AI字幕总是慢半拍,质量和延迟难以平衡是业界老问题了。
为此,香港中文大学、字节跳动Seed和斯坦福大学研究团队出手,提出了一种面向同声传译的序贯策略优化框架 (Sequential Policy Optimization for Simultaneous Machine Translation, SeqPO-SiMT)。
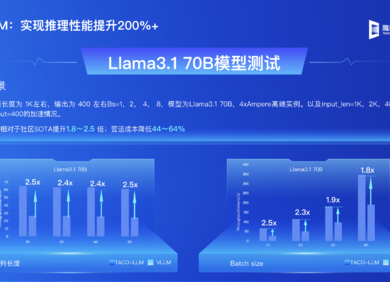
在70亿参数(7B)规模上实现SOTA。

实验结果显示,SeqPO-SiMT的翻译质量不仅优于监督微调(SFT)的离线模型及LLaMA-3-8B,其表现甚至能媲美乃至超越Qwen-2.5-7B的离线翻译水平。
方法:SeqPO-SiMT序贯策略优化
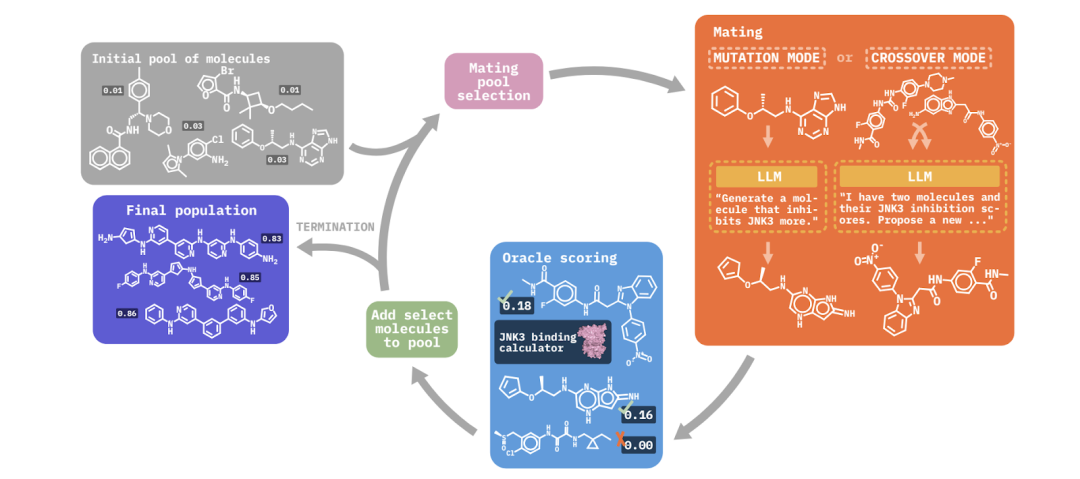
针对以上难点,研究团队提出SeqPO-SiMT框架。其核心思想是将同声传译任务建模为一个序贯决策问题,综合评估整个翻译流程的翻译质量和延迟,并对整个决策序贯进行端到端的优化。
该方法的主要特点是:它不再孤立地评估每一步决策的好坏,而是将一整句话的翻译过程视为一个整体,即形成一个完整决策序贯,更符合人类对同传的评估过程。
同声传译采样阶段
该框架使用一个大语言模型(LLM)充当策略模型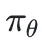 ,在每个时间步t,模型会接收新的源语言文本块
,在每个时间步t,模型会接收新的源语言文本块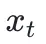 ,并基于已有的所有源文本
,并基于已有的所有源文本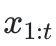 和之前的翻译历史
和之前的翻译历史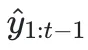 ,来生成当前的翻译块
,来生成当前的翻译块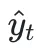 。
。
这个决策过程可以被形式化地表示为: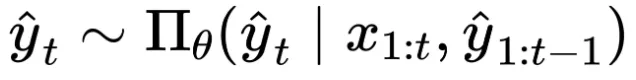
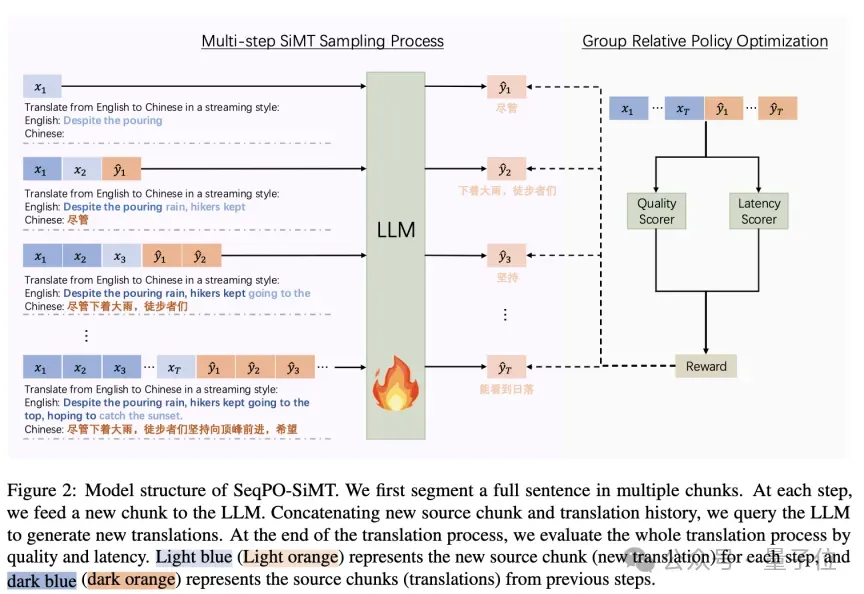
该框架的一个关键灵活性在于,如果模型决定等待更多上下文,输出的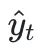 可以为空,其长度完全由策略模型
可以为空,其长度完全由策略模型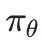 自行决定。
自行决定。
优化阶段
奖励函数:对于一个batch内的第i个样本,系统会通过一个在最终步骤T给予的融合奖励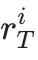 来评估整个过程的优劣。这个奖励同时评估翻译质量(Quality)和延迟(Latency)。
来评估整个过程的优劣。这个奖励同时评估翻译质量(Quality)和延迟(Latency)。
具体而言,首先计算出原始的质量分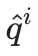 和延迟分
和延迟分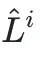 ,然后对两者进行归一化处理以统一量纲得到
,然后对两者进行归一化处理以统一量纲得到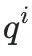 和
和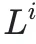 ,最终的奖励被定义为:
,最终的奖励被定义为: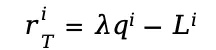
其中, 是一个超参数,用于权衡质量与延迟的重要性。
是一个超参数,用于权衡质量与延迟的重要性。
优化目标:模型的最终优化目标最大化期望奖励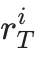 ,同时为了保证训练的稳定性,目标函数中还引入了KL散度作为约束项,防止策略模型
,同时为了保证训练的稳定性,目标函数中还引入了KL散度作为约束项,防止策略模型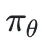 与参考模型
与参考模型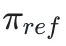 偏离过远。
偏离过远。
这个结合最终奖励和稳定性约束的优化过程,使得模型能够端到端地学会一个兼顾翻译质量与延迟的最优策略:
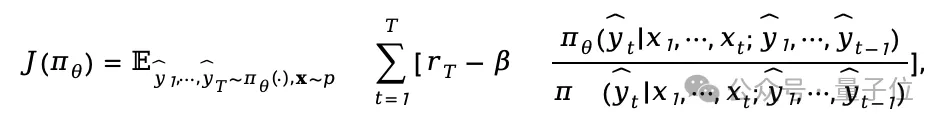

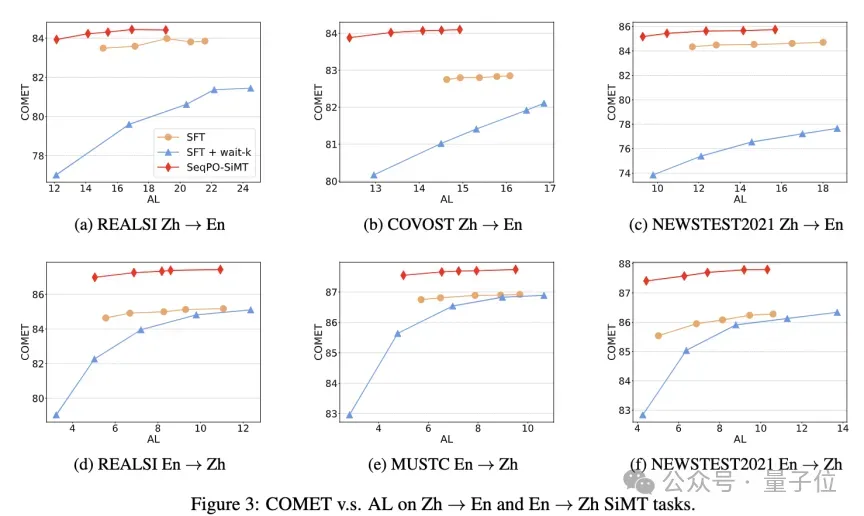
结果与分析:翻译质量媲美Qwen-2.5-7B离线翻译水平
研究团队在多个公开的英汉互译测试集上进行了实验,并与多种现有同传模型进行对比。实验结果显示:在低延迟水平下,SeqPO-SiMT框架生成的译文质量相较于基线模型有明显提升。
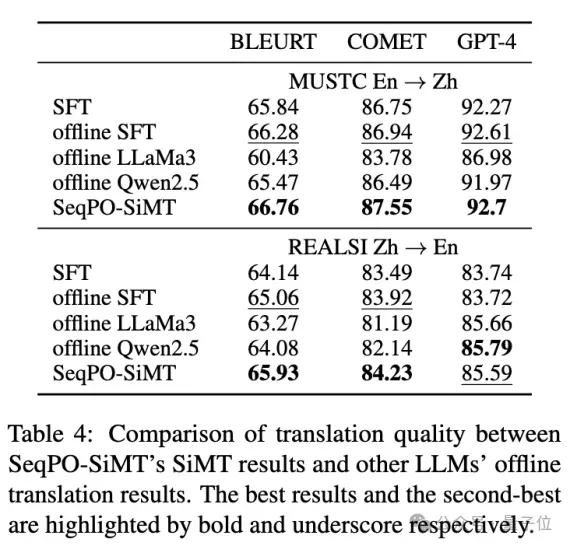
与多个高性能模型的离线翻译结果进行对比,结果显示,SeqPO-SiMT的翻译质量不仅优于监督微调(SFT)的离线模型及LLaMA-3-8B,其表现甚至能媲美乃至超越Qwen-2.5-7B的离线翻译水平。这表明该方法在70亿参数(7B)规模上实现了业界顶尖(SoTA)的性能。
SeqPO-SiMT为解决同声传译中的“质量-延迟”权衡问题提供了一个新的视角,它强调了对决策“序贯”进行整体优化的重要性。该方法对于需要进行实时、连续决策的自然语言处理任务具有一定的参考意义,并为未来开发更高效、更智能的同声传译系统提供了有价值的探索。
论文链接:https://arxiv.org/pdf/2505.20622