编辑 | 听雨
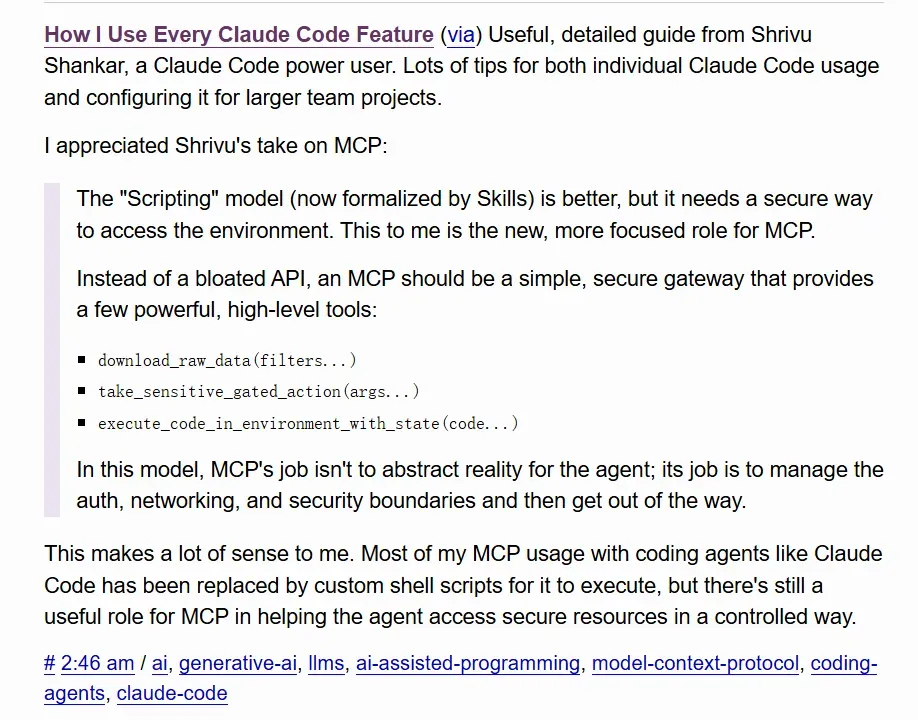
小编最近刷到一篇让程序员直呼“醍醐灌顶”的文章——出自软件工程师兼安全工程师 Shrivu Shankar。他基于日常使用 Claude Code 的真实经验,分享了从个人项目到企业级开发的全套智能体最佳实践。
Shrivu 不只是讲理论,他讲述了管理智能体上下文、批量处理任务、快速原型、自动生成 Pull Request 的实操技巧,还结合 Hooks、Skills、MCP、SDK 等高级特性,告诉你如何把 AI 真正融入日常工程工作流。
 图片
图片
知名开源公司创始人 Simon Willison 也高度评价:“Shrivu 的指南非常实用,既适合个人,也适合为大型团队进行智能体配置。”尤其对 MCP 的看法,他说得很精炼:“与其构建臃肿的 API,不如把 MCP 设计成简单、安全的网关,只提供少量强大的工具。”
 图片
图片
如果你想知道 Claude Code 的每个功能该怎么用、什么时候用、如何最大化价值,小编为你整理了文章的精华内容,它将是你最实用的参考手册。
我如何使用Claude Code的每个功能
我真的很常用 Claude Code。
作为一个业余开发者,我每周都会在虚拟机中运行它几次,开启 --dangerously-skip-permissions 模式,随心所欲地「即兴编码」各种想法。在工作中,我的团队负责为公司工程团队构建 AI IDE 的规则与工具,我们每月光代码生成就消耗数十亿个 token。
CLI 智能体的竞争正在白热化——Claude Code、Gemini CLI、Cursor、Codex CLI……我感觉真正的竞争是在 Anthropic 和 Open AI 之间。
但老实说,开发者之间的选择往往取决于一些“表面因素”——比如某个功能实现的“运气”,或者他们更喜欢哪种系统提示的“语气”。到现在为止,这些工具都已经相当不错了。
我也注意到,很多人过度关注输出风格或 UI。对我来说,Claude 里那种“你太对了!”式的奉承并不是 bug,而是一个信号:说明你给的上下文太多了。我的目标是「发射即忘」(shoot and forget)——设定上下文,交代任务,让它自己去完成。评判工具的标准,是最终提交的 PR,而不是它中间的过程。
在过去几个月深入使用 Claude Code 后,这篇文章是我对它整个生态系统的总结。我会覆盖几乎所有我使用的功能(以及我不用的功能),从核心的 CLAUDE.md 文件、定制命令、到 Subagents、Hooks、GitHub Actions 等强大特性。
CLAUDE.md
在 Claude Code 中,最重要的文件就是项目根目录下的 CLAUDE.md。它是智能体的“宪法”——描述你的代码库该如何被理解和操作。
- 对于个人项目,我让 Claude 自己随意在里面写。
- 对于公司项目,我们严格维护 monorepo 的 CLAUDE.md,目前有 13KB(预计会涨到 25KB)。
它只记录被超过 30% 工程师使用的工具和 API,其他工具则单独写在对应库的 markdown 文档里。我们甚至给每个内部工具的文档分配“token 上限”,就像卖广告位一样——如果你讲不清楚,就别进 CLAUDE.md。
编写 CLAUDE.md 的技巧与反模式
- 从“防错”开始,而不是写手册。CLAUDE.md 应该从 Claude 容易出错的地方开始补充,而不是从零开始详尽记录。
- 不要直接 @ 文件文档。如果你 @ 引用了其它文档,Claude 会每次都把整份文件嵌入上下文,浪费 token。但仅仅写路径 Claude 又会无视它。正确做法是告诉 Claude 什么时候该去读那份文档,例如:
“如果遇到 FooBarError 或复杂用法,请参见 path/to/docs.md。”
- 不要只写“永远不要”。单纯写“Never use --foo-bar”会让模型卡住。应同时提供替代方案。
- 把 CLAUDE.md 当作“约束工具”。如果命令太复杂,不要写长篇解释,而是写一个简单的 bash 包装器,让命令变得直观,再记录它。保持 CLAUDE.md 精简,是推动团队改进工具的好方式。
示例结构如下:

最后,我们还会维护一个 AGENTS.md,用于与其他 AI IDE(如 Cursor)兼容。
要点总结:把你的 CLAUDE.md 当作一份高层次、经过精心筛选的指引,而不是一本面面俱到的使用手册。它的作用,是帮助你识别出哪些地方需要投入更多精力,去打造对 AI 与人类 都更友好的工具和流程。
Compact、Context 与 Clear
我建议在中途运行一次 /context,看看 200k token 的上下文是如何被使用的(即使是 Sonnet-1M,我也不完全相信 100 万 token 都被有效利用)。
在我们的 monorepo 中,一个新会话的“空载成本”约 20k tokens(10%),剩余 180k 负责执行修改——很快就会被填满。
我的三种主要工作流:
- /compact(避免)自动压缩上下文太黑箱、容易出错、不可靠。
- /clear + /catchup(简单重启)我默认的重启方式:清除状态,然后运行 /catchup 让 Claude 重新读取本分支修改的文件。
- “Document & Clear”(复杂重启)对大型任务,我让 Claude 把计划与进展写入一个 .md 文件,然后清空状态,让它读回这个文件继续。
要点总结:不要依赖自动压缩。小任务用 /clear 重启,大任务用“记录 + 清理”的方式保留上下文记忆。
自定义 Slash 命令
我把 Slash 命令看作是常用提示语的简单快捷方式,仅此而已。我的配置非常精简:
- /catchup:前面提到过的命令,用来让 Claude 读取当前 Git 分支中所有被修改的文件。
- /pr:一个小帮手,用于清理代码、暂存修改并准备创建 Pull Request。
在我看来,如果你维护着一长串复杂的自定义斜杠命令,那其实是一种反模式。像 Claude 这样的智能体,本意就是让你几乎能“随口输入”任何自然语言请求,并得到一个有用、可合并的结果。一旦你要求开发者(甚至非技术人员)必须去学习一份记录在某处的“魔法命令清单”才能完成工作,那就违背了智能体设计的初衷。
要点总结:把斜杠命令当作简单、个性化的快捷方式来使用,而不是用它们去替代一个更直观的 CLAUDE.md 文件或更完善的智能体工具体系。
自定义子代理
理论上,自定义子代理是 Claude Code 中最强大的上下文管理功能之一。它的设计逻辑很简单:一个复杂任务需要 X 个 token 的输入上下文(例如测试运行方式),在执行过程中积累 Y 个 token 的工作上下文,最终产出 Z 个 token 的结果。如果要运行 N 个这样的任务,那么主会话窗口就要处理 (X + Y + Z) * N 的上下文负载。
而子代理(subagent)机制的解决思路是:把 (X + Y) * N 的繁重计算外包给专门的子代理,让它们只返回最终的 Z 结果,从而保持主会话上下文的整洁。
听起来很美好,但在实际使用中,我发现自定义子代理带来了两个新的问题:
1.它们会“封锁”上下文。
例如我创建了一个 PythonTests 子代理,那么所有与测试相关的上下文就被隔离在它的内部。主代理再也无法从整体上推理一个改动,因为它必须调用子代理才能知道如何验证自己的代码。
2.它们强加了“人类式工作流”。
更糟的是,这种机制迫使 Claude 遵循我人为定义的流程。我在告诉它“你必须这样分工合作”,而这恰恰是我希望 AI 自主解决的问题。
我更喜欢的替代方案是使用 Claude 内置的 Task(...) 功能来克隆出通用代理的副本。我会把所有关键上下文写在 CLAUDE.md 文件里,然后让主代理自行决定何时、如何委派任务给自己的副本。这样既保留了子代理带来的上下文节省优势,又避免了它的僵化问题,让智能体能够动态自我调度。
在我的另一篇文章《Building Multi-Agent Systems(Part 2)》中,我称这种架构为 “主控–克隆(Master-Clone)”模型,并且我明确更偏爱这种方式,而不是自定义子代理所鼓励的 “主导–专家(Lead-Specialist)”模型。
(文章链接:https://blog.sshh.io/p/building-multi-agent-systems-part)
要点总结:自定义子代理是一种脆弱的解决方案。更好的做法是:把核心上下文放入 CLAUDE.md,让主代理通过自己的 Task/Explore(...) 功能自主管理任务分配与协作。
Resume、Continue 与 History 功能
在日常使用中,我经常使用 claude --resume 和 claude --continue 这两个命令。它们非常适合在终端出错后快速重启,或恢复旧的会话。有时我会恢复几天前的一次会话,只是为了让 Claude 总结它当时是如何解决某个特定错误的,然后把这些经验更新进我们的 CLAUDE.md 或内部工具中。
更深入一点来说,Claude Code 会把所有会话历史记录保存在 ~/.claude/projects/ 目录下,这意味着你可以直接访问那些原始的历史会话数据。我写了一些脚本来对这些日志进行元分析,寻找常见的异常、权限请求和错误模式,以帮助优化智能体的上下文提示与行为策略。
要点总结:使用 claude --resume 和 claude --continue,不仅可以重启中断的会话,还能够挖掘历史日志中被埋没的上下文信息,持续改进你的智能体配置与工作流。
Hooks(钩子机制)
Hooks 的作用非常强大。虽然我在个人项目里几乎不用它们,但在大型企业级代码仓库中,它们是引导 Claude 行为的关键工具。你可以把它们理解为 CLAUDE.md 文件中“应该做的建议(should-do)”之外的“必须遵守的规则(must-do)”。
我们主要使用两种类型的 Hook:
1.提交阻断钩子(Block-at-Submit Hooks)
这是我们最主要的策略。我们有一个 PreToolUse 钩子,它会包裹所有的 Bash(git commit) 命令。当 Claude 尝试提交代码时,它会先检查 /tmp/agent-pre-commit-pass 文件。这个文件只有在所有测试通过后、由测试脚本生成。如果文件不存在,钩子就会阻止提交,迫使 Claude 进入一个“测试—修复”循环,直到构建通过为止。
2.提示钩子(Hint Hooks)
这类钩子不会中断流程,而是在 Claude 做出不太理想操作时,提供一次性提示或反馈。它们属于“提醒而非强制”的机制。
我们刻意不使用“写入时阻断钩子”(block-at-write),例如在 Edit 或 Write 操作中直接中断 Claude 的执行。这样做只会让智能体感到混乱甚至“挫败”,更有效的做法是:让它完整执行完计划,再在提交阶段检查最终结果。
要点总结:使用 Hook 的最佳实践是:
- 在提交阶段执行状态验证(block-at-submit),确保结果可靠。
- 避免在写入阶段中断,让智能体先完成计划,再评估最终产物。
规划模式(Planning Mode)
在使用 AI IDE 时,规划(Planning) 对于任何较大的功能变更都至关重要。在我的个人项目中,我完全依赖 Claude 的内置规划模式。这个模式的作用,是在 Claude 开始工作前,与它对齐目标:既定义要如何构建功能,也明确中途的检查点(inspection checkpoints)——即它需要暂停并向我展示阶段性成果的地方。
经常使用这种模式,可以培养出一种直觉:了解在不给 Claude 过多上下文的情况下,什么信息是“最小但足够”的,既能让它制定出合理的计划,又不会让执行阶段“跑偏”。
在我们的企业级 monorepo(单体代码库)中,我们已经开始基于 Claude Code SDK 构建自定义的规划工具。它的工作方式与原生规划模式类似,但我们在提示词中加入了大量约束,让输出内容与团队的技术设计文档格式保持一致。此外,它还内置了团队最佳实践——从代码结构到数据隐私、安全规范,全都自动遵循。这让工程师们可以像一位高级架构师一样去“共创规划”,(至少理论上是这样)。
要点总结:在进行复杂变更时,一定要使用内置的规划模式,先与 Claude 明确计划与检查节点,再让它正式开始执行工作。
技能(Skills)
我非常认同 Simon Willison 的观点:Skills也许比 MCP 更重要。
如果你一直关注我的文章,就会知道我在多数开发工作流中,已经逐渐放弃 MCP,转而倾向于构建一些简单的 CLI 工具(正如我在《AI Can’t Read Your Docs》中所论述的那样)。
(文章链接:
https://blog.sshh.io/p/ai-cant-read-your-docs)
我对智能体自主性的理解,已经演化为以下三个阶段:
1.单提示阶段(Single Prompt)
把所有上下文一次性塞进一个超大的提示中(问题是脆弱、不具扩展性)。
2.工具调用阶段(Tool Calling)
经典的智能体模型。我们手工编写工具,为智能体抽象现实世界(更好一些,但会带来新的抽象层和上下文瓶颈)。
3.脚本化阶段(Scripting)
我们让智能体直接访问底层环境——包括二进制文件、脚本和文档,它可以即时编写代码与这些资源交互。
在这种模型下,Agent Skills 就成了非常自然的下一步演进。它们实际上是对“脚本化层(Scripting Layer)”的正式产品化。
如果你和我一样,早就更倾向于使用 CLI 而非 MCP,那么你其实早就在享受 Skills 带来的好处。SKILL.md 文件只是让这些 CLI 和脚本更有组织、更易共享、更易被发现,并以一种标准方式暴露给智能体。
要点总结:Skills 是一种正确的抽象。它们把“基于脚本的智能体模型”正式化,这种模式比 MCP 所代表的僵化、类 API 模式更加健壮、灵活、实用。
MCP
引入 Skills 并不意味着 MCP 已死(参见我之前的文章《Everything Wrong with MCP》)。(文章链接:
https://blog.sshh.io/p/everything-wrong-with-mcp)
过去,很多人滥用 MCP —— 构建了大量臃肿、上下文极重的 MCP 接口,里面塞满了几十个功能雷同的小工具,比如:read_thing_a()、read_thing_b()、update_thing_c()……这些接口不过是把 REST API 生硬地“翻译”了一遍。
如今,“脚本化”模型(也就是 Skills 所正式化的那一层)显然更优,但它仍然需要一种安全访问运行环境的方式。而这,正是 MCP 新的、更加聚焦的使命。
在我看来,一个现代化的 MCP 不应再是庞大繁琐的 API 集合,而应该是一个简单、安全的环境网关(secure gateway),仅提供少量但功能强大的高级工具,例如:
- download_raw_data(filters…) —— 下载原始数据;
- take_sensitive_gated_action(args…) —— 执行敏感操作;
- execute_code_in_environment_with_state(code…) —— 在带状态的环境中运行代码。
在这种模型下,MCP 的职责不再是为智能体抽象现实世界,而是管理认证、网络与安全边界,然后“让开道路”,为智能体提供一个受控的入口,让它用自己的脚本和 Markdown 上下文去完成真正的工作。
目前,我只保留了一个 MCP:用于 Playwright。这很合理——Playwright 是一个复杂且有状态的环境。至于那些无状态工具(如 Jira、AWS、GitHub),我已经全部迁移到更简单的 CLI 方案中。
要点总结:把 MCP 当作数据网关(data gateway)来使用。给智能体提供一到两个高层工具接口(例如原始数据导出 API),然后让它在此基础上,通过脚本化方式自主完成工作。
Claude Code SDK
Claude Code 不仅仅是一个交互式 CLI,它同时也是一个功能强大的 SDK,可以用来构建全新的智能体——无论是用于编程任务,还是非编程场景。
如今,在我大多数新的个人项目中,我已经默认使用 Claude Code SDK,取代了 LangChain、CrewAI 等传统框架。
我主要有三种使用方式:
1.大规模并行脚本执行
当我需要进行大规模重构、批量修复 bug 或代码迁移时,我不会使用交互式聊天,而是编写简单的 Bash 脚本,通过类似 claude -p "in /pathA change all refs from foo to bar" 的命令并行调用。这种方式比让主智能体去管理几十个子代理任务更高效、更可控。
2.构建内部聊天工具
SDK 非常适合把复杂流程包装成简洁的聊天界面,供非技术用户使用。例如,一个安装器在遇到错误时,可以自动调用 Claude Code SDK 来修复问题;或者我们构建了一个类似 “v0-at-home” 的内部工具,让设计团队用自然语言“共创”前端原型,并在我们的自研 UI 框架中实时生成高保真、可直接用于生产的代码。
3.快速原型开发
这是我最常见的用法——而且不局限于编程。当我有一个新的智能体想法时(比如一个使用自定义 CLI 或 MCP 的“威胁调查智能体”),我会先用 Claude Code SDK 快速构建并测试原型,在验证可行后再决定是否开发完整的部署版本。
要点总结:Claude Code SDK 是一个通用型智能体框架。你可以用它来:
- 批量处理代码任务,
- 构建内部自动化聊天工具,
- 或者快速验证新的 Agent 概念。
在尝试更复杂的框架之前,Claude Code SDK 往往已经足够强大。
Claude Code GHA(GitHub Action)
Claude Code 的 GitHub Action(简称 GHA)大概是我最喜欢、也最容易被忽视的功能之一。它的概念非常简单:在 GitHub Action 里运行 Claude Code。但正是这种“简单”,让它变得异常强大。
它有点像 Cursor 的后台智能体,或 Codex 的托管式网页界面,但 Claude Code GHA 的自定义能力远超它们。你可以完全控制容器和运行环境,这意味着你能获得更高的数据访问自由度,同时在沙箱隔离与审计安全上拥有业界最强的能力。此外,它还支持所有高级特性,比如 Hooks 和 MCP。我们团队用它构建了一个自定义的 “PR-from-anywhere(随处发起 PR)” 工具链。用户可以直接在 Slack、Jira,甚至 CloudWatch 警报 中触发一个 PR 请求,然后 GHA 就会自动修复 bug 或添加功能,最终返回一个已测试通过的完整 Pull Request 。
更妙的是,GHA 的日志记录了智能体的完整执行过程。我们在公司层面建立了一套运维流程,定期审查这些日志,查找常见错误、bash 异常或不符合工程规范的操作。这形成了一个数据驱动的改进飞轮:Bugs → 改进 CLAUDE.md / CLI → 更强的智能体。
甚至可以直接运行类似这样的命令:
 图片
图片
让 Claude 自己分析过去几天的所有智能体运行记录,找出其他 Claude 卡住的问题、修复它们,并自动提交一个改进 PR。
要点总结:Claude Code GHA 是让 Claude Code 真正进入工程体系的关键工具。它让 Claude 从一个个人助手,升级为你团队中可审计、可追踪、可自我改进的核心基础设施。
.json 配置
最后,我整理了一些在个人项目和专业工作中都非常关键的 settings.json 配置:
- HTTPS_PROXY / HTTP_PROXY:非常适合调试使用。我会用它来查看 Claude 发送的原始请求和提示词。对于后台智能体来说,它也是一种强大的精细化网络沙箱控制工具。
- MCP_TOOL_TIMEOUT / BASH_MAX_TIMEOUT_MS:我会调高这些超时时间,因为我喜欢运行长时间、复杂的命令,而默认超时往往太保守。现在 bash 后台任务流行了,我不确定是否还必须,但我习惯保留以防万一。
- ANTHROPIC_API_KEY:在工作中,我们使用企业级 API Key(通过 apiKeyHelper 管理)。这样可以将许可模式从“按席位付费”转为按使用量付费,更符合我们团队的实际工作方式。
它还能应对工程师使用量的巨大差异(我们观察到工程师之间有 1:100 的使用差异)。 同时,允许工程师在单一企业账户下自由尝试非 Claude Code 的 LLM 脚本。
- “permissions”:我会定期自我审计,检查允许 Claude 自动执行的命令列表。
要点总结:settings.json 是高级自定义的强大入口,可以帮助你根据工作流灵活调整网络、超时、权限等核心参数。
网友:没有工具比Claude Code改变我编程方式更多
这篇文章的 Hacker News 评论区也非常热闹,很多网友都在分享自己对Claude Code、MCP、CLI 使用和 VS Code 集成的实用经验。
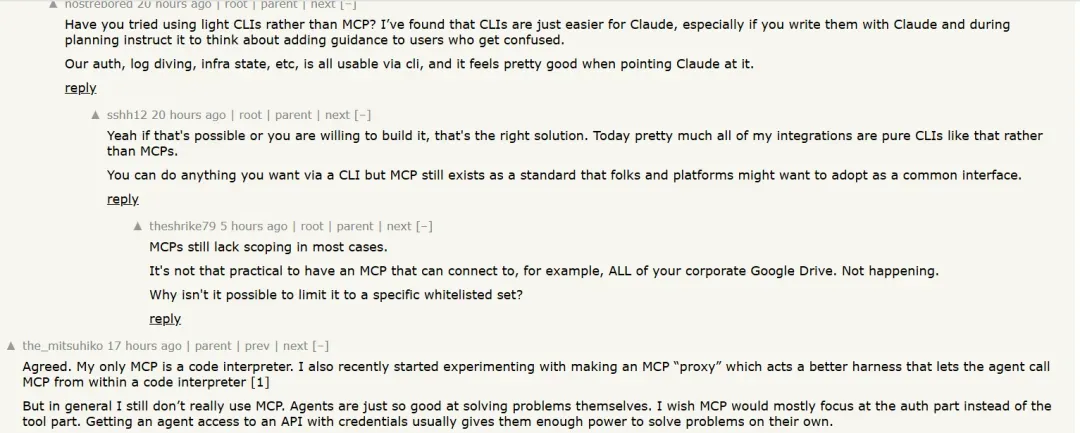
有网友十分认同作者对MCP的看法:
与其构建臃肿的 API,MCP 应该是一个简单、安全的网关,提供少量强大的高级工具……MCP 的工作不是抽象现实给智能体,而是管理认证、网络和安全边界,然后退到一边。
 图片
图片
也有一些开发者分享,自己已经用轻量 CLI 替代 MCP,因为 CLI 更灵活、易于定制,而 MCP 更像是标准化、安全的内部网关。
“我发现 CLI 对 Claude 更容易,尤其是在规划时指导它给用户添加提示。我们的认证、日志、基础设施状态都是 CLI 可用的,用起来感觉不错。”
“今天我的大部分集成都是纯 CLI,而不是 MCP。CLI 可以做任何事,但 MCP 仍然作为标准存在,方便平台采用统一接口。”
“我唯一的 MCP 是代码解释器。我最近尝试做一个 MCP “代理”,让智能体在代码解释器内调用 MCP。但总体上我仍不怎么用 MCP。”
 图片
图片
 图片
图片

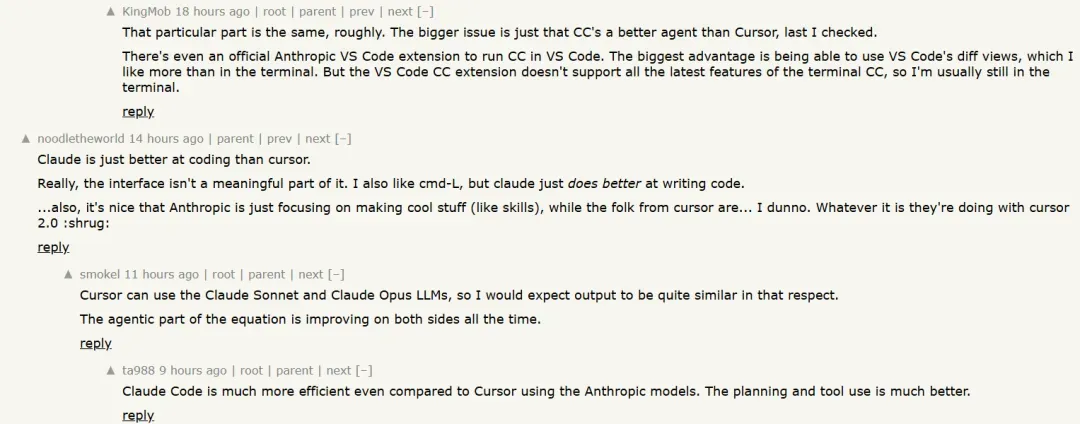
不少网友在评论区表示:Claude Code 比 Cursor 更好用。
“Claude CLI 输出质量高,每天都给我价值。”
“Claude 编程能力比 Cursor 强。界面并不关键,我也喜欢 Cmd-L,但 Claude 写代码更好。Anthropic 专注于技能,而 Cursor 团队……不太清楚。”
“Claude Code 比 Cursor 高效很多。计划和工具使用更好。”
那么,如果你还没有使用像 Claude Code 或 Codex CLI 这样的 CLI 智能体,现在是时候尝试了。
针对这些高级功能的指南非常少,所以唯一的学习方式就是亲自上手,深入实践。
希望这篇文章对大家有所帮助,欢迎在评论区聊聊你的看法。
参考链接:https://blog.sshh.io/p/how-i-use-every-claude-code-feature