶段训练参数:强化微调
GRPO 算法通过组内比较替代传统 PPO 算法中的价值critic,对每个查询 q,当前策略 πθold 采样 N 个响应 {o1,…, oN},为每个响应分配标量任务奖励 {r1,…, rN}。通过组内比较计算方差减少的优势估计,然后使用带 KL 散度惩罚的裁剪目标更新策略。在训练过程中,模型的策略会根据环境反馈的奖励信号动态调整,以生成更具适应性与高效性的操作序列。例如,在面对界面布局变化或任务目标更新时,推理优化器能够引导模型重新规划操作路径,选择最优的操作序列以达成任务目标。这种基于 GRPO 的强化微调策略,使 AgentCPM-GUI 能够突破单纯模仿学习的局限,实现更具适应性与创造性的任务规划与执行。
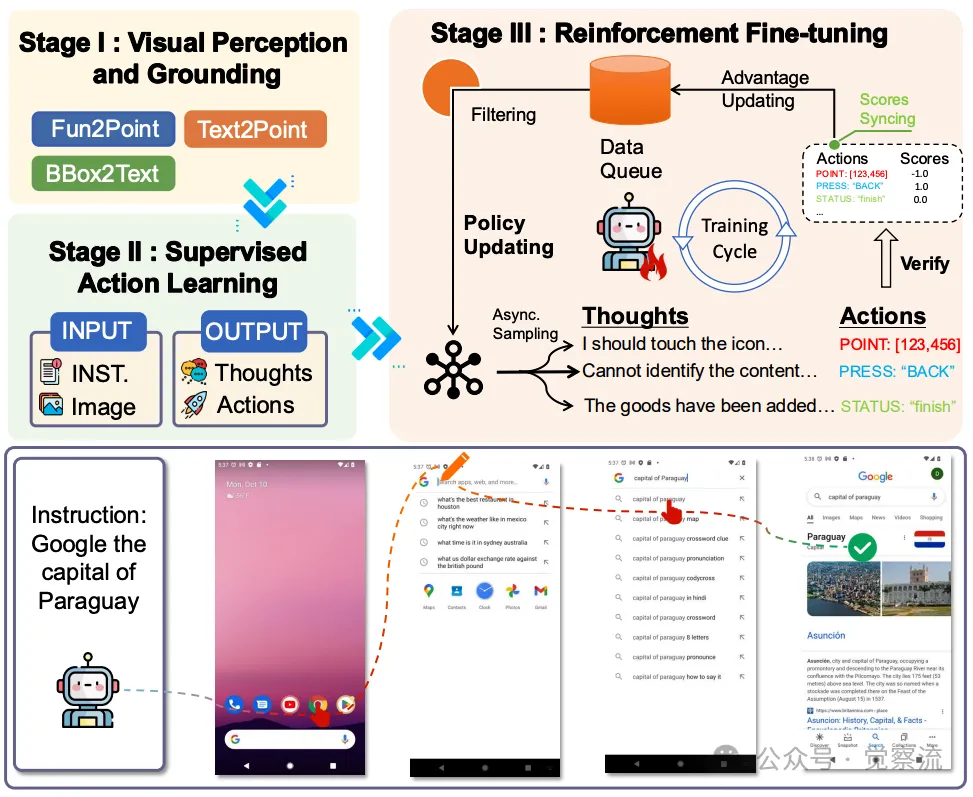
关于本训练框架的概述
上图展示了 AgentCPM-GUI 的完整训练框架,涵盖了从视觉感知预训练到监督微调再到强化微调的全过程,帮助我们更直观地理解模型能力培养的路径。
动作空间设计的巧思
AgentCPM-GUI 的动作空间设计精简而高效,包含六种原子动作类型及其灵活组合方式:
POINT 动作 :用于指定屏幕上的一个坐标点进行点击操作。它接收一个整数元组(x,y),坐标范围归一化至 [0,1000],以当前窗口的左上角为原点,右下角为(1000,1000)。例如,{"POINT":[500,500]}表示在屏幕中心位置执行点击操作。此外,POINT 动作还可与 duration 参数结合,表示长按操作;与 to 参数结合,表示从当前点向指定方向或坐标滑动的操作,如{"POINT":[500,200],"to":"down"}表示从坐标(500,200)向下方滑动。
to 动作:专门用于实现界面内的滚动操作。它可以指定滚动方向,取值包括 “up”(向上)、“down”(向下)、“left”(向左)、“right”(向右),或者与 POINT 动作配合,定义从一个坐标点到另一个坐标点的滑动轨迹。例如,{"to":"up"}表示在当前界面内向上滚动,而{"POINT":[200,300],"to":"right"}则表示从坐标(200,300)向右滑动。
TYPE 动作:用于在当前输入焦点处输入指定文本。它接收一个字符串作为参数,例如{"TYPE":"Hello, world!"}表示在文本输入框中输入 “Hello, world!” 字符串。这一动作在需要进行文本输入的任务场景中至关重要,如登录账号、搜索查询等操作。
PRESS 动作:用于触发设备的特殊按键,包括 “HOME”(返回桌面)、“BACK”(返回上一界面)、“ENTER”(确认输入)等。这些按键操作在安卓系统的导航与交互中频繁出现,通过 PRESS 动作,模型能够模拟用户对设备按键的按下操作,实现界面的切换与任务的推进。例如,{"PRESS":"BACK"}表示按下返回键,回到上一界面。
STATUS 动作:用于更新当前任务的状态,包括 “continue”(继续执行)、“finish”(任务完成)、“satisfied”(任务条件已满足)、“impossible”(任务无法完成)、“interrupt”(任务中断)、“need_feedback”(需要用户反馈)等。例如,当模型检测到任务目标已达成时,可生成{"STATUS":"finish"}动作,终止后续操作。
duration 参数:用于指定动作持续的时间长度,以毫秒为单位。它可以独立使用,表示等待操作,如{"duration":1000}表示等待 1000 毫秒(即 1 秒);也可以与其他动作结合使用,表示长按或滑动的持续时间,如{"POINT":[480,320],"duration":2000} 表示在坐标(480,320)处进行时长为 2000 毫秒的长按操作。
通过紧凑的 JSON 格式表示这些动作,AgentCPM-GUI 在保证动作语义清晰完整的同时,极大地减少了输出长度与 token 消耗。例如,一个包含点击操作和思考过程的完整输出可能如下所示:
{"thought":"根据用户指令,当前需要点击登录按钮完成登录操作。在分析当前界面后,确定登录按钮位于屏幕中央偏右位置。","POINT":[729,69]}
其中,thought 字段记录了模型的思考过程,为操作提供了语义解释;POINT 动作则指定了具体的点击坐标。这种设计提升了模型在移动设备上的运行效率,还便于开发者对模型的输出进行解析与处理。

AgentCPM-GUI 的示例操作
上表展示了一些具体的动作示例,使我们能更清晰地了解 AgentCPM-GUI 的动作空间设计。
技术架构的底层逻辑
MiniCPM-V 的选型智慧
AgentCPM-GUI 的底层架构基于 MiniCPM-V,这款轻量级的视觉 - 语言模型在其设计之初便充分考虑了移动设备应用场景的需求。MiniCPM-V 拥有 80 亿参数,这使得它在具备强大表达能力的同时,能够保持相对较低的计算资源消耗与推理延迟,完美适配移动设备的硬件条件限制。
其模型结构深度融合了视觉编码器与语言解码器,通过多层的交叉注意力机制实现视觉信息与语言指令的高效交互。在处理 GUI 操作任务时,视觉编码器首先对输入的截图进行特征提取,捕捉屏幕中各类 GUI 组件的视觉特征与空间布局信息;语言解码器则对自然语言指令进行语义解析,提取任务目标的关键语义要素。随后,交叉注意力机制将视觉特征与语言语义进行深度融合,使模型能够精准理解任务目标与当前界面状态之间的关系,从而生成合理有效的操作动作。
模块间协作的机制
三个训练阶段分别针对感知、行动、推理能力进行强化,各模块之间紧密协作,共同实现端到端的 GUI 操作流程:
1. 感知预训练阶段 :视觉编码器模块专注于学习 GUI 组件的视觉特征表示,包括按钮的形状、颜色、图标样式,文本标签的字体、大小、位置等信息。通过大量的 OCR 与组件定位任务训练,该模块能够精确提取屏幕中各类组件的视觉特征,并将其转换为高维特征向量,为后续的任务执行提供丰富的视觉信息基础。
2. 监督微调阶段 :引入语言解码器模块与操作生成器模块。语言解码器对自然语言指令进行语义解析,将其转换为语义向量;操作生成器则基于视觉编码器提取的视觉特征与语言解码器输出的语义向量,学习生成对应的操作动作。此时,模型通过联合训练,逐渐学会将指令语义与视觉场景相结合,生成符合任务目标的操作序列。
3. 强化微调阶段 :推理优化器模块被激活。该模块基于前两个阶段学习到的感知与操作生成能力,通过强化学习算法对操作序列进行优化。它根据环境反馈的奖励信号,动态调整操作生成策略,使模型能够生成更具适应性与高效性的操作序列。例如,在面对界面布局变化或任务目标更新时,推理优化器能够引导模型重新规划操作路径,选择最优的操作序列以达成任务目标。
各模块之间通过共享参数与梯度信息,在训练过程中不断调整与优化自身的权重与结构,最终实现紧密结合与高效协作。在实际推理过程中,输入的截图与指令依次经过视觉编码器、语言解码器、操作生成器与推理优化器的处理,最终输出精准的操作动作,实现从视觉感知到任务执行的完整闭环。
实验验证:性能的全面度量
基准测试的选择依据
鉴于公共基准测试在 GUI 智能体评估领域的广泛应用与权威性,AgentCPM-GUI 选择在 AndroidControl、GUI-Odyssey、AITZ 等经典基准测试上进行全面性能评估。这些基准测试涵盖了从简单界面操作到复杂多步骤任务的广泛场景,能够充分衡量模型在不同类型任务中的表现。
同时,为弥补现有基准测试在中文 GUI 评估方面的空白,团队引入了自行构建的中文 GUI 基准 CAGUI。CAGUI 基准包含丰富的中文安卓应用操作任务,从地图导航中的地点搜索到社交应用中的消息发送,全面覆盖中文用户的日常操作场景。通过在 CAGUI 上的评估,能够精准衡量模型在中文语言环境下的 GUI 操作能力,为多语言 GUI 智能体的研究与发展提供重要的参考依据。
评估指标的考量维度
评估指标体系由类型匹配(Type Match,TM)与精确匹配(Exact Match,EM)两部分构成,二者相辅相成,全面刻画模型的性能表现:
类型匹配(TM) :关注预测动作类型与真实动作类型的匹配程度。例如,若模型预测出点击操作而真实动作确实是点击,则 TM 指标计为正确。这一指标主要衡量模型对任务操作类型的判断能力,反映其对任务语义的高层理解水平。在复杂的多步骤任务中,即使部分操作参数存在偏差,只要操作类型正确,TM 仍能体现出模型对任务执行流程的合理性把握。精确匹配(EM) :在 TM 的基础上进一步要求动作参数完全正确。以点击操作为例,不仅操作类型需为点击,预测的坐标点还需与真实坐标点在预设的容差范围内(通常根据屏幕分辨率与组件大小确定合理阈值)才能判定为 EM 正确。这一指标对模型的操作精度提出更高要求,直观反映其在实际设备操作中的成功率与可靠性。
结合 TM 与 EM 两项指标,研发人员能够全面深入地了解模型在不同任务场景下的优势与不足,为后续的优化与改进提供明确的方向指引。
关键实验结果解读
Grounding 定位能力测试
在 CAGUI 基准测试的 Fun2Point、Text2Point 和 Bbox2Text 三项任务中,AgentCPM-GUI 凭借其卓越的感知与定位能力,分别取得了 79.1%、76.5% 和 58.2% 的准确率,平均准确率达到 71.3%,显著超越其他基线模型。
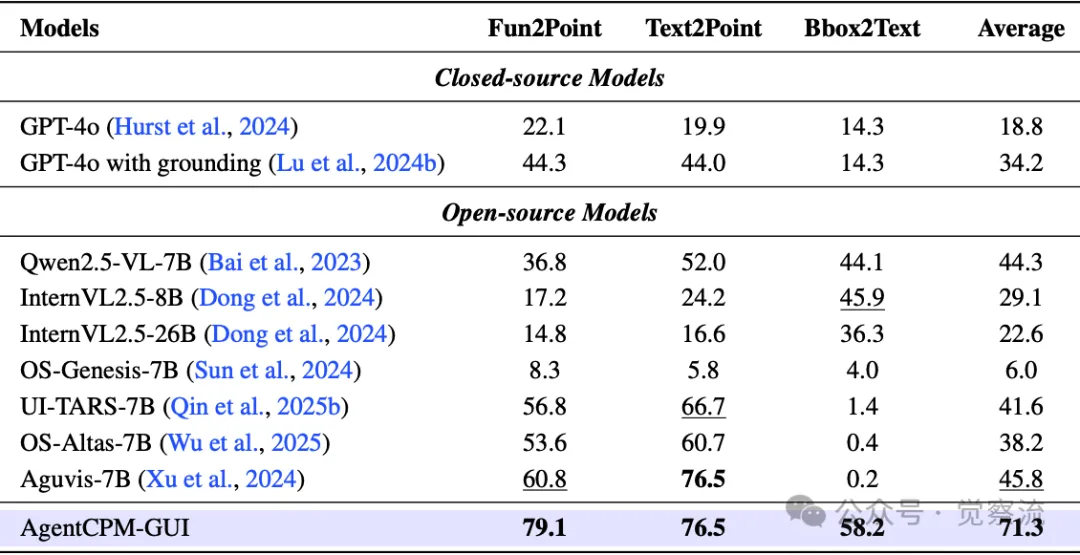
在CAGUI基准测试的Fun2Point、Text2Point和Bbox2Text子任务上对GUI定位准确率进行评估,加粗和下划线分别表示最佳和第二好的结果
上表提供了 CAGUI 基准测试中各模型在 Fun2Point、Text2Point 和 Bbox2Text 任务上的具体准确率数据,直观地展示了 AgentCPM-GUI 在 GUI 定位能力上的优势。
例如,在 Text2Point 任务中,面对复杂多变的中文界面文本布局,AgentCPM-GUI 能够精准定位到指定文本字符串的位置,这得益于其在大规模双语数据集上的预训练以及精心设计的渐进式训练流程。相比之下,多数基线模型在 Bbox2Text 任务中表现不佳,准确率低于 5%,主要归因于它们难以在视觉区域与文本内容之间建立精准的对应关系,尤其在处理小字体、复杂背景以及文本密集排列的中文界面时,定位精度大幅下降。
动作预测能力测试
在多个基准测试中,AgentCPM-GUI 的 TM 和 EM 指标均展现出显著的领先优势。
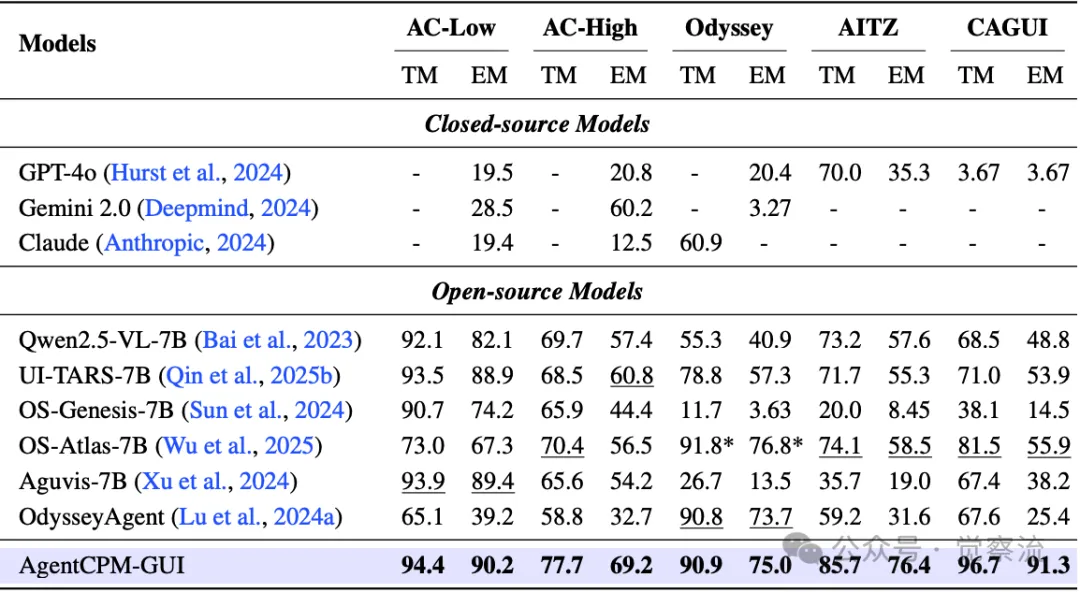
五个GUI Agent基准测试中,按类型匹配(TM)和精确匹配(EM)衡量的步骤级动作预测性能。加粗和下划线分别表示最佳和次佳结果。*OS-Atlas在GUI-Odyssey基准测试中使用了不同的训练/测试分割,因此无法直接比较
上表列出了 AgentCPM-GUI 在 AndroidControl、GUI-Odyssey、AITZ 以及 CAGUI 等五个 GUI Agent 基准测试上的 Type Match(TM)和 Exact Match(EM)性能指标,突显了其在各类任务场景中的卓越表现。
在 AndroidControl-Low 数据集上,其 TM 达到 94.39%,EM 达到 90.20%;在更具挑战性的 GUI-Odyssey 数据集上,TM 为 90.85%,EM 为 74.96%;而在中文专属的 CAGUI 基准测试中,TM 高达 96.86%,EM 达到 91.28%。这些数据有力证明了 AgentCPM-GUI 在复杂多步骤场景以及中文语言环境下的强大泛化能力与推理规划能力。通过对比发现,在面对长距离依赖、多步骤决策以及界面布局动态变化的任务时,其渐进式训练方法与强化微调策略能够有效提升模型对任务执行路径的优化能力,使其在保持高操作类型准确性的同时,显著提高动作参数的精确度,从而在 EM 指标上拉开与竞争对手的差距。
强化微调效果评估
通过对比强化微调(RFT)阶段前后的模型性能,可以清晰地看到强化微调对模型推理能力的显著提升作用。

消融研究比较了RFT前后AgentCPM-GUI的性能
上表展示了强化微调前后 AgentCPM-GUI 在不同数据集上的性能对比,说明了 RFT 对提升模型 Exact Match 准确率的重要作用。
在 AndroidControl-Low、GUI-Odyssey 和 AITZ 等数据集上,RFT 后模型的 Exact Match 准确率分别提升了 [具体提升数值],例如在 GUI-Odyssey 数据集上,RFT 前 EM 为 [X]%,RFT 后提升至 74.96%。这表明强化微调阶段通过引入环境反馈与奖励信号,引导模型对操作序列进行深度优化,使其能够更好地应对复杂任务场景中的不确定性与动态变化,生成更具适应性与鲁棒性的操作序列。
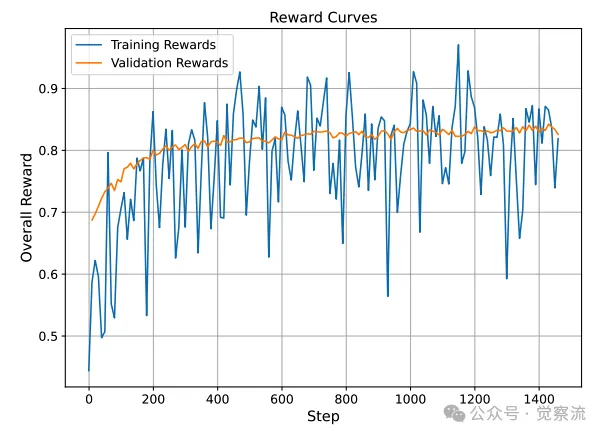
AgentCPM-GUI训练集和验证集上的奖励曲线
上图展示了 AgentCPM-GUI 在训练集和验证集上的奖励曲线,反映了 RFT 过程中模型的优化趋势和良好的泛化能力。
模型局限性剖析
尽管 AgentCPM-GUI 在 GUI 智能体领域取得了显著的成果,但其仍存在一些局限性有待克服。
- 泛化能力瓶颈 :在面对全新的应用领域、未知类型的应用程序以及动态变化的界面布局时,模型的泛化能力受到一定限制。例如,当遇到一款采用全新交互设计 paradigm(范式)的创新型应用时,由于训练数据中缺乏对该类界面布局与交互逻辑的覆盖,模型可能无法准确理解界面元素的功能与操作方式,导致任务执行失败率上升。此外,不同应用之间的组件布局差异、交互逻辑复杂度以及视觉设计风格的多样性,也对模型的泛化能力提出了更高的要求。
- 多模态交互局限 :目前的 AgentCPM-GUI 主要依赖视觉信息进行 GUI 操作,对于复杂的多模态交互任务支持不足。在实际应用中,用户可能通过语音指令、手势操作以及文本输入等多种模态与设备进行交互。然而,AgentCPM-GUI 在融合视觉、语音、文本等多种模态信息进行综合理解与决策方面存在短板,难以满足复杂多模态指令的理解与执行需求。例如,在语音指令与视觉场景存在语义关联的情况下,模型无法有效整合两者信息,从而影响任务执行的准确性和效率。
- 动作空间的拓展性不足 :尽管当前的动作空间设计已经能够满足大多数常见 GUI 操作需求,但在面对一些复杂的交互操作(如多指手势、3D 触控操作等)时,现有的动作表示方式显得力不从心。这限制了模型在高端应用与专业领域中的操作能力,无法充分发挥现代移动设备丰富多样的交互功能。
深入剖析模型局限性
泛化能力瓶颈的深层次原因 :不同应用界面布局的多样性与复杂性是导致泛化能力瓶颈的关键因素。例如,一些应用可能采用独特的三层式菜单结构,而另一些应用则可能使用创新的滑动式交互逻辑。这些差异使得模型在训练过程中难以接触到所有可能的界面布局模式,从而在面对新应用时出现特征提取与任务理解的困难。目前,领域内针对泛化能力提升的前沿方法包括数据增强技术与元学习策略。数据增强技术通过模拟多样化的界面风格与布局形式,如随机改变组件的大小、颜色、位置等,使模型在训练过程中接触更广泛的视觉变化,从而增强其对不同界面风格的适应性。元学习策略则侧重于培养模型快速适应新任务的能力,通过在训练中引入多种不同但相关的任务,使模型学会如何利用少量的新数据快速调整自身的参数与策略,以适应新领域的任务需求。
多模态交互局限的根源分析 :多模态交互局限主要源于模型当前的感知模态覆盖范围有限。现有的 AgentCPM-GUI 仅依赖视觉信息进行操作决策,而忽略了语音、手势等其他模态所蕴含的丰富语义信息。在实际交互场景中,语音指令可能包含用户的情感、语调等非语言信息,手势操作则能够传达空间位置、动作意图等视觉难以捕捉的内容。为了突破这一局限,学术界与工业界正在积极探索多模态融合技术。例如,构建多模态融合模块,通过深度神经网络将不同模态的信息映射到统一的语义空间,实现视觉、语音、文本等多模态信息的有效整合。同时,开展多模态预训练,在大规模多模态数据集上进行联合训练,使模型能够学习到不同模态之间的语义关联与交互模式,从而在面对多模态指令时能够进行准确的语义解析与联合决策。
动作空间拓展性不足的改进方向 :动作空间拓展性不足限制了模型对复杂交互操作的支持能力。例如,现代移动设备支持多指手势操作,如双指缩放、三指滑动等,这些操作在专业绘图、地图浏览等应用中具有重要作用。目前,拓展动作空间的可能方向包括引入手势轨迹点序列与压力级别等参数,以详细表示复杂手势操作的细节。同时,研究如何将这些复杂动作与现有动作进行有机组合,形成更加灵活的操作序列,以适应高端应用中的复杂交互需求。例如,设计一种复合动作表示格式,将多指手势的起始位置、移动轨迹、结束位置以及压力变化等信息进行编码,使模型能够理解和执行复杂的交互操作,充分发挥移动设备的交互潜力。
未来研究方向展望
针对上述局限性,未来 GUI 智能体的研究可着重探索以下几个方向:
模型架构优化与泛化能力提升 :引入先进的注意力机制变体(如动态路由注意力、层次化注意力等)以及元学习策略,使模型能够快速适应新领域的数据特征与界面布局模式。通过在训练过程中引入多样化的领域风格迁移技术,增强模型对不同应用视觉风格的鲁棒性。例如,采用基于生成对抗网络(GAN)的界面风格迁移方法,使模型在训练数据中接触更多样化的界面风格与布局形式,从而提升其跨领域的泛化能力。
动作空间的拓展与丰富 :融合多模态交互动作,如语音指令触发、手势操作组合等,使模型能够支持更加丰富多样的交互方式。针对复杂手势操作,设计相应的动作表示格式与参数定义,例如通过引入手势轨迹点序列与压力级别等参数,扩展动作空间的表达能力。同时,研究如何将这些复杂动作与现有动作进行有机组合,形成更加灵活的操作序列,以适应高端应用中的复杂交互需求。
多模态交互能力强化 :构建多模态融合模块,深度整合视觉、语音、文本等多种模态信息处理流程。利用多模态预训练技术,在大规模多模态数据集上进行联合训练,使模型能够学习到不同模态之间的语义关联与交互模式。例如,通过构建视觉 - 语音 - 文本三模态的关联学习任务,让模型理解同一语义内容在不同模态下的表达形式,从而在面对多模态指令时能够进行准确的语义解析与联合决策。
知识增强与跨领域适应性提升 :结合知识图谱技术,将领域知识、常识知识以及操作流程知识等先验信息融入模型,增强模型对任务的语义理解与逻辑推理能力。采用迁移学习方法,通过在源领域与目标领域之间建立知识迁移桥梁,使模型能够利用源领域的知识经验快速适应新领域的任务需求。例如,针对办公类应用与生活服务类应用之间的跨领域任务迁移,提取两者在操作流程与界面布局上的共性知识,作为迁移学习的知识基础,加速模型在新领域的适应过程。
实际应用案例:从理论到实践的跨越
案例一:小米 12S 上的哔哩哔哩视频观看与点赞
在小米 12S 设备上,用户希望使用 AgentCPM-GUI 完成在哔哩哔哩应用中观看李子柒最新视频并点赞的任务。以下是详细的执行流程与模型思考逻辑:
1. 初始界面分析与操作 :模型首先接收手机主屏幕截图,根据用户指令 “去哔哩哔哩看李子柒最新视频并点赞” 进行语义解析,确定任务目标。在分析主屏幕界面时,它通过视觉感知模块识别出哔哩哔哩应用图标的位置,生成点击操作 {"POINT":[396,470]},打开应用。
2. 搜索操作执行 :进入哔哩哔哩应用后,界面显示为推荐视频列表。模型根据任务目标判断需要进行搜索操作,定位到搜索栏位置并点击 {"POINT":[390,62]}。随后,生成文本输入操作 {"TYPE":"李子柒"},在搜索框中输入关键词。
3. 搜索结果处理与视频播放 :点击搜索按钮 {"POINT":[920,64]} 后,模型进入搜索结果页面。在结果列表中,它通过分析视频标题与封面图片等视觉与文本信息,定位到李子柒的个人主页入口或最新视频缩略图位置 {"POINT":[192,267]},点击进入视频播放界面。
4. 点赞操作完成 :视频开始播放后,模型持续监测界面状态,等待视频加载完成并出现点赞按钮。一旦检测到点赞按钮位置,立即生成点击操作 {"POINT":[141,490]} 完成点赞任务。最后,输出 {"STATUS":"finish"} 表明任务执行完毕。
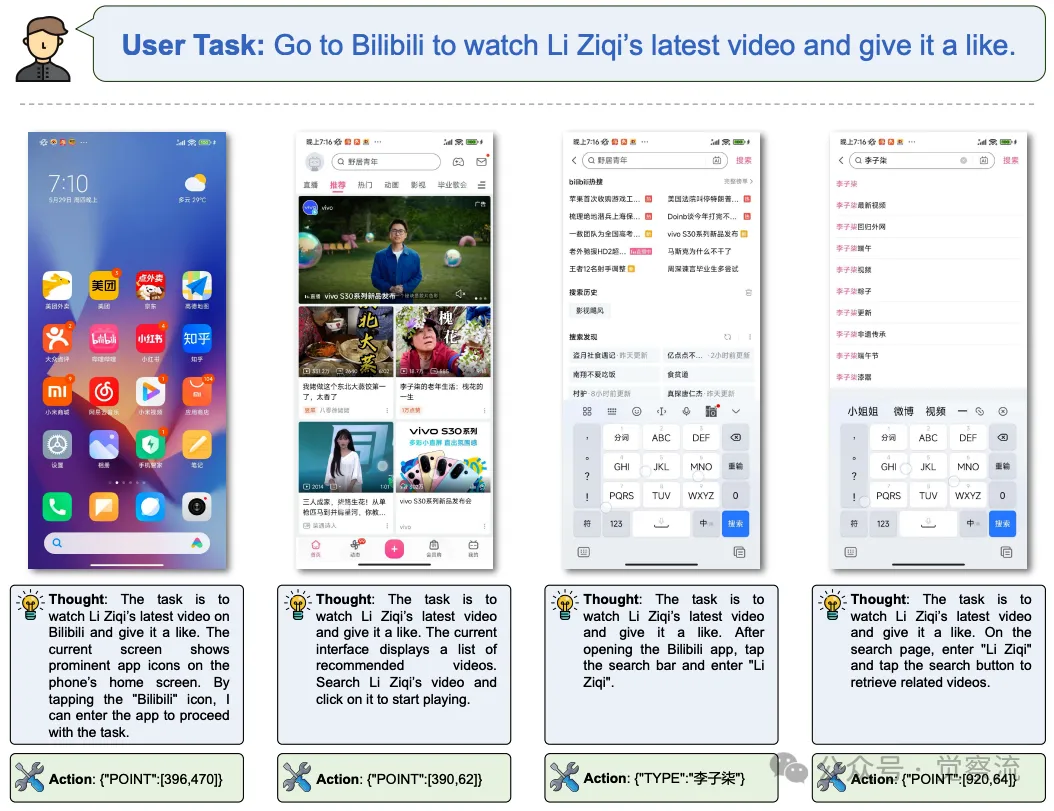
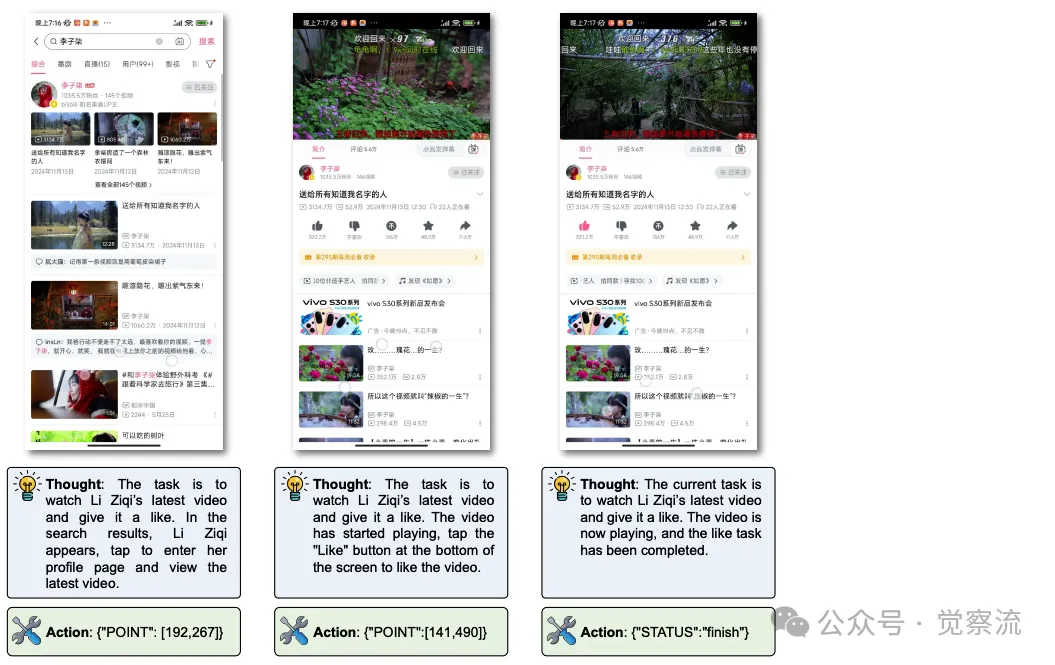
在 B 站上的 Demo 用例
上图直观地演示了 AgentCPM-GUI 在小米 12S 设备上完成哔哩哔哩视频观看与点赞任务的操作流程,让我们能更清晰地看到模型在实际应用中的表现。
在整个过程中,AgentCPM-GUI 准确理解用户指令,灵活应对不同界面布局与操作需求,精准执行每一步操作,充分展现出其在实际应用中的高效性与可靠性。
案例二:网易云音乐歌曲搜索与播放
另一个典型案例是用户要求在网易云音乐应用中搜索并播放歌曲《大城小事》。AgentCPM-GUI 的操作流程如下:
1. 搜索框定位与点击 :模型接收当前屏幕截图后,识别出网易云音乐应用的搜索栏位置,生成点击操作 {"POINT":[356,63]},激活输入焦点。
2. 歌曲关键词输入 :执行文本输入动作 {"TYPE":"大城小事"},将歌曲名称输入到搜索框中。
3. 触发搜索操作 :点击搜索按钮 {"POINT":[916,59]},提交搜索请求。
4. 搜索结果筛选与播放 :在搜索结果列表中,模型通过分析歌曲名称、歌手信息以及专辑封面等多维度信息,定位到目标歌曲《大城小事》的位置 {"POINT":[550,370]} 并点击播放。
5. 任务完成判定 :确认歌曲进入播放界面后,输出 {"STATUS":"finish"},结束任务执行流程。
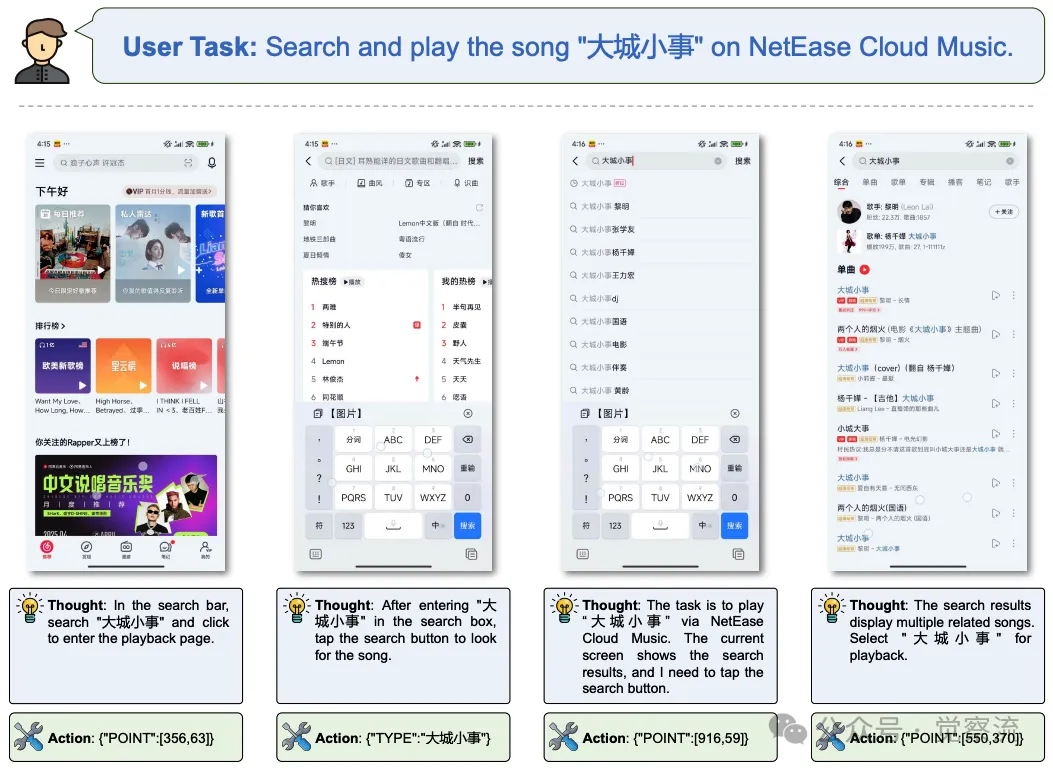
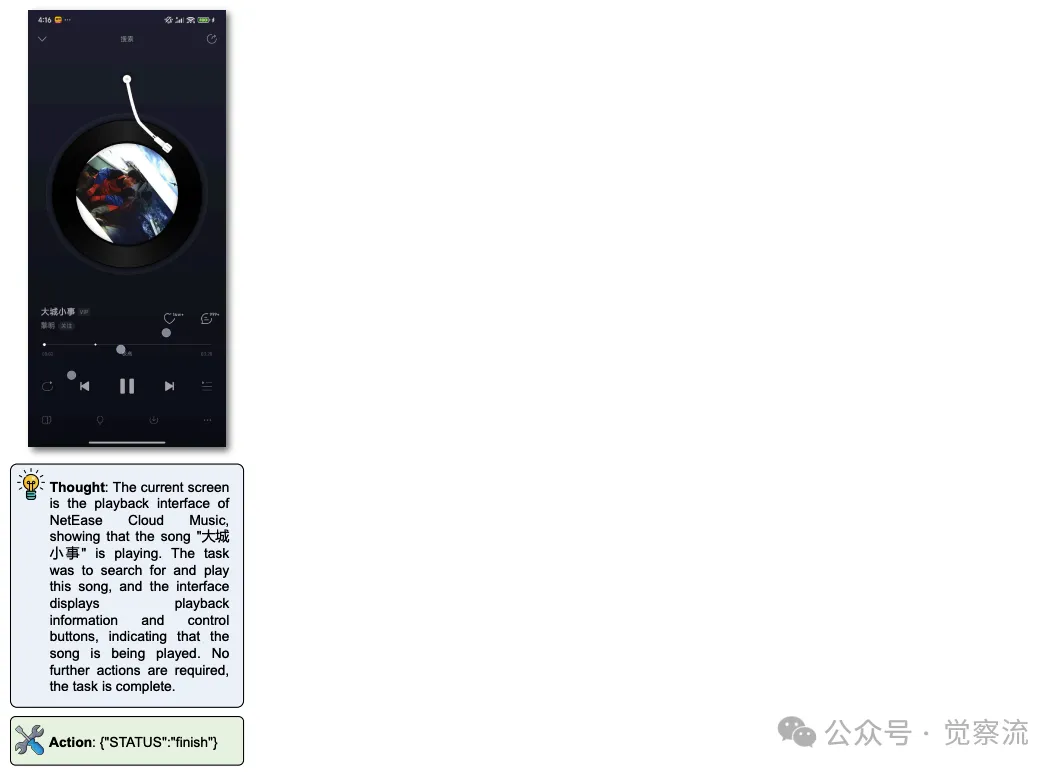
在网易云音乐上的 Demo 用例
上图展示了 AgentCPM-GUI 在网易云音乐应用中搜索并播放歌曲《大城小事》的任务执行过程,体现了其在音乐类应用任务处理中的高效性和准确性。
该案例再次证明了 AgentCPM-GUI 在处理中文音乐类应用任务时的强大能力,无论是对搜索流程的精准把控,还是对播放界面元素的正确识别与操作,均体现出其卓越的 GUI 操作性能,有效提升用户在移动音乐场景下的 productivity 与 accessibility。
开源生态:共享与协作的力量
项目开源
AgentCPM-GUI 的研发团队秉持开放共享的理念,将项目的全部核心资源开源至 GitHub 平台。开源内容涵盖模型训练与评估代码、CAGUI 基准测试数据以及模型检查点文件,为全球开发者与研究人员提供了一个透明、可访问且可复现的研究基础。代码遵循 Apache-2.0 协议,保障了使用者在遵循协议条款的前提下,能够自由地对代码进行修改、分发与商业应用,极大地促进了技术的传播与创新。
快速上手实践指南
为了帮助开发者与研究人员快速掌握 AgentCPM-GUI 的使用方法,团队提供了详尽的环境配置与模型部署指南。从依赖环境安装、模型文件下载,到推理代码示例,每一步均配有清晰的说明与示例代码。例如,在推理部分,展示了如何加载模型与 tokenizer,如何构建输入消息格式,以及如何解析模型输出结果,使用户能够迅速搭建起开发环境并开始应用探索。
以下是 Qwen2.5-VL-7B 数据示例:System Message:
复制You are a helpful assistant.
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{"type": "function", "function": {"name_for_human": "mobile\_use", "name": "mobile\_use", "
description": "Use a touchscreen to interact with a mobile device, and take screenshots.
* This is an interface to a mobile device with touchscreen. You can perform actions like clicking,
typing, swiping, etc.
* Some applications may take time to start or process actions, so you may need to wait and take
successive screenshots to see the results of your actions.
* The screen's resolution is 1092x2408.
* Make sure to click any buttons, links, icons, etc with the cursor tip in the center of the element.
Don't click boxes on their edges unless asked.", "parameters": {"properties": {"action": {"
description": "The action to perform. The available actions are:
* `key`: Perform a key event on the mobile device.
− This supports adb's `keyevent` syntax.
− Examples: \"volume\_up\", \"volume\_down\", \"power\", \"camera\", \"clear\".
* `click`: Click the point on the screen with coordinate (x, y).
* `long\_press`: Press the point on the screen with coordinate (x, y) for specified seconds.
* `swipe`: Swipe from the starting point with coordinate (x, y) to the end point with coordinates2 (
x2, y2).
* `type`: Input the specified text into the activated input box.
* `system\_button`: Press the system button.
* `open`: Open an app on the device.
* `wait`: Wait specified seconds for the change to happen.
* `terminate`: Terminate the current task and report its completion status.", "enum": ["key", "click",
"long\_press", "swipe", "type", "system\_button", "open", "wait", "terminate"], "type": "string
"}, "coordinate": {"description": "(x, y): The x (pixels from the left edge) and y (pixels from
the top edge) coordinates to move the mouse to. Required only by `actinotallow=click`, `actinotallow=
long\_press`, and `actinotallow=swipe`.", "type": "array"}, "coordinate2": {"description": "(x, y):
The x (pixels from the left edge) and y (pixels from the top edge) coordinates to move the
mouse to. Required only by `actinotallow=swipe`.", "type": "array"}, "text": {"description": "
Required only by `actinotallow=key`, `actinotallow=type`, and `actinotallow=open`.", "type": "string"}, "time":
{"description": "The seconds to wait. Required only by `actinotallow=long\_press` and `actinotallow=wait`.", "type": "number"}, "button": {"description": "Back means returning to the previous
interface, Home means returning to the desktop, Menu means opening the application
background menu, and Enter means pressing the enter. Required only by `actinotallow=system\
_button`", "enum": ["Back", "Home", "Menu", "Enter"], "type": "string"}, "status": {"
description": "The status of the task. Required only by `actinotallow=terminate`.", "type": "string", "
enum": ["success", "failure"]}}, "required": ["action"], "type": "object"}, "args\_format": "
Format the arguments as a JSON object."}}
</tools>
For each function call, return a json object with function name and arguments within <tool\_call></
tool\_call> XML tags:
<tool_call>
{"name": <function−name>, "arguments": <args−json−object>}
</tool_call>User:
复制The user query: [user_request] Current step query: low_lew_instruction (included only when low_lew_instruction is defined) Task progress (You have done the following operation on the current device): [history_actions] [current_screenshot]
Assistant:
复制[thought_and_action]
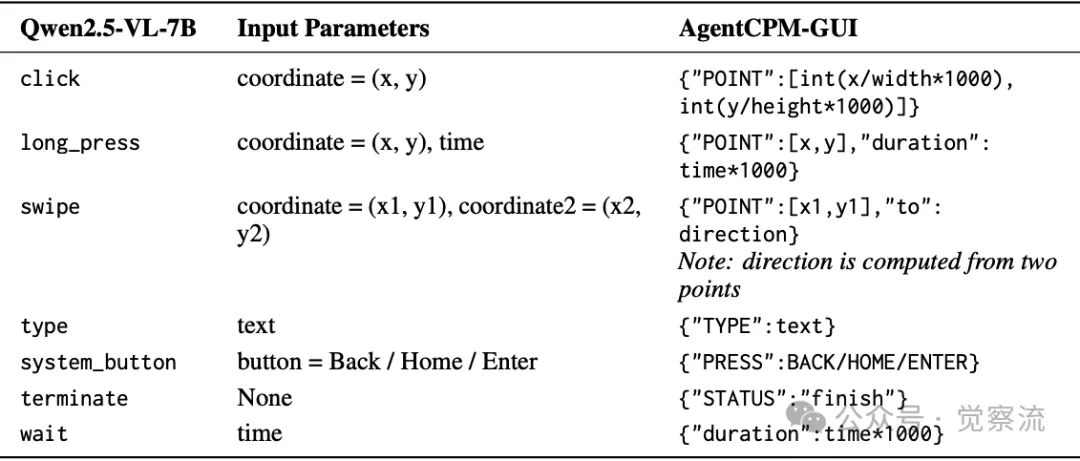
从Qwen2.5-VL-7B到AgentCPM-GUI的动作空间映射
上面提供了 Qwen2.5-VL-7B 模型的数据示例及动作空间映射到AgentCPM-GUI 的具体信息,为实践者在不同模型间动作空间转换时提供了参考。
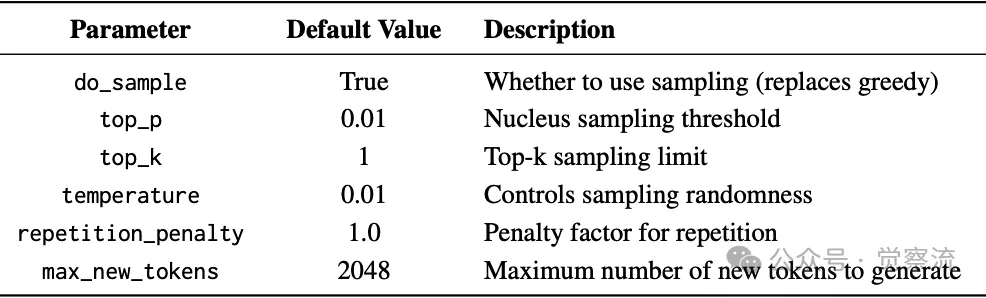
Qwen2.5-VL-7B的推理超参数
上表列出了 Qwen2.5-VL-7B 的推理超参数设置,这些信息对实践者在进行模型推理时的参数配置具有指导意义。
此外,团队还提供了 Hugging Face 推理与 vLLM 推理两种模式的代码示例,满足不同用户在不同场景下的需求。对于希望进一步定制与扩展模型功能的用户,开源代码中包含了模型微调的训练脚本与配置文件,详细说明了训练参数的调整方法与训练流程的控制方式,为深度开发提供了有力支持。(具体请见本文的参考资料开源部分)
AgentCPM-GUI:推动 GUI 智能体发展的重要一步
AgentCPM-GUI 创新性的渐进式训练方法、高质量数据集构建、紧凑动作空间设计以及强化微调策略,在多个基准测试中取得了卓越的性能表现,有力推动了多语言 GUI 智能体的发展进程。AgentCPM-GUI 的主要研究贡献可概括为以下几个方面:
1. 高质量中英文 Android 数据集的构建 :研发团队克服了数据收集与标注过程中的诸多困难,打造出包含 55K 轨迹、470K 步骤的大规模双语 Android 数据集。这一数据集涵盖了丰富的应用类型与操作场景,并且通过严格的质量控制流程确保数据的真实性和多样性,为 GUI 智能体的训练提供了宝贵的新资源,填补了现有数据集在中文 GUI 领域的空白。
2. 渐进式训练方法的提出 :创新性地设计了涵盖视觉感知预训练、监督微调以及强化微调三个阶段的渐进式训练流程。这一方法论体系使模型能够逐步学习从基础的视觉感知技能到复杂的推理规划能力,有效解决了纯模仿学习模型泛化能力差、推理能力弱的问题。通过各阶段训练目标的合理设置与训练数据的精心组织,模型在不同层次的任务执行能力上均得到显著提升,为 GUI 智能体的训练提供了一种高效且可扩展的范式。
3. 紧凑动作空间的设计与优化 :针对移动设备资源受限的特点,设计了一套精简高效的动空间表示方案。通过采用紧凑的 JSON 格式与合理的动作抽象层次,大幅减少了动作输出的长度与计算开销,提高了模型在边缘设备上的运行效率与响应速度。这一设计提升了模型的实际应用价值,也为后续动作空间的拓展与优化提供了良好的基础架构。
4. 多基准测试性能突破 :在 AndroidControl、GUI-Odyssey、AITZ 以及 CAGUI 等多个权威基准测试中,AgentCPM-GUI 取得了领先的成绩,特别是在中文 GUI 设置中表现出色,充分证明了其方法论与技术架构在多语言环境下的有效性与优越性。这些实验结果为 GUI 智能体技术的实用化与产品化提供了有力的性能背书,加速了相关技术从实验室走向实际应用的进程。
5. 开源推动研究生态发展 :作为首款开源的支持中英文应用的 GUI 智能体,AgentCPM-GUI 为全球研究人员与开发者提供了一个开放、共享的研究平台。通过开源模型训练评估代码、基准测试数据以及模型检查点,团队降低了 GUI 智能体研究的入门门槛,促进了知识共享与技术交流,激发了社区的创新活力,推动了多语言 GUI 智能体研究向更深层次发展。
我通读了 AgentCPM-GUI 的研究成果以后,给我的感受就是,AgentCPM-GUI 对 Agent 在 RFT 上的流程太有示范作用了,给了我非常好的学习案例。在当下移动设备已成为我们生活与工作的延伸,AgentCPM-GUI 让我们看到了 AI 如何从Paper走向实践,如何从实验室的创新转化为提升应用 productivity 与 accessibility 的实际工具。它在多语言支持上的突破,打破了语言的隔阂,为全球不同地区的用户带来了同等便捷的智能交互体验。
从技术层面来看,AgentCPM-GUI 的渐进式训练方法论给我留下了深刻的印象。这从感知到行动、再到推理的分阶段学习策略,平衡了模型在不同能力维度上的发展需要。这种设计理念适用于 GUI 智能体,同时也可以为其他AI应用的开发提供非常宝贵借鉴,要感谢开源呀。
另外,AgentCPM-GUI 紧凑动作空间的设计,在移动设备资源受限的现实条件下,通过优化动作表示方式来提升运行效率,这种兼顾性能与实用性的思维,正是推动技术 GUI Agent 在端侧落地的关键。它提醒我们在追求技术卓越的同时,要对用户需求与使用环境做深刻洞察。在移动设备上,资源有限是一个不可忽视的现实问题。因此,如何在保证功能完整性的前提下,尽可能地减少计算开销和资源占用,也是我们在设计 GUI Agent 时需要重点考虑的。
还有 AgentCPM-GUI 的局限性,比如,泛化能力的瓶颈这种踩坑经验的分享非常宝贵。AgentCPM-GUI 真是值得深度研究的开源案例。


