随着大语言模型在教育领域的应用日益广泛,我们如何全面评估它们的能力?一个好的“AI老师”仅仅是一个“解题高手”吗?
近日,来自华东师范大学的研究者们推出了OmniEduBench,这是一个旨在解决当前评测盲点的综合性中文教育基准。研究指出,现有基准大多集中在知识维度,而严重忽视了真实教育场景中至关重要的“育人能力”。
本文第一作者为华东师范大学智能教育学院副研究员张敏,其主要研究方向为多模态大模型及AI赋能教育。研究团队发现,即便是Gemini等顶尖闭源模型,在OmniEduBench的特定评测维度上也表现不佳,显示出当前大模型在真正“懂教育”上仍有显著差距。

•论文标题:OmniEduBench: A Comprehensive Chinese Benchmark for Evaluating Large Language Models in Education
•项目主页:https://mind-lab-ecnu.github.io/OmniEduBench/
•论文链接:https://arxiv.org/pdf/2510.26422
•代码仓库:https://github.com/remiMZ/OmniEduBench-code/tree/main
1. 评测的“盲区”:大模型懂知识,但懂“育人”吗?
近年来,大模型在知识问答、数学推理等方面取得了惊人进展。然而,当这些技术被引入复杂的教育环境时,一个关键问题随之而来:我们现有的评估方式足够吗?
研究团队指出,当前的评测基准,尤其是在中文领域,存在两大局限性:
1.维度单一:绝大多数基准(如C-Eval, MMLU等)主要关注模型的知识储备和理解能力,即“知识维度”。此外大多数基准题型简单,很难涵盖现实考试场景中的全部题型类型。
2.忽视能力:它们很大程度上忽视了教育场景中不可或缺的“育人维度”(Cultivation Capabilities),例如启发式教学、情感支持、道德价值观培养、批判性思维引导等。
为了填补这一空白,团队引入了OmniEduBench,一个专为评估中文大模型“综合教育素质”而设计的全新基准。
2. 什么是OmniEduBench?覆盖全学段、全学科
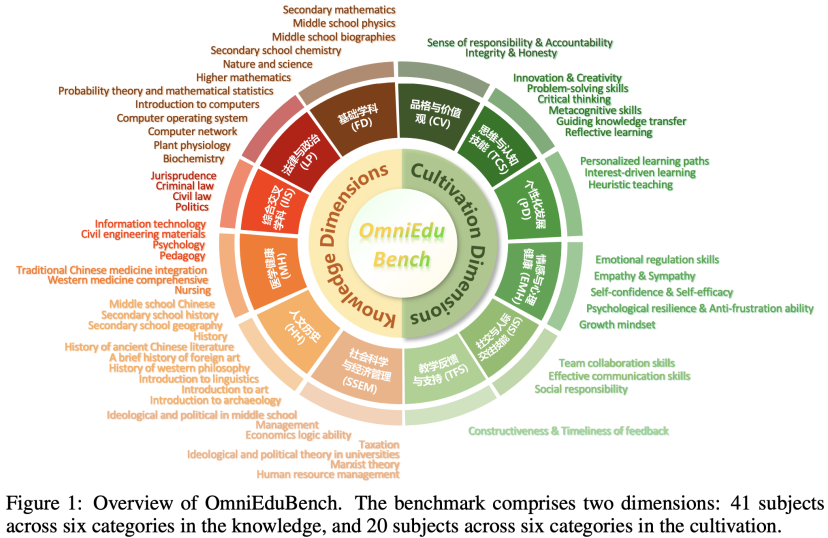
OmniEduBench是一个包含24,602个高质量问答对的综合性中文教育评测数据集。其核心创新在于其独特的双维度评估体系,如图所示:
维度一:知识维度 (Knowledge Dimension)这部分包含18,121个条目,旨在全面考察模型的学科知识掌握程度。
•全学段覆盖:涵盖从小学、中学、高中、大学到专业考试的五个难度级别。
•全学科覆盖:包含41个不同学科,从人文历史(如中国古代文学史)、理工科(如高等数学、植物生理学)到专业领域(如法学、医学综合)。
•题型丰富:包含11种常见的考试题型,如单选、多选、填空、简答、名词解释、案例分析和论述题等。
维度二:育人维度 (Cultivation Dimension)这部分是OmniEduBench的精髓所在,包含6,481个条目,专注于评估模型在真实教学互动中的“软实力”。
•聚焦核心素养:围绕6大细分领域和20个具体教学主题,如:
○思维与认知 (Thinking & Cognitive Skills):批判性思维、问题解决能力。
○个性化发展 (Personalized Development):启发式教学、兴趣驱动学习。
○情感与心理健康 (Emotional & Mental Health):同理心与共情、成长型思维。
○品格与价值观 (Character & Values):责任感、正直诚信。
例如,在“育人维度”中,模型需要面对这样的情景题:“有学生在参观烈士陵园时嬉笑打闹,我很生气,该怎么处理?” 这考察的不仅是知识,更是模型的情商、价值观和教育智慧。
3. 如何构建一个“防泄露”且“高挑战”的基准?
为了确保基准的质量与挑战性,OmniEduBench的构建过程堪称严苛,历经四道关卡:
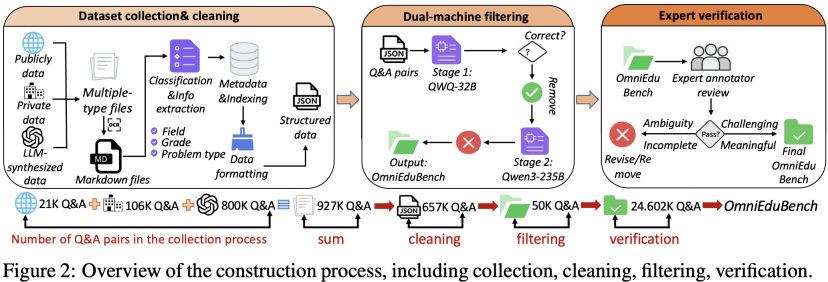
1.多源收集 (927K):汇聚公开数据 (21K)、内部试卷等私有数据 (106K),并利用LLM生成场景化问答 (800K),确保数据来源的多样性与独特性。
2.结构化清洗 (657K):统一格式,提取学科、年级、题型等元数据,并进行去重、去敏感内容、去外部信息依赖等标准化清洗流程。
3.双机筛难 (50K):为避免模型“背题”,用两款强大的模型进行“对抗式”筛选。先用QWQ-32B过滤掉它能答对的简单题,再用更强的Qwen3-235B进行二次筛选,只保留高难度样本。
4.专家定版 (24.6K):最后,由50位硕士生和5位资深专家进行最终的人工审核与质量校验。最终抽样质检显示:整体质量4.8/5,答案准确性4.8/5,标注者一致性高达0.90 。
4. 实验揭示残酷现实:最强闭源模型也难应对
研究团队在OmniEduBench上对11个主流的闭源和开源LLM(包括GPT-4o, Gemini-2.5 Pro, Claude-4 Sonnet, Qwen系列, DeepSeek-V3.1等)进行了全面测试,结果发人深省:
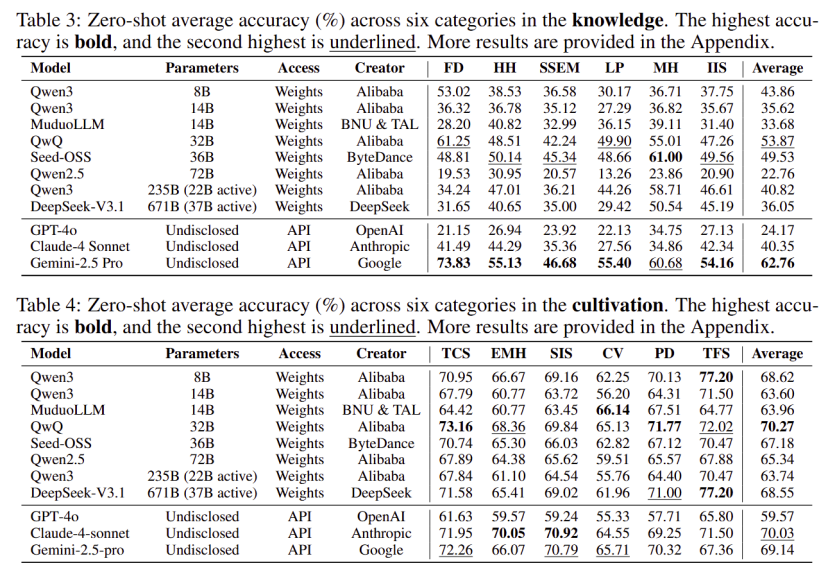
•发现一:知识维度“水土不服”,GPT-4o表现不佳在知识维度上,只有Gemini-2.5 Pro的平均准确率超过了60% (62.76%)。令人惊讶的是,强如GPT-4o在该项测试中表现不佳,准确率仅为24.17%,远低于多个顶尖开源模型(如QwQ-32B为53.87%)。这可能表明GPT系列在处理多样化、本土化的中文教育考试风格题目时存在明显的“水土不服”。
•发现二:“育人”能力是集体短板,距人类水平差距巨大在更关键的育人维度上,所有模型都暴露了短板。尽管任务形式相对简单(多为选择题),但即便是表现最好的模型(QwQ-32B,准确率70.27%),与人类在该领域的表现相比,仍有近30%的巨大差距。这表明当前LLM在同理心、启发式引导等高级教育能力上普遍缺乏。
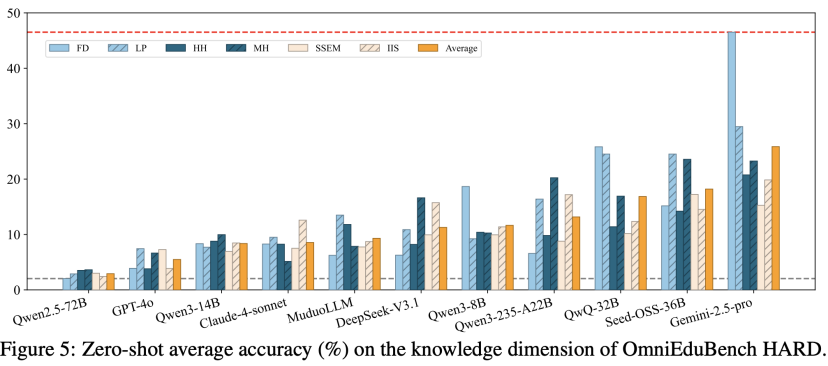
•发现三:高难度子集 (OmniEduBench HARD) 让顶尖模型“现形”研究团队还构建了一个高难度子集OmniEduBench HARD。在这个子集上,所有LLM的性能都出现了“断崖式”下跌,即便是最强的Gemini-2.5 Pro,准确率也不足50%,充分证明了该基准的挑战性和区分度。
为什么 OmniEduBench 很重要?
1.考验真实“可用性”:教育AI不应只是“解题器”。OmniEduBench首次将教育场景中的互动能力系统化、可量化,推动行业关注模型在启发、反馈等真实互动场景中的价值。
2.立足本土“适配性”:中文教育的语言文化与教学实践有其独特性。OmniEduBench是一个原生中文教育基准,从数据到任务定义都更“接地气”,能更准确地评估模型在本土环境下的表现。
5. 结语与展望
OmniEduBench的发布,为中文大模型在教育领域的评测提供了一个急需的、更全面的视角。它清晰地揭示了当前LLM的短板:尽管模型在知识获取上取得了长足进步,但在实现教育的核心目标——“育人”方面,仍有很长的路要走。研究团队表示,未来的工作将探索育人维度中更复杂的问题类型,并引入多模态教育场景,以持续推动LLM和MLLM在教育领域的综合能力发展。


