
大家好,我是肆〇柒。我前几天就看到这么一篇论文关于 AdaptThink。它主要讲的是如何通过强化学习,来实现Reason Model(推理模型如o1,R1)根据问题难度自适应选择思考模式(思考或不思考),以优化推理质量和效率的平衡。也就是快思考和慢思考的模型自适应。这篇论文让我关注到它的原因在于,它所提出来的研究范围,刚好是我曾经的又一个预判。(我猜我一定不会是独家)
因为 AI 可以自适应快慢思考系统,并且可以自己定义思考预算(实现思考长短分级),这才是接近人类思考的样子,这也理应是技术应该进化发展的方向。可以假设一下,当面对一个简单的数学问题时,传统模型可能会花费大量时间进行不必要的思考,而 AdaptThink 能够迅速判断问题的难度,并直接给出简洁的答案。这种智能的自适应机制,不仅节省了计算资源,还为用户带来了更高效、更精准的体验。接下来,我们一起了解一下 AdaptThink 的原理。
在 AI 领域,大型推理模型(如 OpenAI o1、DeepSeekR1 等)通过模拟人类的深度思考,在解决复杂任务时取得了显著成果。然而,这一 lengthy thinking process 也带来了推理开销大幅增加的问题,成为效率提升的关键瓶颈。尤其是在处理简单任务时,模型生成过多冗余思考步骤,导致用户体验不佳。例如,传统推理模型面对一个简单的加法问题,可能会花费数百个 token 进行反复的思考探索,而 AdaptThink 能迅速判断其简单性,直接输出简洁的最终答案,节省大量计算资源和时间,为用户提供了一个高效精准的解决方案。
为解决这一问题,AdaptThink,作为一种新的强化学习(RL)思路,可使推理模型依据问题难度自适应选择 optimal thinking mode,平衡推理质量和效率。
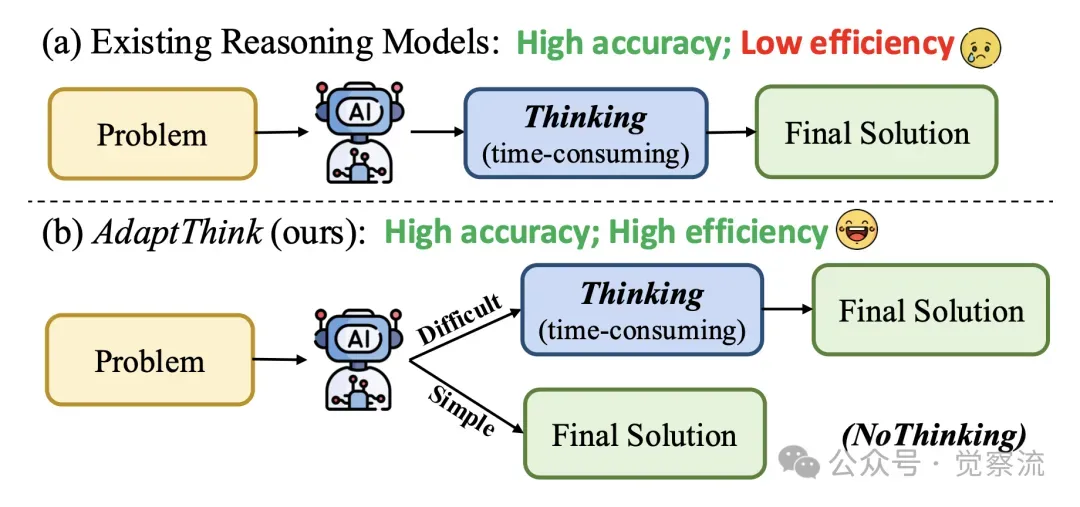
AdaptThink 使模型能够根据问题难度自适应地选择思考模式或非思考模式,从而提高推理效率,同时进一步提升整体性能
研究背景与动机
NoThinking 方法的提出为这一困境提供了新的解决思路。该方法通过 prompt 为空的思考片段(即 “<think></think>”)让推理模型跳过思考过程,直接生成最终解决方案。研究表明,在相对简单问题(如高中竞赛水平及以下)上,NoThinking 的性能与 Thinking 模式相当甚至更优,且能显著减少 token 使用量。只有在问题足够难时,Thinking 的优势才会凸显。
NoThinking 方法的简化主要体现在 prompt 的设计上。传统的 NoThinking 方法通过一个固定的 prompt “Okay, I think I have finished thinking.</think>” 来引导模型跳过思考过程。然而,这种 prompt 在实际应用中可能会带来一定的局限性,例如在不同语言或领域的问题中可能需要额外的适配。
为此,研究者们提出了一种更加简洁和通用的 prompt 设计,即使用一个空的思考片段 “<think></think>”。这种简化后的 prompt 不仅减少了对特定语言和领域的依赖,还提高了模型的通用性和适应性。通过实验验证,简化后的 NoThinking 方法在保持性能优势的同时,进一步降低了 token 使用量,提高了推理效率。
基于这一发现,研究者们提出了关键问题:能否让推理模型基于输入问题的难度,自适应选择 Thinking 或 NoThinking 模式,以实现更高效的推理且不牺牲甚至提升性能?从而引出了 AdaptThink 算法。
AdaptThink 算法探索
约束优化目标
AdaptThink 的核心目标是鼓励模型选择 NoThinking 模式,同时确保整体性能不降低。具体而言,给定一个推理模型 πθ 和数据集 D,以及一个参考模型 πθref(初始 πθ,训练过程中保持不变),定义奖励函数 R(x, y, y∗ ) 衡量模型响应 y 的正确性(对于数学问题求解,R(x, y) 返回 0/1 表示 y 错误 / 正确)。引入指示函数 1(y1 =</think>) 判断 y 是否为 NoThinking 响应(即首个 token 为 </think>)。

重要性采样策略
在 on-policy training 初始阶段,模型 πθ 自然地对所有问题应用 Thinking 模式,导致无法从 πθold 采样到 NoThinking 样本。为解决这一冷启动挑战,AdaptThink 引入重要性采样技术,定义新的分布 πIS(·|x):
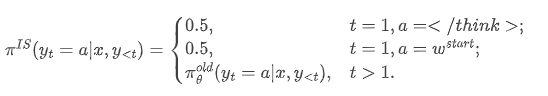
其中,wstart 为开始 long thinking 的常用词(如 “Alright”)。训练时,从 πIS(·|x) 采样响应,使得每个 batch 中一半样本为 Thinking 模式,另一半为 NoThinking 模式。这使模型从训练伊始就能学习两种模式,并在整个训练过程中保持探索和利用两种思考模式的机会,避免模型过早固定于单一模式。
算法流程总结
AdaptThink 算法的整体流程如下(参考 Algorithm 1):
复制**Algorithm 1 AdaptThink**
Input: policy model πθ; dataset D; hyperparameters K, δ, ϵ
Initialize: reference model πθref ← πθ
1: Sample K responses {y′i}K i=1 ∼ πθref(·|x) and calculate ¯Rref(x) for each x ∈ D (Equation 5)
2: for step = 1, . . . , M do
3: Update the old policy model πθold ← πθ and importance sampling distribution πIS (Equation 8)
4: Sample a batch Db from D
5: Sample K responses {yi}K i=1 ∼ πIS(·|x) for each x ∈ Db and estimate LAT(θ) (Equation 9. Half of yi are Thinking responses and the other half are NoThinking responses.)
6: Update the policy model πθ by minimizing LAT(θ)
7: end for
Output: πθ以上伪算法释义如下:
算法 1 AdaptThink输入:策略模型 πθ;数据集 D;超参数 K, δ, ϵ初始化:参考模型 πθref ← πθ1: 对每个 x ∈ D,采样 K 个响应 {y′i}K i=1 ∼ πθref(·|x),计算 Rref(x)(公式 5)2: for step = 1, ..., M do3: 更新旧策略模型 πθold ← πθ,更新重要性采样分布 πIS(公式 8)4: 从 D 中采样一批 Db5: 对每个 x ∈ Db,从 πIS(·|x) 采样 K 个响应 {yi}K i=1,估计 LAT(θ)(公式 9,其中一半 yi 为 Thinking 响应,另一半为 NoThinking 响应)6: 通过最小化 LAT(θ) 更新策略模型 πθ7: end for
输出:πθ
实验设计与结果分析
实验设置
实验选用 DeepSeek-R1-Distill-Qwen1.5B 和 DeepSeek-R1-Distill-Qwen-7B 作为初始策略模型。训练数据集为 DeepScaleR,包含 40K 道数学题,涵盖 AIME 1983-2023、AMC、Omni-Math 和 STILL 数据集。评估使用的三个数学数据集 GSM8K(1319 道小学数学题)、MATH500(500 道高中竞赛数学题)和 AIME2024(30 道奥林匹克数学题)难度递进。评估指标包括准确率(accuracy)和响应长度(response length),并报告所有测试数据集上的平均准确率变化和平均长度减少率。
实验基于 VeRL 框架实现,训练上下文大小、批次大小、学习率等参数分别设置为 16K、128 和 2e-6。超参数 K、δ、ϵ 分别设为 16、0.05 和 0.2。为公平比较,所有基线方法均使用 DeepScaleR 数据集重新实现。
基线方法对比
与 AdaptThink 对比的基线方法包括 DPOShortest、OverThink、DAST、O1-Pruner、TLMRE、ModelMerging 和 RFTMixThinking 等。每种方法的核心思想如下:
- DPOShortest:通过采样多个响应,配对最短正确响应和最长响应,使用 DPO 算法微调模型。
- OverThink:以原始长思考响应为负例,保留思考中首次正确解答的前两次尝试为正例,使用 SimPO 算法微调模型。
- DAST:通过基于长度的奖励函数对预采样响应排序,使用 SimPO 算法微调模型。
- O1-Pruner:预采样估计参考模型性能,使用离策略 RL 式微调,在准确率约束下鼓励模型生成更短推理过程。
- TLMRE:在 on-policy RL 中引入基于长度的惩罚项,激励模型生成更短响应。
- ModelMerging:通过加权平均推理模型与非推理模型的权重,减少推理模型的响应长度。
- RFTMixThinking:对每个训练问题 x,分别以 Thinking 和 NoThinking 采样多个响应,选择正确 NoThinking 响应(若其实例级通过率 ≥ Thinking)或正确 Thinking 响应,用这些响应微调模型。
主要实验结果
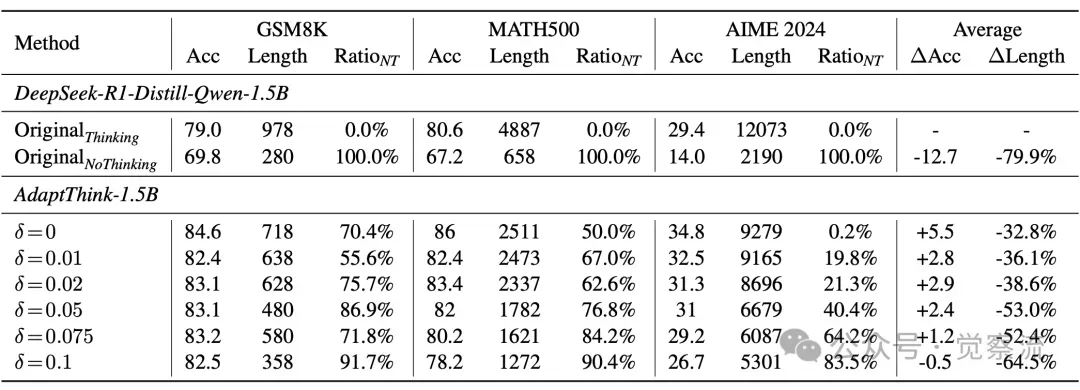
下表展示了不同方法在 GSM8K、MATH500 和 AIME2024 数据集上的准确率、响应长度以及 NoThinking 响应占比等关键指标结果。AdaptThink 在降低推理成本和提升模型性能方面表现突出,相比原始模型和其他基线方法具有明显优势。
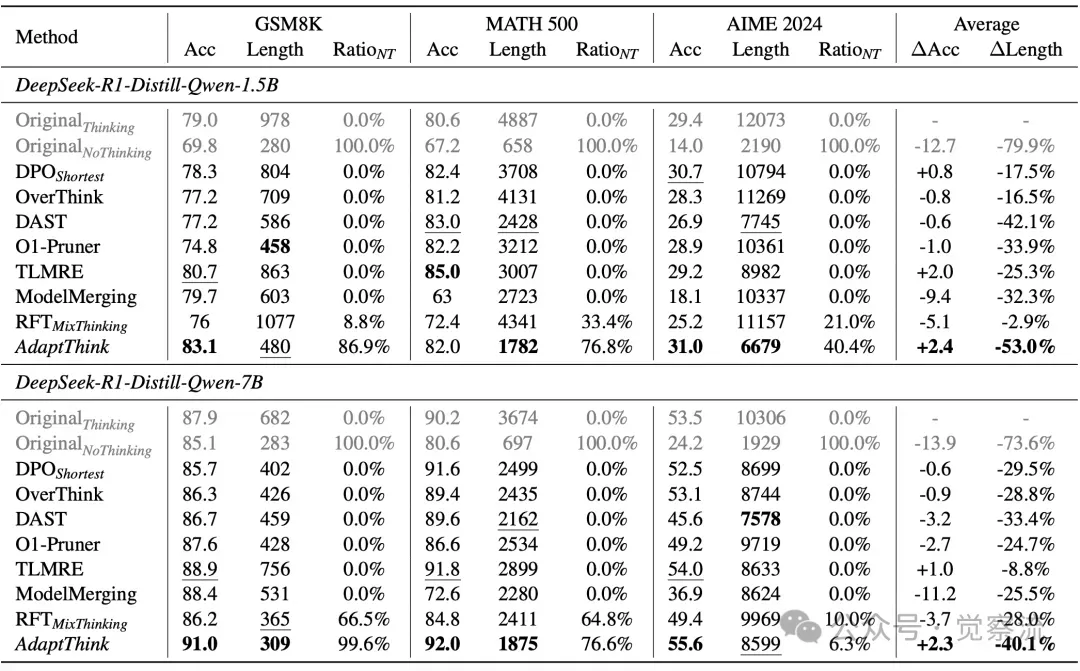
以 DeepSeek-R1-Distill-Qwen-1.5B 为例,AdaptThink 将平均响应长度降低了 53.0%,同时平均准确率提升了 2.4%。在 GSM8K 数据集上,AdaptThink 的准确率达到 83.1%,响应长度缩短至 480,NoThinking 响应占比达 86.9%;在 MATH500 数据集上,准确率为 82.0%,响应长度 1782,NoThinking 响应占比 76.8%;在 AIME2024 数据集上,准确率为 31.0%,响应长度 6679,NoThinking 响应占比 40.4%。
对于 DeepSeek-R1-Distill-Qwen-7B,AdaptThink 同样表现出色,平均响应长度降低了 40.1%,平均准确率提升了 2.3%。在 GSM8K 数据集上,准确率 91.0%,响应长度 309,NoThinking 响应占比 99.6%;在 MATH500 数据集上,准确率 92.0%,响应长度 1875,NoThinking 响应占比 76.6%;在 AIME2024 数据集上,准确率 55.6%,响应长度 8599,NoThinking 响应占比 6.3%。
AdaptThink 在简单数据集(如 GSM8K 和 MATH500)中生成更多 NoThinking 响应,而在挑战性数据集(如 AIME2024)中更多使用 Thinking 模式,且在大多数难度级别上一致性地取得更高准确率,论证了其自适应选择思考模式的有效性。

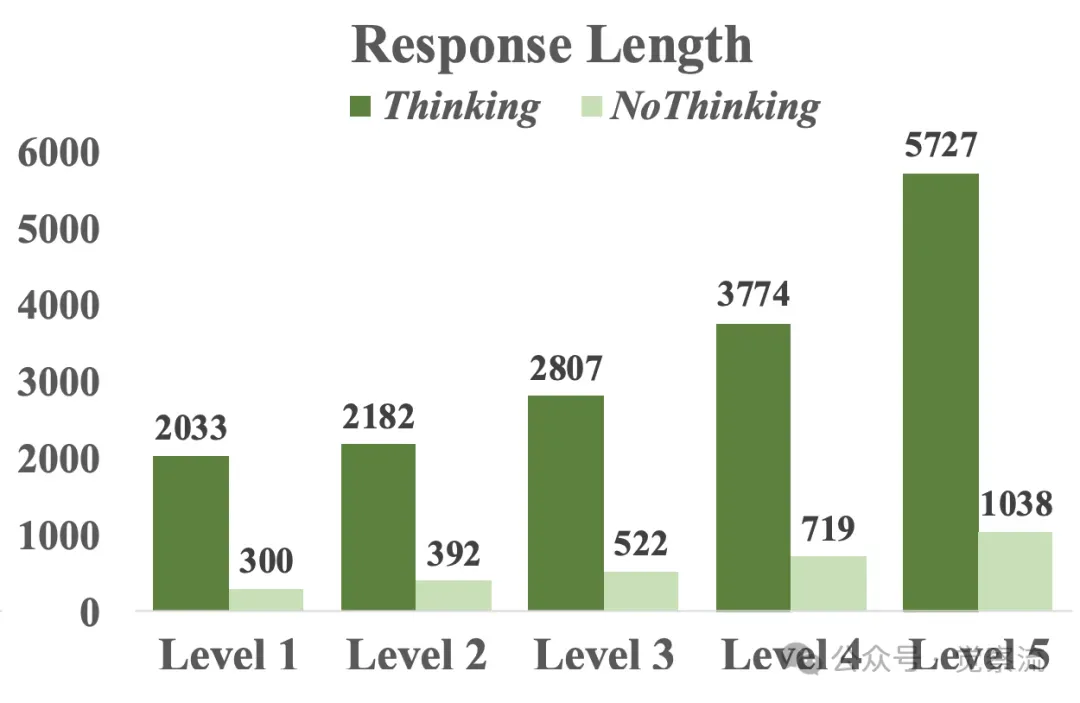
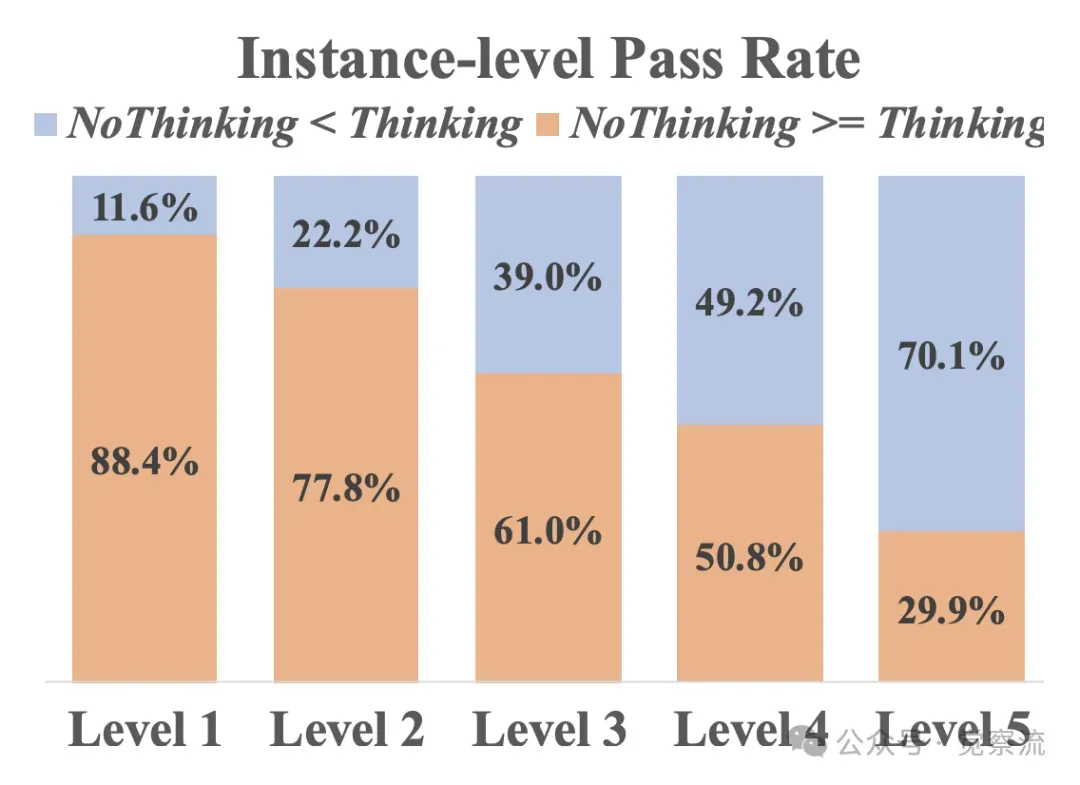
使用“思考模式”和“无思考模式”对DeepSeek-R1-Distill-Qwen-7B在MATH500数据集不同难度级别上的比较
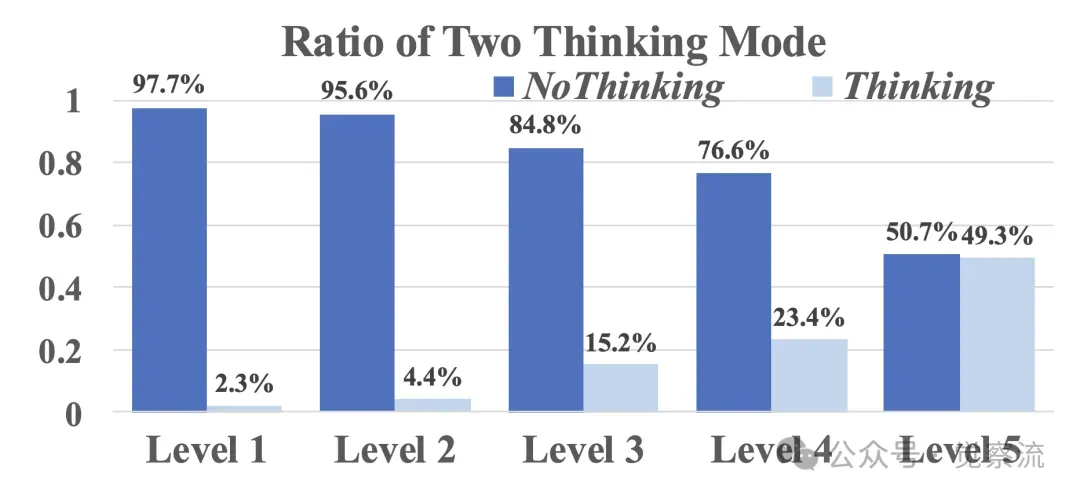
AdaptThink-7B在不同数学水平下选择思考或不思考的比例
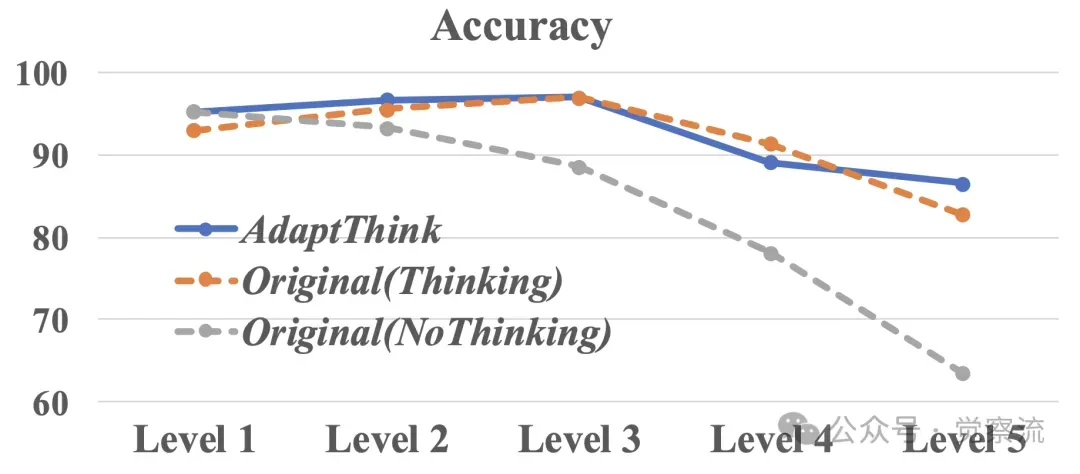
不同数学水平下,使用“思考”和“不思考”模式时AdaptThink-7B与DeepSeek-R1-Distill-Qwen-7B的准确率比较
AdaptThink 在不同难度级别问题上的性能差异主要源于其自适应选择 thinking 模式的能力。对于简单问题,模型倾向于选择 NoThinking 模式以节省推理资源;而对于复杂问题,模型则会自动切换到 Thinking 模式以确保准确性。这种自适应机制使得 AdaptThink 能够在不同的问题难度上实现最优的推理效率和性能平衡。
对于简单问题,NoThinking 模式的优势在于其能够直接跳过冗长的思考过程,快速生成简洁的最终答案。这得益于模型在训练过程中对简单问题特征的学习和识别,使其能够在早期阶段就确定问题的难度并选择合适的推理策略。而对于复杂问题,Thinking 模式则通过多步推理和探索,逐步逼近正确答案,从而保证了模型的准确性。
更多分析
δ 参数的影响
通过在 1.5B 模型上实施不同 δ 值的 AdaptThink 实验,分析 δ 增加对 NoThinking 响应比例、平均响应长度以及准确率的影响。结果表明,随着 δ 增大,NoThinking 响应比例逐步上升,平均响应长度相应减少,但准确率提升逐渐放缓。这说明 δ 在推理效率和准确率提升间起到了权衡作用。即使 δ=0 时,模型在 GSM8K 和 MATH500 中超过 50% 的问题选择 NoThinking,表明 NoThinking 在简单问题上具有潜在优势。
重要性采样的效果
对比 AdaptThink 与直接从 πθold(·|x) 采样的 naive GRPO 在训练过程中准确率、响应长度和 NoThinking 响应比例的变化。由于初始 πθold 无法生成 NoThinking 样本,GRPO 只能从 Thinking 样本中学习,导致其响应长度仅能减少到约 3500(通过消除过长响应),随后逐渐增加。而 AdaptThink 的重要性采样策略使模型在训练初期就能从两种模式中学习,随着模型逐渐学会为简单问题生成更多 NoThinking 响应,最终响应长度降低到低于 2000 个 token。
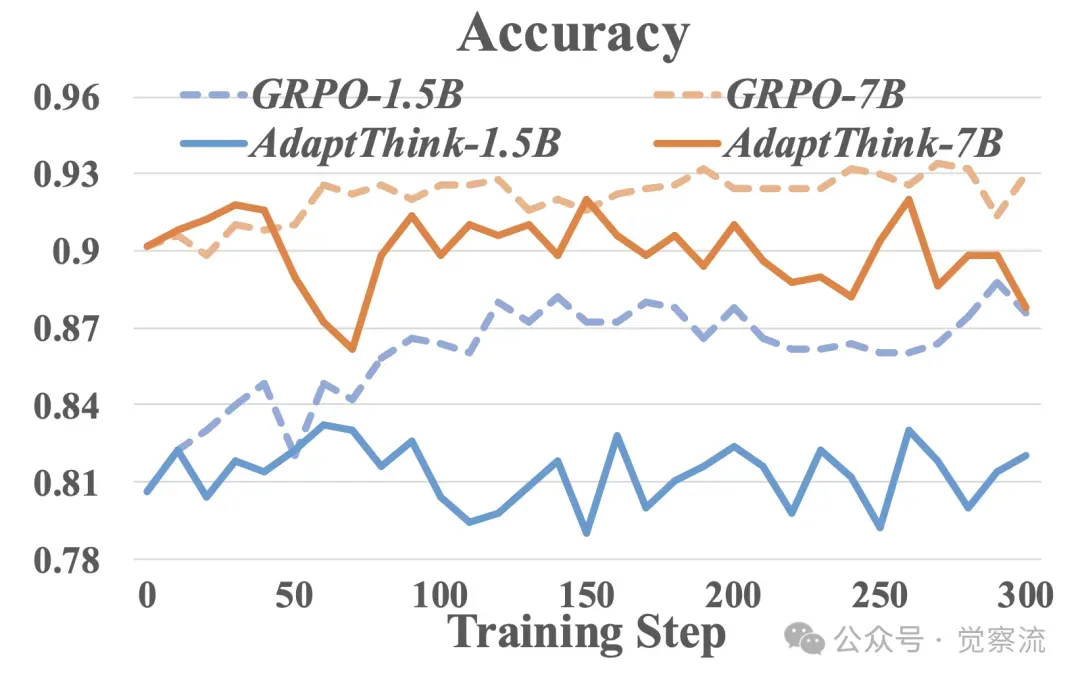
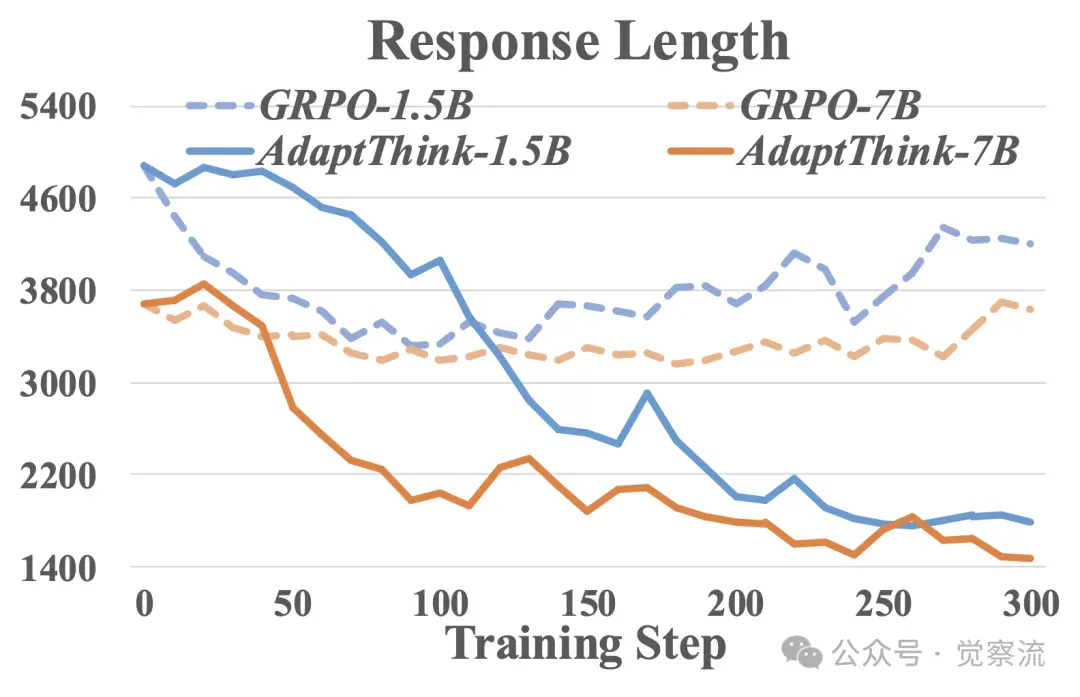
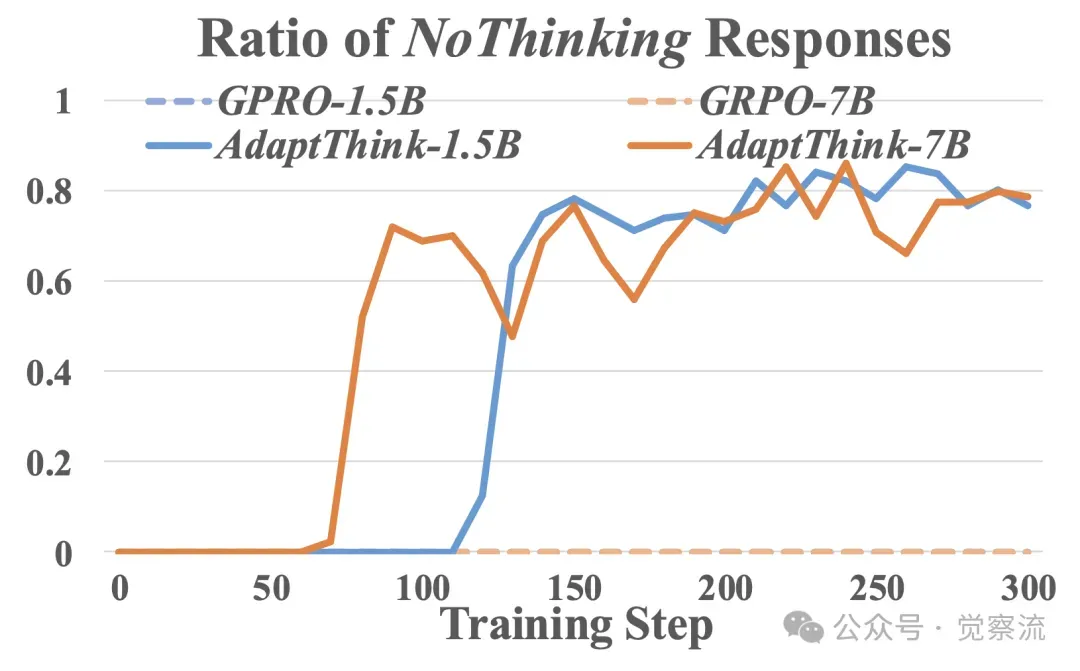
在不同训练步骤下,AdaptThink与朴素GPRO在MATH500上的准确率、回答长度以及“无思考”回答比例的对比
隐性思考比例检查
针对 RL 可能在 NoThinking 模式下激活思考特征的潜在担忧,对比 AdaptThink、原始模型的 NoThinking 响应以及原始模型 Thinking 响应的最终解决方案部分的隐性思考比例和平均长度。对于 1.5B 模型,AdaptThink 的隐性思考比例仅从原始 NoThinking 的 8.2% 略微增加到 7.9%,响应长度从 665 增加到 826。对于 7B 模型,隐性思考比例从原始 NoThinking 的 0.9% 增加到 4.2%,响应长度从 341 增加到 426。这表明 AdaptThink 的隐性思考增加有限。为完全消除此类行为,可在 RL 训练中对隐性思考样本赋予零奖励。
Model | RatioIT | Length |
DeepSeek-R1-Distill-Qwen-1.5B | 8.2% | 665 |
AdaptThink-1.5B | 7.9% | 826 |
DeepSeek-R1-Distill-Qwen-7B | 0.9% | 341 |
AdaptThink-7B | 4.2% | 426 |
泛化能力评估
在 MMLU 数据集(包含 14K 道多项选择题,涵盖 57 个不同领域)上测试 AdaptThink 模型的泛化性能。结果表明,AdaptThink 通过生成约 16% 的 NoThinking 响应,将平均响应长度减少超 30%,同时取得比原始模型更高的准确率。例如,对于 DeepSeek-R1-Distill-Qwen-1.5B,AdaptThink 的准确率为 42.2%,较原始 Thinking 提升 6.5%,响应长度从 1724 减少到 1055;对于 DeepSeek-R1-Distill-Qwen-7B,准确率从 63.4% 提升到 63.6%,响应长度从 1257 减少到 856。这证明了 AdaptThink 在 out-of-distribution 场景下的良好适应性。
Method | MMLU Acc | MMLU Length | MMLU RatioNT |
DeepSeek-R1-Distill-Qwen-1.5B | 35.7 | 1724 | 0.00% |
OriginalNoThinking | 20.6 | 208 | 100.00% |
AdaptThink | 42.2 | 1055 | 16.43% |
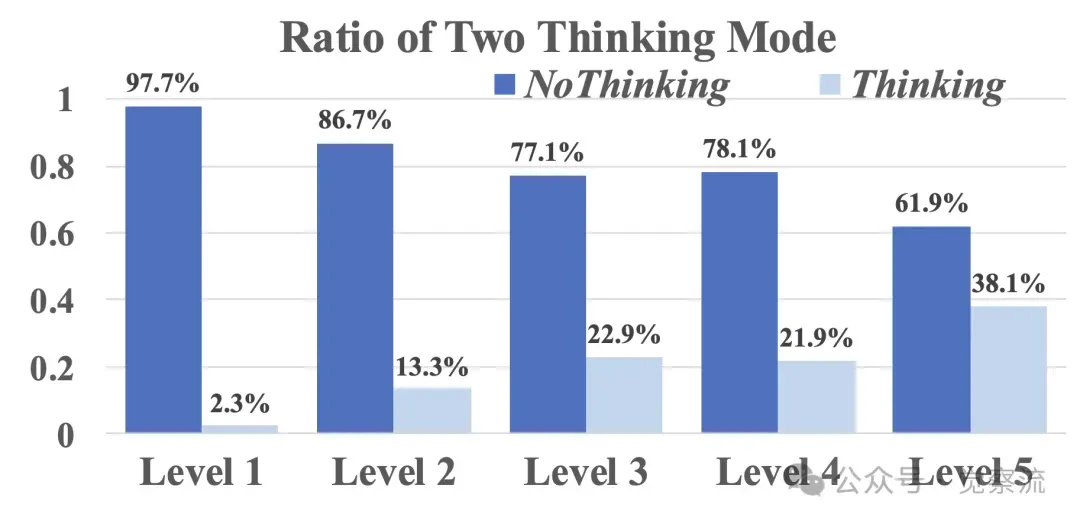
AdaptiveThink-1.5B 在不同数学水平下选择“思考”或“不思考”的比例
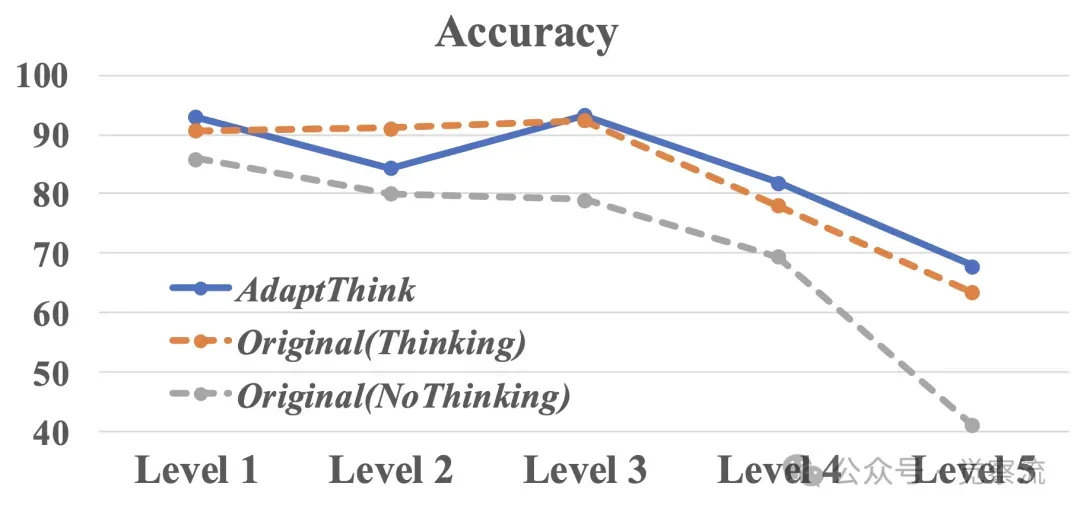
在不同数学水平下,使用有思考(Thinking)和无思考(NoThinking)模式时,AdaptiveThink-1.5B 与 DeepSeek-R1-Distill-Qwen-1.5B 的准确率对比
两个自适应的例子
1. 对于GSM8K中的一个简单数学问题,DeepSeek-R1-Distill-Qwen-7B在思考过程中大约消耗了3000个token,其中包含许多不必要的步骤和多余的尝试。相比之下,AdaptThink-7B能够自适应地选择无思考模式,并直接生成一个简洁的最终解决方案。



2. 对于2024年AIME中的一道富有挑战性的问题,AdaptThink-7B能够运用思考来解决,而不是直接生成最终答案。


开源仓库介绍
为了帮助读者更好地理解和使用 AdaptThink 算法,研究者们将其代码和相关资源开源在 GitHub 上。开源仓库提供了完整的实现细节,包括训练代码、预处理脚本、模型配置文件、评估脚本以及一些示例用例。以下是开源仓库的主要内容和使用指南:
开源仓库地址:见文末参考资料。https://github.com/THU-KEG/AdaptThink
仓库内容
- 训练代码:基于 VeRL 框架实现的 AdaptThink 训练代码,支持单机和多机训练,方便用户根据自己的硬件配置进行选择。
- 预处理脚本:用于处理训练和测试数据集的脚本,包括数据格式转换和预采样等操作,确保数据集符合模型输入要求。
- 模型配置:包含不同模型的配置文件,如 DeepSeek-R1-Distill-Qwen-1.5B 和 DeepSeek-R1-Distill-Qwen-7B 的训练参数和超参数设置,用户可以根据自己的需求进行调整。
- 评估脚本:用于评估模型性能的脚本,支持在不同数据集上的准确率和响应长度测试,帮助用户全面了解模型表现。
- 案例展示:提供了一些简单的使用示例,展示如何加载模型、生成推理结果以及评估模型性能,方便新手快速上手。
使用指南
1. 环境配置:使用 vLLM 0.8.2 和 Python 3.10 创建虚拟环境,并安装相关依赖库。具体步骤如下:
复制conda create -n adapt_think pythnotallow=3.10 pip install -r requirements.txt pip install flash-attn --no-build-isolation
2. 数据准备:下载并预处理训练和测试数据集,确保数据格式符合要求。可以使用仓库中提供的预处理脚本进行数据处理:
复制bash scripts/preprocess_dataset.sh
3. 模型训练:运行训练脚本,根据需要调整超参数和训练配置。例如,训练 1.5B 模型的命令如下:
复制bash scripts/run_adapt_think_1.5b_deepscaler_16k_delta0.05_btz128_lr2e-6.sh
4. 模型评估:使用评估脚本测试模型性能,生成详细的评估报告。可以使用以下命令将训练好的模型转换为 HuggingFace 格式并进行评估:
复制# 转换为 HuggingFace 格式 bash scripts/convert_to_hf.sh # 评估模型 bash scripts/run_eval_verl_hf.sh
5. 案例运行:参考案例展示,尝试不同的输入问题,观察模型的推理过程和结果。这有助于用户更好地理解 AdaptThink 的工作原理和实际效果。
开源仓库不仅提供了完整的代码实现,还通过详细的文档和示例帮助用户快速上手。无论是研究人员还是开发者,都可以利用这些资源进行进一步的研究和开发工作。
实际应用场景和落地挑战
虽然 AdaptThink 在实验中展现出了显著的优势,但在实际应用场景中仍面临一些挑战。以下是一些常见的实际应用场景以及可能遇到的落地挑战和相应的解决方案:
- 自动问答系统:AdaptThink 可以快速响应简单问题,提高系统吞吐量和用户体验。然而,在面对复杂多轮对话时,可能需要进一步优化模型的上下文理解和推理能力。
- 智能辅导系统:AdaptThink 能够根据习题难度自适应调整思考模式,为学生提供精准辅导。但在不同学科和知识点上的适配性需要进一步验证和优化。
- 文本生成任务:在自然语言处理领域的文本生成任务中,AdaptThink 可以减少生成过程中的冗余内容,提高生成效率。但对于一些需要高度创造性和多样性的文本生成任务,如何平衡推理质量和创意表达是一个挑战。
- 图像识别与分析:AdaptThink 的自适应推理机制也可以应用于图像识别领域,例如在简单场景中快速识别目标物体,在复杂场景中进行多步推理和分析。但在处理大规模图像数据时,模型的计算资源需求和实时性要求需要特别关注。
针对这些实际落地挑战,研究者们提出了以下解决方案和研究方向:
- 模型优化与压缩:通过模型量化、剪枝等技术,降低模型的计算复杂度和存储需求,提高其在资源受限环境中的适用性。
- 多领域数据训练:利用多领域数据集对模型进行训练,增强其在不同领域和任务上的通用性和适应性。
- 人机协作与反馈:引入人机协作机制,通过用户反馈和交互进一步优化模型的推理策略和结果。
- 持续学习与更新:采用持续学习方法,使模型能够不断学习新的知识和技能,适应不断变化的应用场景和用户需求。
总结
AdaptThink 算法,实现了推理模型基于问题难度的 optimal thinking mode 自适应选择,大幅降低了推理成本并提升了模型性能;最后,通过一系列实验验证了 AdaptThink 的有效性,为其作为优化推理质量和效率权衡的新型范式提供了有力支持。
用最简短的语言来总结一下 AdaptThink 的原理:
AdaptThink 的原理是通过强化学习(RL)算法,利用奖惩机制来训练模型在面对不同难度的问题时,自适应地选择是否使用 <think></think> 这个 special token 来开启或关闭思考模式,从而在推理质量和效率之间取得更好的平衡。
AdaptThink 在实际应用场景中具有巨大潜力。在自动问答系统中,它能够快速响应简单问题,提高系统吞吐量和用户体验;在智能辅导系统中,可根据不同难度的习题自适应调整思考模式,为学生提供精准且高效的辅导。此外,针对不同领域问题,如自然语言处理领域的文本生成任务、图像识别领域的复杂场景分析等,AdaptThink 也有可能通过适应性调整,发挥其独特优势。
参考资料
- AdaptThink: LLM Can Learn When to Think.
https://arxiv.org/pdf/2505.13417
- Github repo - THU-KEG/AdaptThink
https://github.com/THU-KEG/AdaptThink


