字节开源图像编辑新方法,比当前SOTA方法提高9.19%的性能,只用了1/30的训练数据和1/13参数规模的模型。
做到这一切无需额外预训练任务和架构修改,只需要让强大的多模态模型(如GPT-4o)来纠正编辑指令。

这一方法旨在解决现有图像编辑模型中监督信号有噪声的问题,通过构建更有效的编辑指令提升编辑效果。
数据和模型在Github上开源。
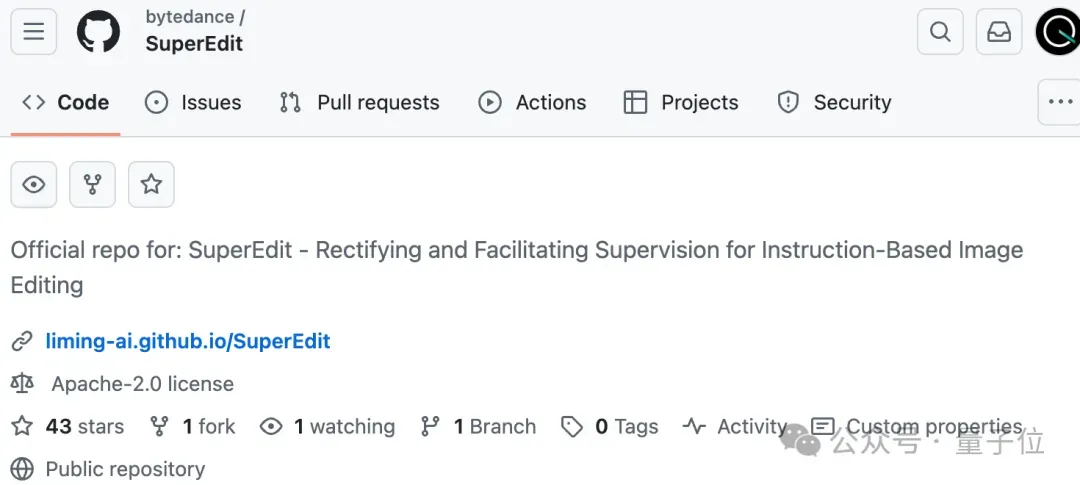
为什么AI编辑图像模型常常“理解错误”
当人们让AI”给照片中的男孩加一条粉色领带”时,AI可能会把皮肤颜色、衣服颜色也改变,或者完全重绘整张图片。
为什么会这样?

团队发现了一个被忽视的关键问题:现有的图像编辑数据集存在大量的噪声监督信号。
当前基于指令的图像编辑方法流行起来,但训练这类模型需要大量原始-编辑后图像对和指令,手动收集困难。
现有数据集通常使用各种自动化方法构建,导致指令与图像对之间的不匹配,产生有噪声的监督信号。
简单来说就是:AI在学习时,看到的指令和实际编辑效果对不上号,导致”学废了”。
如此一来,SuperEdit的方法就不是靠扩大参数规模或增加预训练算力,而是专注于提高监督信号质量。
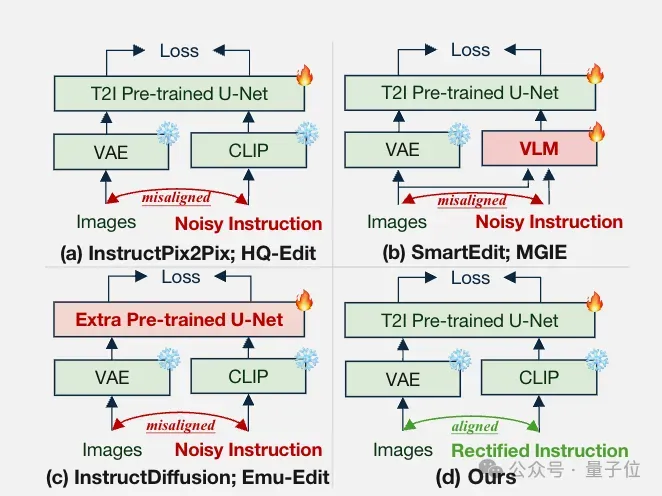
用GPT-4o纠正编辑指令
团队首先发现,扩散模型在生成图像的不同阶段有着不同侧重点。
- 早期阶段:关注全局布局变化
- 中期阶段:关注局部物体属性变化
- 晚期阶段:关注图像细节变化

受此启发,团队利用GPT-4o这样的强大视觉语言模型,通过观察原始图像和编辑后图像之间的差异,生成更准确的编辑指令。
将原始图像和编辑后的图像输入到GPT-4o中,并要求它返回以下四个属性的差异:整体图像布局、局部对象属性、图像细节、样式变化。
由于CLIP文本编码器最多接受77个文本token输入,还需要让GPT-4o总结完善这些指令。

仅仅有正确的指令还不够,团队还构建了一套对比监督机制:
- 根据正确的编辑指令,生成一系列错误指令(如改变物体数量、位置或颜色)
- 使用三元组损失函数(triplet loss)让模型学会区分正确和错误的编辑指令
由于在正确指令和错误指令之间只替换了几个单词,因此CLIP文本编码器生成的文本嵌入作为扩散模型的输入也会很相似。
通过这一点确保学习任务的难度,帮助模型了解两个编辑指令之间的细微差异如何导致截然不同的编辑结果。
编辑模型训练基于InstructPix2Pix框架,利用对比监督信号时,在训练阶段引入错误编辑指令生成正负样本,提升模型理解和执行指令的能力。
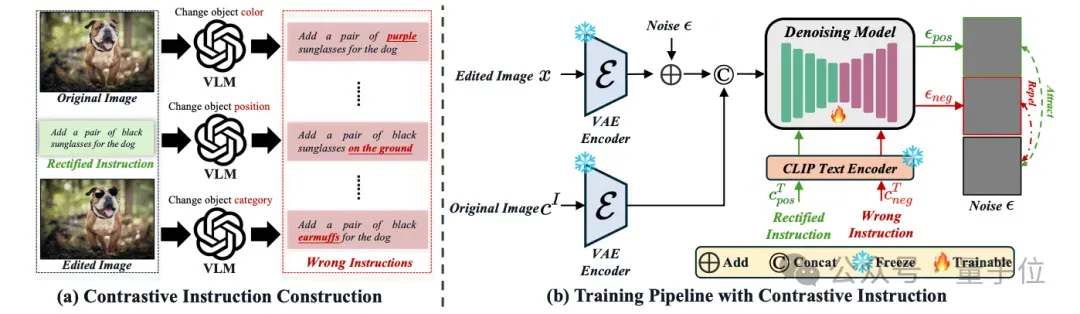
SuperEdit在多个基准测试上的表现出色,在Real-Edit基准测试中,它以69.7%的整体准确率和3.91的评分,超越前SOTA方法SmartEdit的58.3%准确率和3.59评分。
在人工评估中,SuperEdit在指令遵循度、原始内容保留和图像质量三个关键指标上全面超越了现有方法。

不过该方法也存在一些局限,经过训练的模型在理解和执行复杂指令上仍然存在困难,尤其是在密集排列的对象和复杂的空间关系方面。
以及为确保校正指令的准确性和有效性大量调用GPT-4o,可能产生额外的成本。
团队计划将这种数据优先的方法扩展到更多视觉生成任务中,并探索与更大模型相结合的可能性。
论文:https://arxiv.org/abs/2505.02370xia


