通义万相宣布VACE开源,这标志着视频编辑领域迎来了一次重大的技术革新。此次开源的Wan2.1-VACE-1.3B支持480P分辨率,而Wan2.1-VACE-14B则支持480P和720P两种分辨率。VACE的出现,为用户带来了一站式的视频创作体验,用户无需在不同模型或工具之间频繁切换,即可完成文生视频、图像参考生成、局部编辑与视频扩展等多种任务,极大地提高了创作效率和灵活性。
VACE的强大之处在于其可控重绘能力,它能够基于人体姿态、运动光流、结构保持、空间运动、着色等控制生成,同时也支持基于主体和背景参考的视频生成。这使得在视频生成完成后,调整人物姿态、动作轨迹或场景布局等操作变得不再困难。VACE背后的核心技术是其多模态输入机制,它构建了一个集文本、图像、视频、Mask和控制信号于一体的统一输入系统。对于图像输入,VACE可支持物体参考图或视频帧;对于视频输入,用户可以通过抹除、局部扩展等操作,使用VACE重新生成;对于局部区域,用户可以通过0/1二值信号来指定编辑区域;对于控制信号,VACE支持深度图、光流、布局、灰度、线稿和姿态等。

VACE不仅支持对视频中指定区域进行内容替换、增加或删除等操作,还能在时间维度上根据任意片段或首尾帧补全整个视频时长,在空间维度上支持对画面边缘或背景区域进行扩展生成,如背景替换——在保留主体不变的前提下,依据Prompt更换背景环境。得益于强大的多模态输入模块和Wan2.1的生成能力,VACE能够轻松驾驭传统专家模型能实现的功能,包括图像参考能力、视频重绘能力、局部编辑能力等。此外,VACE还支持多种单任务能力的自由组合,打破了传统专家模型各自为战的协作瓶颈。作为统一模型,它能够自然融合文生视频、姿态控制、背景替换、局部编辑等原子能力,无需为单一功能单独训练新模型。
VACE的灵活组合机制,不仅大幅简化了创作流程,也极大地拓展了AI视频生成的创意边界。例如,组合图片参考与主体重塑功能,可以实现视频中物体的替换;组合运动控制与首帧参考功能,可以实现静态图片的姿态控制;组合图片参考、首帧参考、背景扩展与时长延展功能,可以将竖版图拓展为横屏视频,并在其中加入参考图片中的元素。通过对四类常见任务(文生视频、图生视频、视频生视频、局部视频生视频)的输入形态进行分析和总结,VACE提出了一个灵活统一的输入范式——视频条件单元VCU。VCU将多模态的各类上下文输入总结成了文本、帧序列、mask序列三大形态,在输入形式上统一了4类视频生成与编辑任务。VCU的帧序列和Mask序列在数学上可以相互叠加,为多任务的自由组合创造了条件。
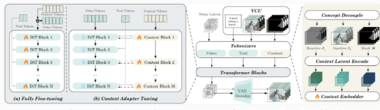
在技术实现方面,VACE需要解决的一大难题是如何将多模态输入统一编码为扩散Transformer可处理的token序列。VACE对VCU输入中的Frame序列进行概念解耦,将其分为需要原封不动保留的RGB像素(不变帧序列)和需要根据提示重新生成的内容(可变帧序列)。然后,分别对这三类输入(可变帧、不变帧、Mask)进行隐空间编码,其中可变帧和不变帧通过VAE被编码到与DiT模型噪声维度一致的空间,通道数为16;而mask序列则通过变形和采样操作,被映射到时空维度一致、通道数为64的隐空间特征。最后,将Frame序列和mask序列的隐空间特征合一,并通过可训练参数映射为DiT的token序列。
在训练策略上,VACE对比了全局微调与上下文适配器微调两种方案。全局微调通过训练全部DiT参数,能取得更快的推理速度;而上下文适配器微调方案是固定原始的基模型参数,仅选择性地复制并训练一些原始Transformer层作为额外的适配器。实验表明,两者在验证损失上差异不大,但上下文适配器微调具有更快的收敛速度,且避免了基础能力丢失的风险。因此,本次开源版本采用了上下文适配器微调方法进行训练。通过本次发布的VACE系列模型定量评测可以看出,相比1.3Bpreview版本,模型在多个关键指标上均有明显提升。
- GitHub:https://github.com/Wan-Video/Wan2.1
- 魔搭:https://modelscope.cn/organization/Wan-AI
- Hugging Face:https://huggingface.co/Wan-AI
- 国内站:https://tongyi.aliyun.com/wanxiang/
- 国际站:https://wan.video