在智能体强化学习的快速发展中,如何在探索与稳定之间取得平衡已成为多轮智能体训练的关键。主流的熵驱动式智能体强化学习(Agentic RL)虽鼓励模型在高不确定性处分支探索,但过度依赖熵信号常导致训练不稳、甚至策略熵坍塌问题。
为此,中国人民大学高瓴人工智能学院与快手 Klear 语言大模型团队联合提出 Agentic Entropy-Balanced Policy Optimization(AEPO),一种面向多轮智能体的熵平衡强化学习优化算法。
AEPO 系统性揭示了「高熵 Rollout 采样坍缩」和「高熵梯度裁剪」问题,并设计了「动态熵平衡 Rollout 采样」与「熵平衡策略优化」两项核心机制。前者通过熵预监控与连续分支惩罚实现全局与局部探索预算的自适应分配,后者在策略更新阶段引入梯度停止与熵感知优势估计以保留高熵 token 的探索梯度。
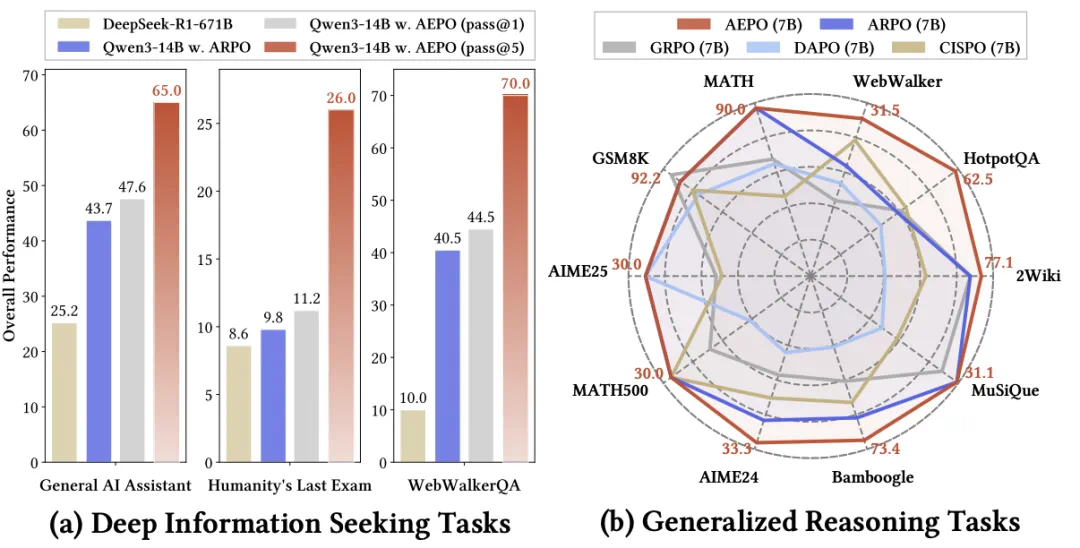
图 1:AEPO 性能概览:左图对比深度搜索任务性能,右图对比通用推理任务性能
实验结果表明,AEPO 在 14 个跨领域基准上显著优于七种主流强化学习算法。特别是深度搜索任务的 Pass@5 指标:GAIA (65.0%), Humanity’s Last Exam (26.0%), WebWalkerQA (70.0%)。在保持训练稳定性的同时进一步提升了采样多样性与推理效率,为通用智能体的可扩展强化训练提供了新的优化范式。

论文标题:Agentic Entropy-Balanced Policy Optimization
论文链接:https://arxiv.org/abs/2510.14545
代码仓库:https://github.com/dongguanting/ARPO
开源数据 & 模型:https://huggingface.co/collections/dongguanting/aepo-68ef6832c99697ee03d5e1c7
目前 AEPO 在 X 上收获极高关注度,Github 仓库已获星标 700 余枚,同时荣登 Huggingface Paper 日榜第二名!

研究动机:在高熵中寻求平衡
随着 Agentic RL 的发展,如何在持续探索与训练稳定之间取得平衡已成制约智能体性能的关键。现有方法(如 ARPO)通常依赖熵信号作为依据,并在高熵时刻触发分支采样探索潜在推理路径。我们的研究发现熵驱动的探索虽能提升多样性,却也带来了显著的训练不稳定:模型在连续高熵的工具调用阶段容易出现单一链条过度分支,导致探索受限(如下图左侧);同时在策略更新阶段,高熵 token 的梯度常被无差别裁剪,使模型难以学习的探索行为(如下图右侧)。这种熵失衡也使智能体在强化学习中容易陷入局部最优解。
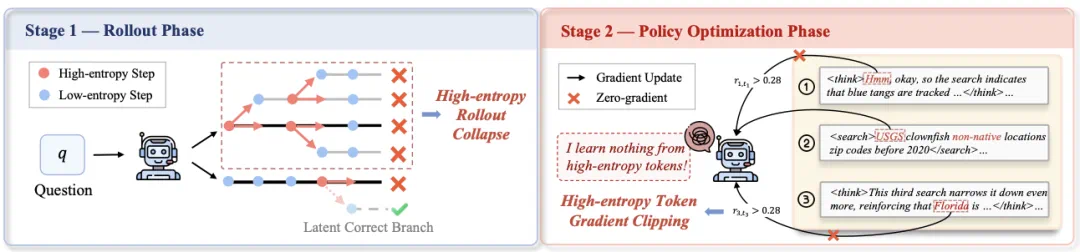
图 2:智能体中的高熵 Rollout 坍缩与高熵梯度裁剪现象
因此,如何在高熵驱动下同时实现高效探索与稳定优化,成为智能体强化学习亟待突破的核心瓶颈。为此,我们提出 AEPO,一种面向多轮智能体的熵平衡强化学习优化算法。我们的贡献如下:
我们系统性分析并揭示了现有熵驱动的 Agentic RL 在高熵阶段易出现的「rollout 坍缩」和「梯度裁剪」问题,为后续算法设计提供了经验与理论依据。
我们提出了 AEPO 算法,旨在通过「动态熵平衡 Rollout 采样」与「熵感知策略优化」两个阶段实现强化学习探索与稳定的协同优化。
在 14 个挑战性基准上的实验结果表明,AEPO 在采样多样性、训练稳定性及工具调用效率方面均优于 7 种主流强化学习算法,为智能体在复杂开放环境下的可扩展训练提供了新的启发。
工具调用的熵变现象:高熵集聚与梯度困境
通过分析智能体在多轮工具调用强化学习中的 token 熵变与训练过程,我们发现以下核心现象:
高熵工具调用步骤存在连续性:连续的高熵工具调用轮次占比达 56.5%,部分轨迹甚至出现 6 次连续高熵调用,这种连续性导致 rollout 阶段的分支预算分配严重倾斜(如下图左侧);
高熵 Token 梯度裁剪:传统 Agentic RL 算法在策略更新阶段存在「无差别梯度裁剪」问题,未区分其是否包含有价值的探索行为,这些 token 大多是在推理中激发工具调用,反思等行为的提示(如下图右侧)。
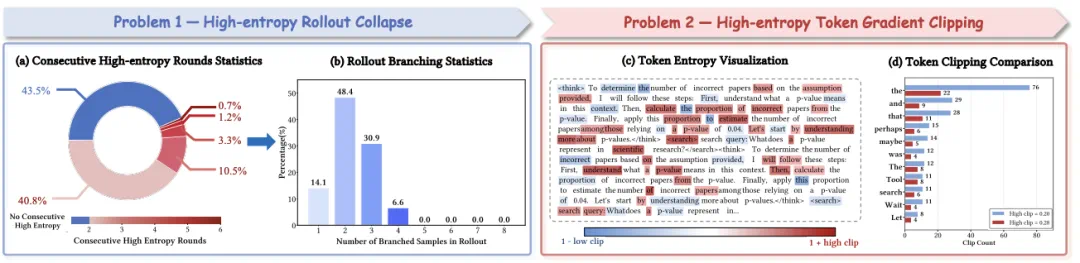
图 3:智能体强化学习训练中两种熵相关问题的量化统计
上述现象本质是高熵信号的双重矛盾:高熵是智能体探索工具使用潜力的必要条件,但无约束的高熵连续性会破坏 rollout 资源分配,激进的梯度裁剪又会扼杀高熵的探索价值。
AEPO 算法:熵驱动的精准探索与梯度保护
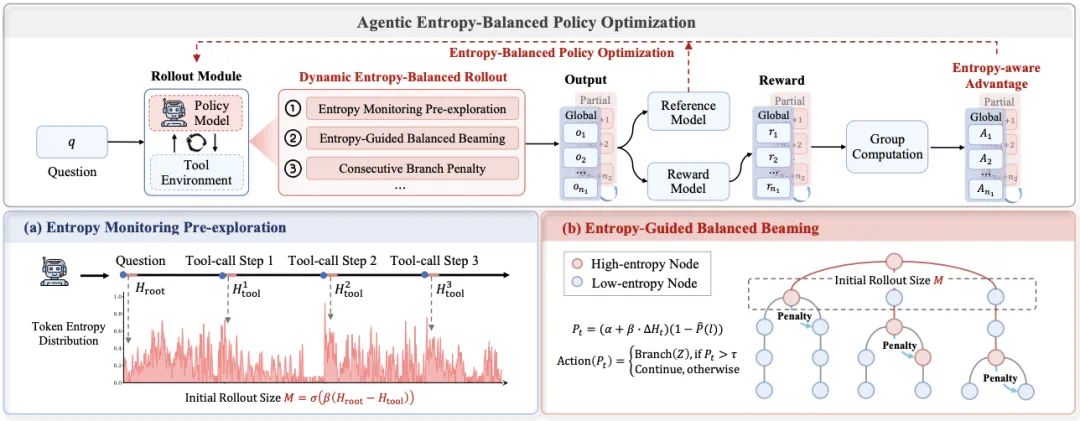
图 4:AEPO 概述
动态熵平衡 Rollout 采样:
1.熵预监测:按信息增益分配采样预算
传统 RL 算法(如 ARPO)凭经验分配全局采样与分支采样的坍缩资源,AEPO 则基于信息增益理论,根据问题与工具的信息增益动态调整采样预算,具体来说,在总 rollout 采样的预算为 k(包含 m 次全局采样与 k-m 次高熵分支采样)的条件下,将 Rollout 阶段的信息增益简单地建模为:
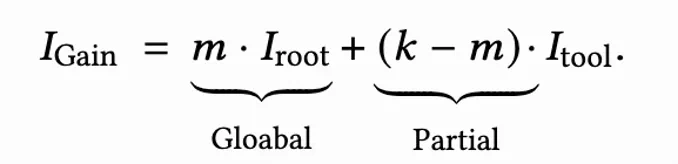
在语言模型的自回归解码过程中,输入问题的信息增益通常由模型解码的 token 熵值来衡量,因此我们可以得到如下正相关关系:

因此,我们的目标是尽可能增大 Rollout 阶段的信息增益,基于上述公式,AEPO 按信息增益分配采样预算:
首先让模型预生成 1 条完整工具调用轨迹,以监控问题初始熵
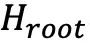 与工具调用平均熵
与工具调用平均熵 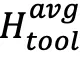 ;
;若
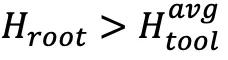 (即问题本身不确定性更高):增加全局采样数量 m,多探索不同完整轨迹;
(即问题本身不确定性更高):增加全局采样数量 m,多探索不同完整轨迹;若
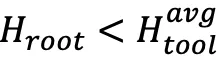 (即工具反馈不确定性更高):减少「全局采样数量」,将预算向分支采样 k-m 倾斜,聚焦高熵工具步骤的局部探索。
(即工具反馈不确定性更高):减少「全局采样数量」,将预算向分支采样 k-m 倾斜,聚焦高熵工具步骤的局部探索。
我们的最终预算分配公式: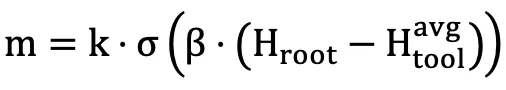 ,其中 σ 为 sigmoid 函数(确保 m 在 0-k 之间),β 控制熵差异敏感度,k 为总采样预算。这一设计让资源分配有理论支撑。
,其中 σ 为 sigmoid 函数(确保 m 在 0-k 之间),β 控制熵差异敏感度,k 为总采样预算。这一设计让资源分配有理论支撑。
2.连续高熵分支惩罚:避免单一轨迹过度分支
即使预算分配合理,连续高熵调用仍可能导致单一轨迹过度分支。因此 AEPO 通过动态分支概率施加惩罚:
实时监测每步工具调用后的熵变化:
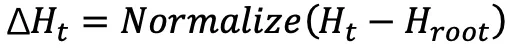 ;
;追踪每条轨迹的「连续高熵分支次数
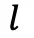 」,分支概率公式:
」,分支概率公式: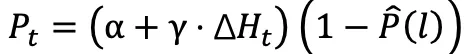 ,其中惩罚概率
,其中惩罚概率 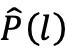 与
与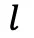 正相关;
正相关;分支决策规则:若
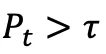 (预设阈值),则对当前步骤分支(生成 Z 条子轨迹);否则继续当前轨迹,并累计连续高熵次数(
(预设阈值),则对当前步骤分支(生成 Z 条子轨迹);否则继续当前轨迹,并累计连续高熵次数(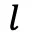 +1)。
+1)。
实验验证:如下图所示,相比于 ARPO 通常仅分支 2-3 条轨迹,而 AEPO 可覆盖全部 8 条预算轨迹(右图),采样聚类数从 54 提升至 62(左 2 图),大幅提升 Rollout 采样的多样性。
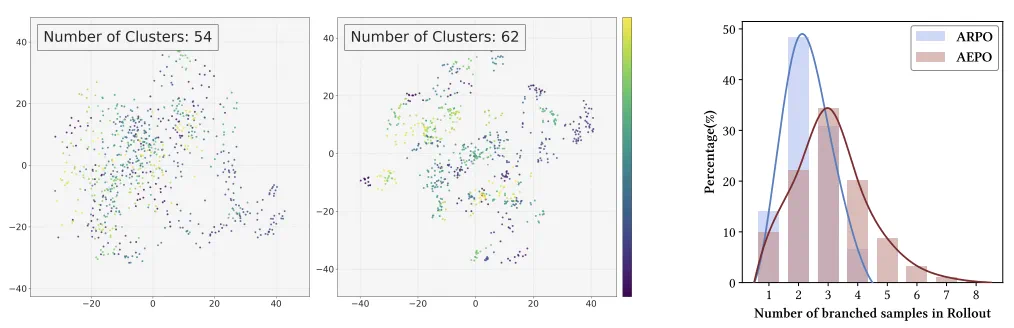
图 5:采样多样性 ARPO vs AEPO(左)与 Rollout 的分支采样分布(右)
熵平衡策略优化:
1.熵裁剪平衡机制:保留高熵 Token 梯度
收到 GPPO 启发,AEPO 将「梯度停止」操作融入到策略更新的高熵裁剪项中,保证了前向传播不受影响,同时保护了高熵 token 的梯度在反向传播时不被裁剪。AEPO 在策略更新时使用如下公式:
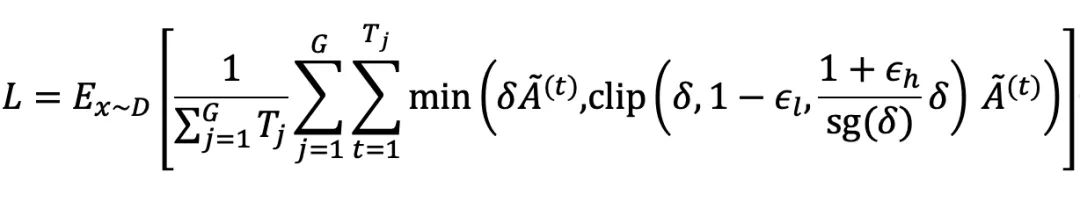
其中,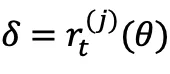 表示重要性采样比率,
表示重要性采样比率,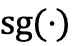 表示「梯度停止」操作。值得注意的是,
表示「梯度停止」操作。值得注意的是,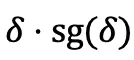 的值始终为 1,从而确保了 AEPO 的前向传播不变。在反向传播过程中,AEPO 的梯度更新公式为:
的值始终为 1,从而确保了 AEPO 的前向传播不变。在反向传播过程中,AEPO 的梯度更新公式为:
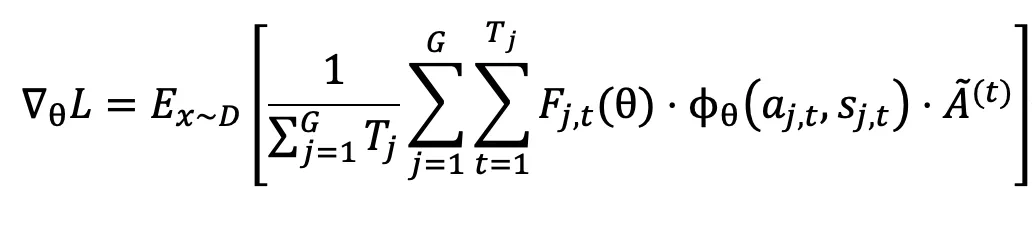
其中,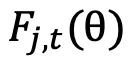 的定义如下:
的定义如下:
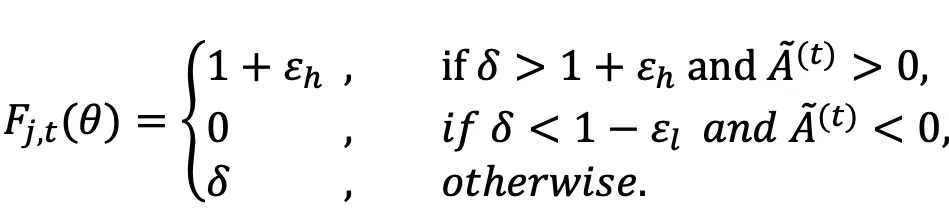
这一设计让高熵探索性 Token 的梯度得以保留,避免训练初期探索能力流失。
2.熵感知优势估计:优先学习高价值探索行为
不同于仅考虑准确率优势的传统 RL 算法,AEPO 引入熵优势 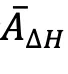 ,构建融合优势函数,让模型优先学习高熵且对任务有贡献的 token:
,构建融合优势函数,让模型优先学习高熵且对任务有贡献的 token:
准确率优势
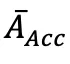 :基于轨迹最终奖励(如答案准确率)的标准化值,计算方式为
:基于轨迹最终奖励(如答案准确率)的标准化值,计算方式为 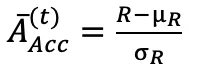 (
(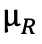 为奖励均值,
为奖励均值,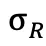 为奖励标准差),反映 token 对答案正确性的贡献;
为奖励标准差),反映 token 对答案正确性的贡献;熵优势
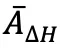 :基于当前 Token 熵与轨迹平均熵的差异,计算方式为
:基于当前 Token 熵与轨迹平均熵的差异,计算方式为 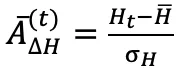 (
(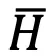 为轨迹平均熵,
为轨迹平均熵,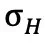 为熵值标准差),反映 token 的探索不确定性;
为熵值标准差),反映 token 的探索不确定性;融合优势:
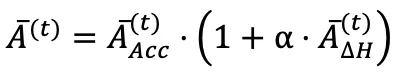 ,其中 α 为熵优势权重(实验中设为 0.3),确保高熵 token 在「对任务有贡献」时能获得更高优势值,引导模型重点学习。
,其中 α 为熵优势权重(实验中设为 0.3),确保高熵 token 在「对任务有贡献」时能获得更高优势值,引导模型重点学习。
实验结果:14 个基准验证 AEPO 的高效与稳定
为了充分评估 AEPO 的泛化性和高效性,我们考虑以下三种测试集:
计算型推理任务:评估模型的计算推理能力,包括 AIME24、AIME25、MATH500、GSM8K、MATH。
知识密集型推理任务:评估模型结合外部知识推理的能力,包括 WebWalker、HotpotQA、2WIKI、MisiQue、Bamboogle。
深度搜索任务:评估模型的深度搜索能力,包括 HLE、GAIA、SimpleQA、XBench、Frames。
深度信息检索任务:小样本实现大突破
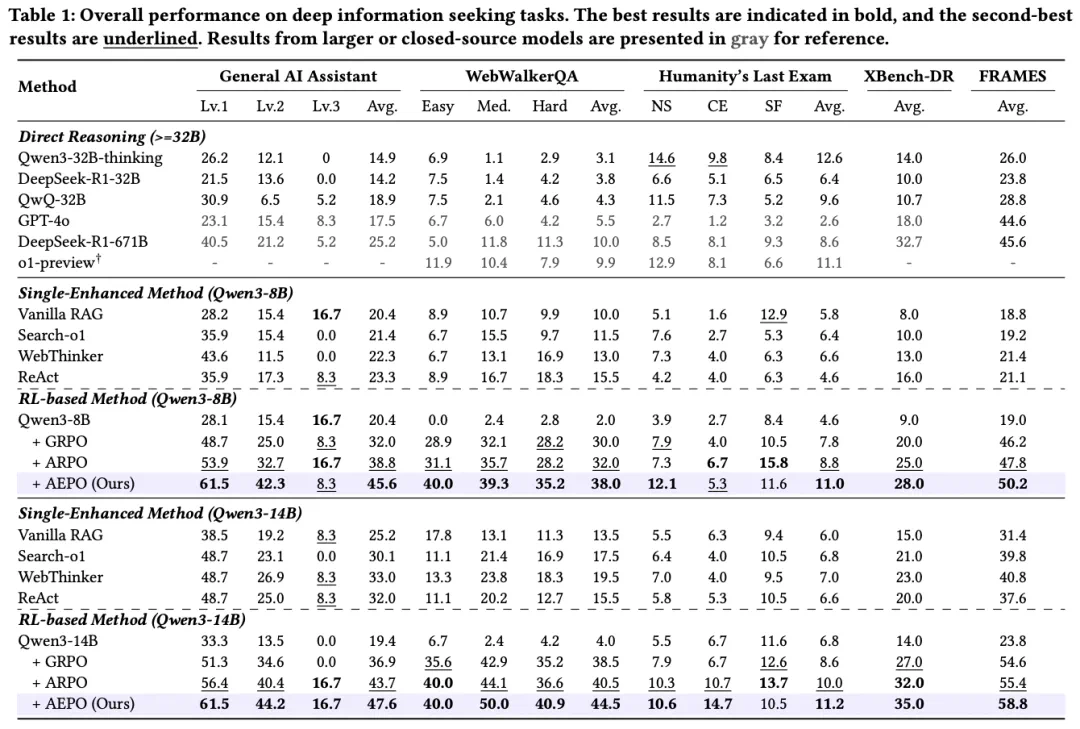
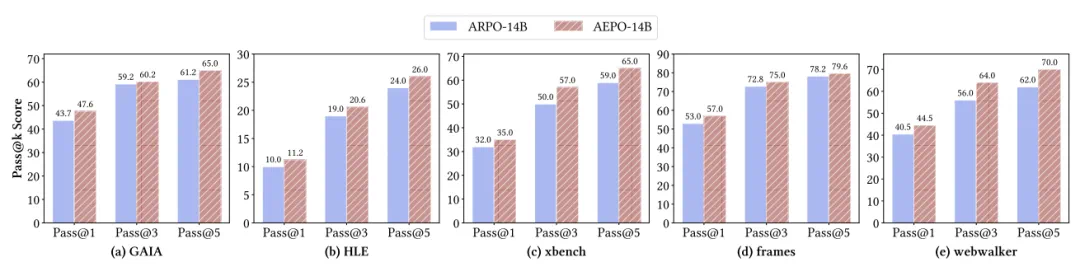
如上表所示,仅用 1K RL 训练样本,Qwen3-14B+AEPO 在关键任务上表现优异:
AEPO 在 Pass@1 上较 ARPO 平均提升 3.9%;在 Pass@5 上较 ARPO 平均提升 5.8%;
对比梯度裁剪优化 RL 算法(DAPO、CISPO、GPPO):AEPO 在 GAIA 任务上领先 7%-10%,在 Qwen3-14B 基座上取得了 47.6% 的 Pass@1 与 65% 的 Pass@5,这证明熵平衡机制优于单纯的梯度裁剪优化 RL 算法;
对比传统 RL(GRPO、Reinforce++):AEPO 在 HLE 任务上领先 2.6%-3.4%,在 Qwen3-14B 基座上取得了 11.2% 的 Pass@1 与 26% 的 Pass@5,凸显 Agentic RL 中熵平衡的必要性。
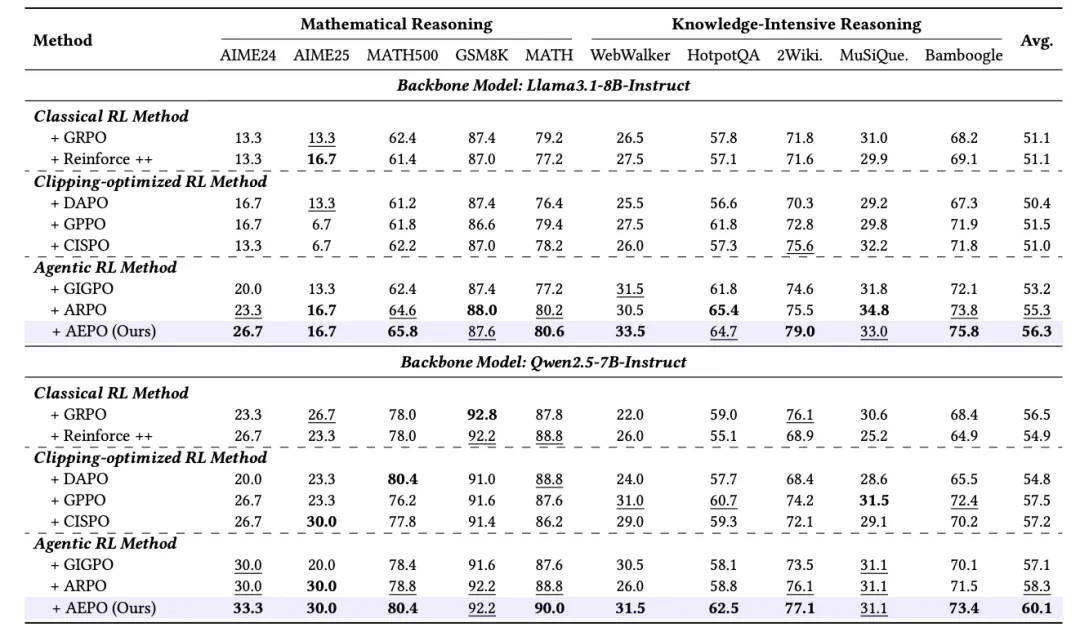
我们比较了 7 种强化学习算法在 10 个推理任务中的表现,发现:
梯度裁剪优化算法的稳定性差:在 Qwen 2.5-7B-instruct 上,梯度裁剪优化算法表现良好,但在 Llama3-8B 上未显著优于 GRPO,且易导致熵崩溃。
Agentic RL 算法具备泛化能力:ARPO,GIGPO,AEPO 等算法在不同模型上表现稳定,证明在高熵环境下的分支探索有效。
AEPO 优势显著:AEPO 在所有测试中表现突出,一致性高于 7 种主流 RL 算法。并且平均准确率比 GRPO 高 5%,更适合训练多轮次 Web 智能体。
实验:熵稳定与准确率分析
在 Agentic RL 训练中,熵动态稳定性与训练准确率收敛性是衡量算法有效性的核心指标:熵过高易导致探索失控,熵过低则会引发探索不足;而准确率的持续提升则直接反映模型对有效工具使用行为的学习能力。
我们对比 AEPO 与主流 RL 算法(含 ARPO、GRPO、DAPO 等)在 10 个推理任务中的训练动态,清晰揭示了 AEPO 在「熵稳定」与「准确率提升」双维度的优势。实验发现训练的熵损失骤增与下降都不会对性能带来增益;相比之下,AEPO 的熵损失全程维持高且稳定,对应稳定的性能增益。其表现远超其他 RL 算法,且解决了 ARPO 在训练后期熵波动的问题。
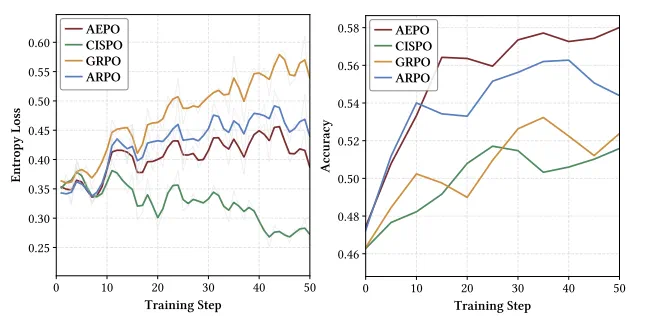
图 5:训练指标可视化,包括各训练步骤的熵损失(左)和准确率(右)
总结与未来展望
未来可从三个方向进一步拓展:
多模态 Agent:当前 AEPO 与 ARPO 均聚焦文本任务,未来可扩展至图像、视频等多模态输入,探索多模态工具的熵平衡优化,解决多模态反馈带来的熵波动问题。
工具生态扩展:引入更复杂工具(如 MCP 服务、外部订机票酒店服务调用、代码调试器),基于 AEPO 的熵感知机制优化多工具协作策略,提升复杂任务表现,超越现有工具协作能力。
多智能体强化学习:探索在更多智能体的协作学习,互相任务交互与博弈中找到平衡,实现收敛。
作者介绍
董冠霆目前就读于中国人民大学高瓴人工智能学院,博士二年级,导师为窦志成教授和文继荣教授。他的研究方向主要包括智能体强化学习、深度搜索智能体,大模型对齐等。在国际顶级会议如 ICLR、ACL、AAAI 等发表了多篇论文,并在快手快意大模型组、阿里通义千问组等大模型团队进行实习。其代表性工作包括 ARPO、AUTOIF、Tool-Star、RFT、Search-o1、WebThinker、Qwen2 和 Qwen2.5 等。
个人主页:dongguanting.github.io
本文的通信作者为中国人民大学的窦志成教授与快手科技的周国睿。