无论是语速超快、发音复杂的绕口令,还是精妙绝伦的文言文,又或是充满即兴和灵感的随意聊天,模型都能流畅自然地给出准确而地道的翻译结果。
近年来,人工智能(Aritificial Intelligence, AI),尤其是以大语言模型(Large Language Models, LLMs)为代表的 AI 正以惊人的速度发展,这些模型在多种自然语言处理任务中展现了卓越的能力。然而,尽管在许多领域取得了突破,代表着人类顶尖语言水平的同声传译(Simultaneous Interpretation, SI)依然是一个未被完全攻克的难题。
市面上传统的同声传译软件通常采用级联模型(cascaded model)的方法,即先进行自动语音识别(Automatic Speech Recognition, ASR),然后再进行机器翻译(Machine Translation, MT)。这种方法存在一个显著的问题 —— 错误传播。ASR 过程中的错误会直接影响到后续的翻译质量,导致严重的误差累积。此外,传统的同声传译系统由于受限于低延时的要求,通常只使用了性能较差的小模型,这在应对复杂多变的实际应用场景时存在瓶颈。
来自字节跳动 ByteDance Research 团队的研究人员推出了端到端同声传译智能体:Cross Language Agent - Simultaneous Interpretation, CLASI,其效果已接近专业人工水平的同声传译,展示了巨大的潜力和先进的技术能力。CLASI 采用了端到端的架构,规避了级联模型中错误传播的问题,依托于豆包基座大模型和豆包大模型语音组的语音理解能力,同时具备了从外部获取知识的能力,最终形成了足以媲美人类水平的同声传译系统。

论文地址:https://byteresearchcla.github.io/clasi/technical_report.pdf
展示页面:https://byteresearchcla.github.io/clasi/
效果展示
视频 Demo:首先用几则即兴视频来感受一下 CLASI 的效果,所有字幕均为实时录屏输出。我们可以看到,无论是语速超快、发音复杂的绕口令,还是精妙绝伦的文言文,又或是充满即兴和灵感的随意聊天,模型都能流畅自然地给出准确而地道的翻译结果。更不用说,CLASI 在其老本行 —— 会议场景翻译中表现得尤为出色。
即兴对话-星座 朗读-赤壁赋
朗读-赤壁赋  绕口令
绕口令 
更多视频可点击「阅读原文」进行查看
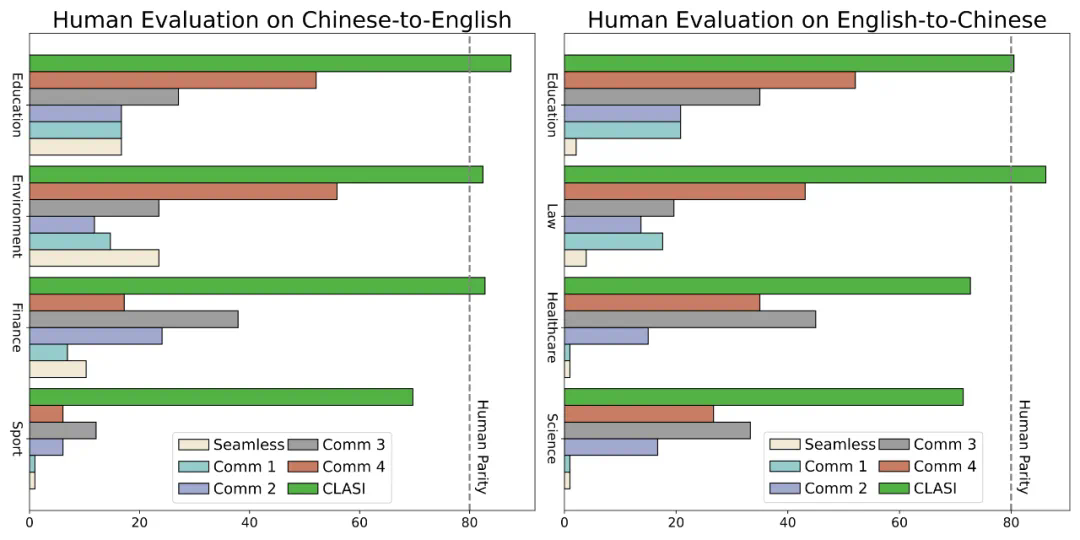
定量对比:研究人员分别在中英、英中翻译语向上,针对 4 个不同领域邀请专业的同传译员进行了人工评测,使用了与人工同传一致的评价指标:有效信息占比(百分制)。图中可以看到,CLASI 系统大幅领先所有商业系统和开源 SOTA 系统,并且在某些测试集上甚至达到或超过了人类同传水平(一般认为人类同传平均水平大概在 80%)。
系统架构
系统架构上,CLASI 采用了基于 LLM 智能体的架构(下图左),将同声传译定义为一系列简单且协调的操作,包括读入音频流,检索(可选),读取记忆体,更新记忆体,输出等。整个流程由大语言模型自主控制,从而在实时性和翻译质量之间达到了高效的平衡。该系统能够根据实际需求灵活调整各个环节的处理策略,确保在高效传递信息的同时,保持翻译内容的准确性和连贯性。CLASI 底层模型是一个 Encoder-conditioned LLM,在海量的无监督和有监督数据上进行了预训练。CLASI 模型的系统架构如下图所示。
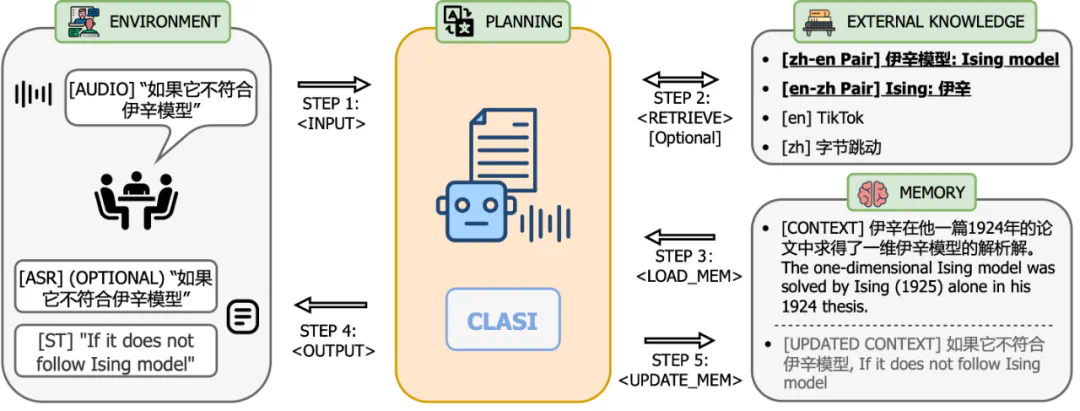
图 1:图示展示了 CLASI 的整体操作流程。在步骤 1 中,CLASI 处理当前输入的音频数据。接下来检索器会被激活(可选),从用户自定义的知识库中获取相关信息。在这个示例中,使用知识库中的翻译对 “伊辛模型: Ising model” 能够帮助模型输出正确的译文。在步骤 3 中,CLASI 从上一轮的记忆体中加载转写(可选)和翻译。接下来(步骤 4 和步骤 5),CLASI 可能会启用思维链(CoT)来输出转写(可选)和翻译结果,然后更新其记忆体。最后,返回步骤 1 以处理下一轮的语音。
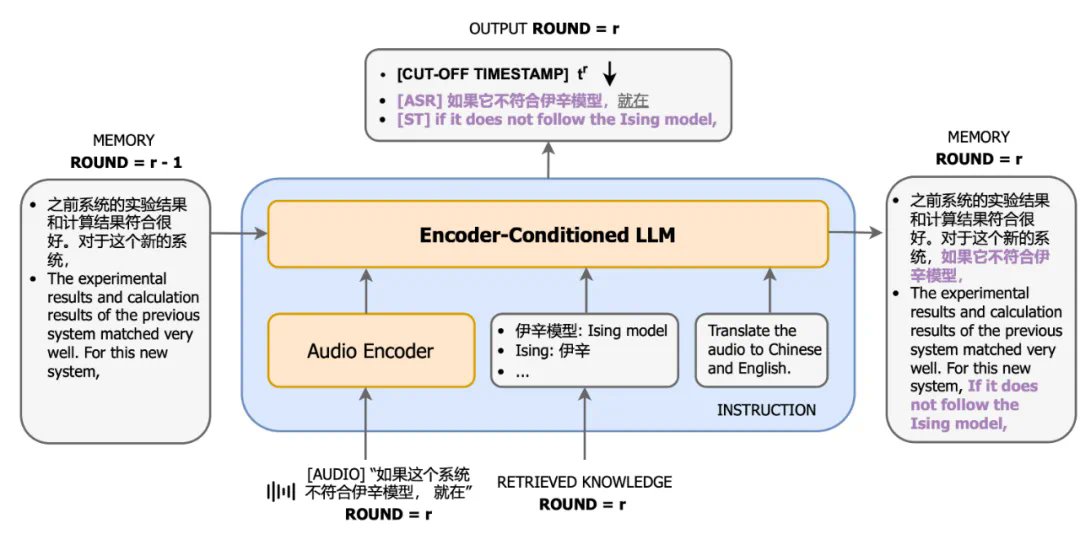
图 2:CLASI 的结构图。在第 r 轮中,CLASI 将当前音频流、前序的记忆体(r-1)和检索到的知识(如果有)作为输入。CLASI 根据给定的指令输出响应,然后更新记忆体。同时,CLASI 还会输出截止当前,最后一个语义片段的截止时间戳。对于给定的示例,短语 “就在” 之前的内容被认为是完整的语义片段,所以截止时间戳就在此短语之前。
实验结果
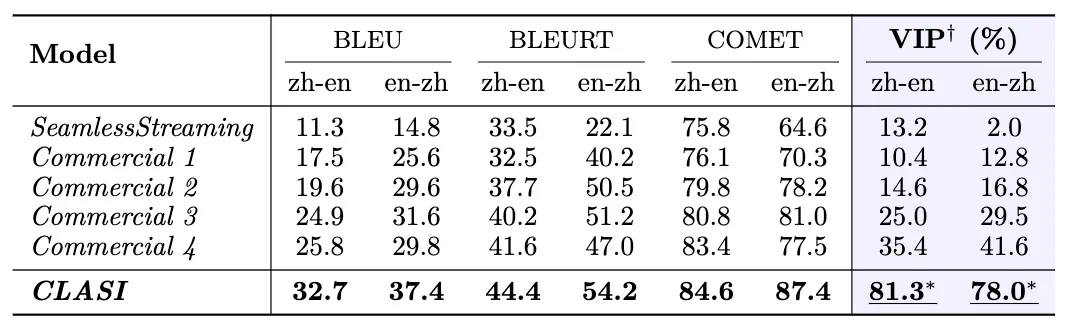
表 1:人工评测有效字段占比(Valid Information Proportion, VIP)中,CLASI 系统显著超过了其他所有竞品,并且在两个语向上均达到了 78% 以上的准确性。一般而言,可以认为人类同传的准确性在 70% 以上,理想情况下可以达到 95%,研究人员以 80% 的准确性作为高水平人类译员的平均标准。
示例分析
中翻英: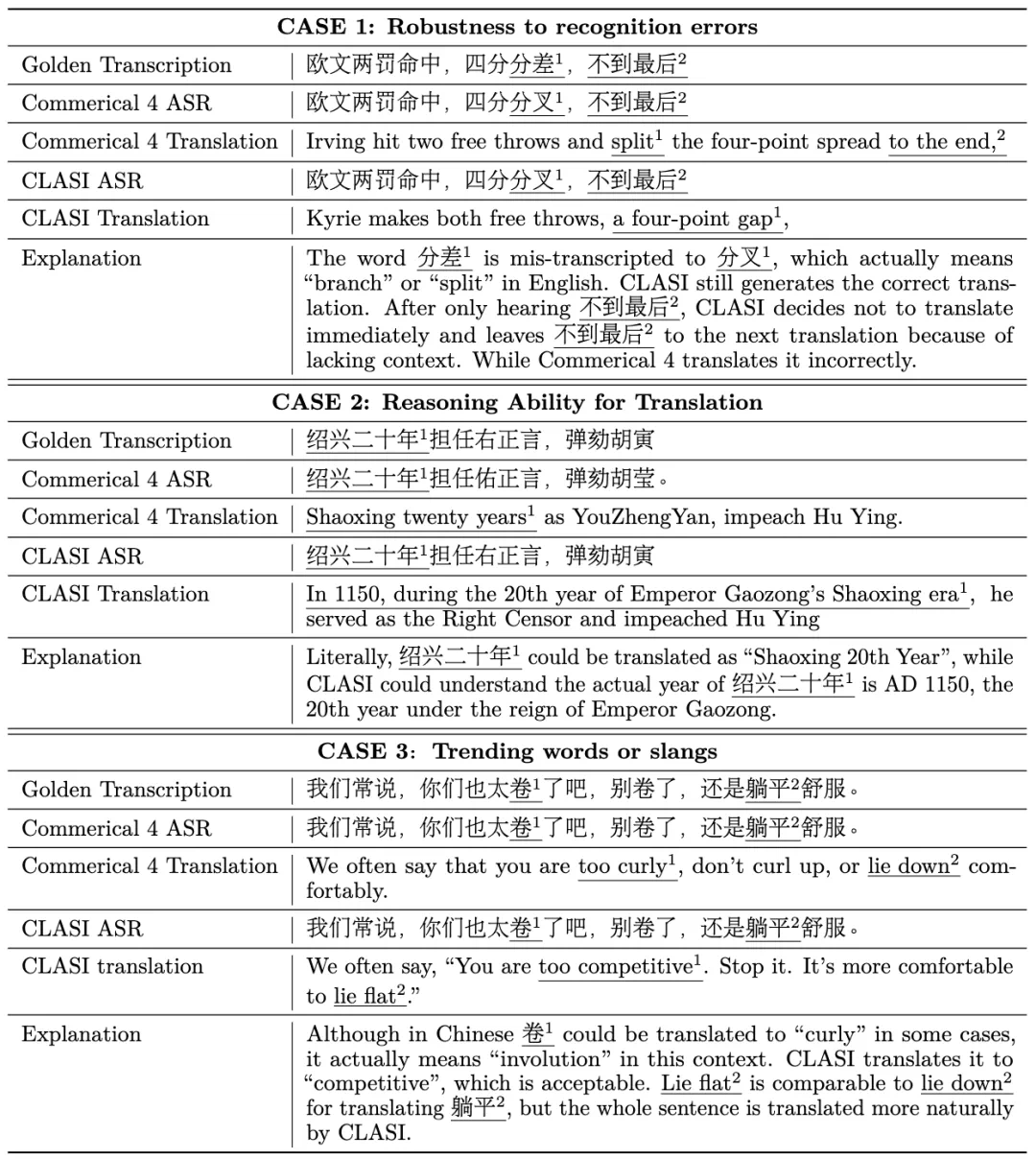
英翻中:
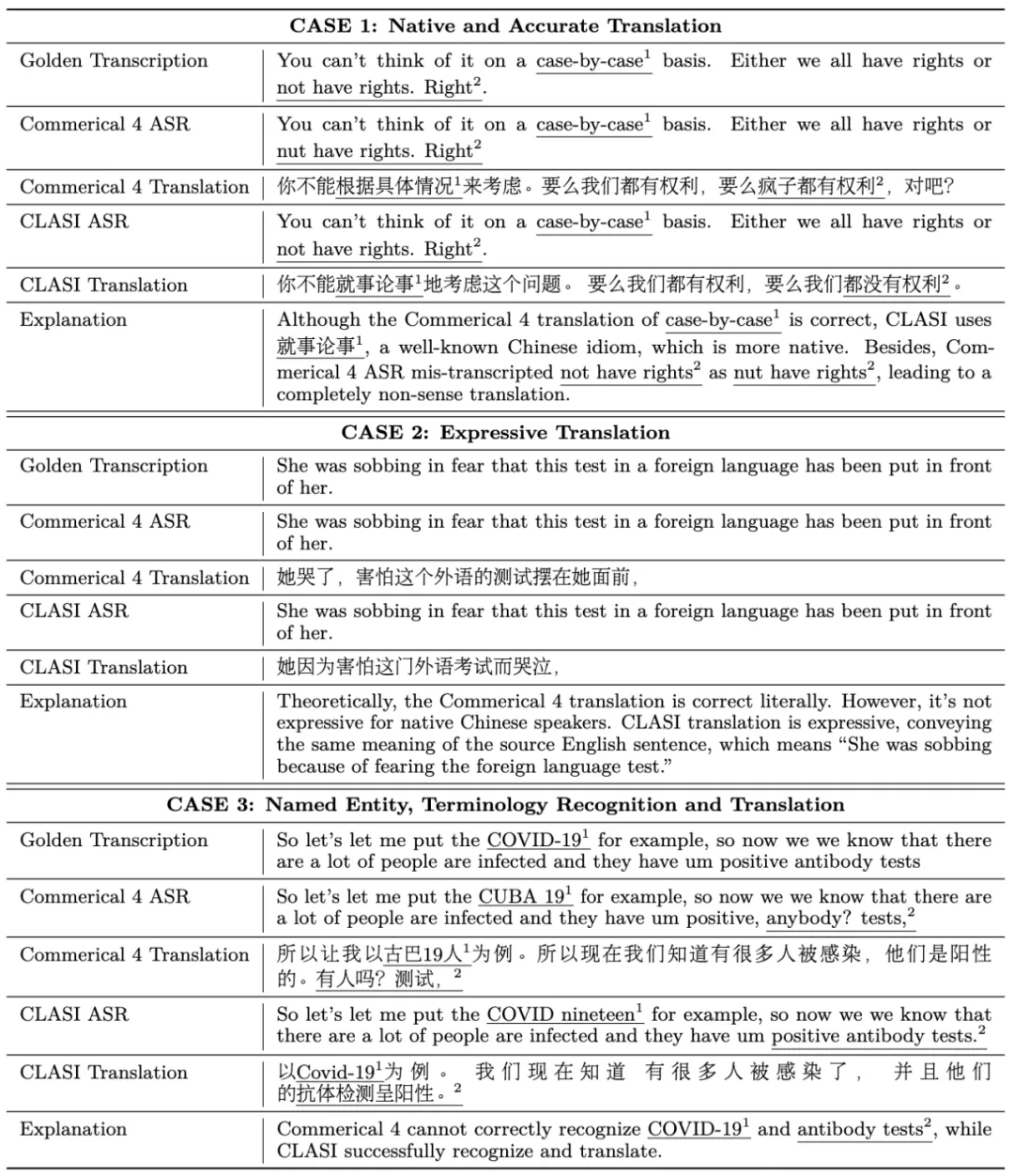
可以看到在多个方面,CLASI 的翻译均显著优于商用系统。
总结
来自字节跳动 ByteDance Research 团队的研究人员提出了基于豆包大模型的同传智能体:CLASI。得益于大规模预训练和模仿学习,在人工评估中,CLASI 的表现显著优于现有的自动同声传译系统的性能,几乎达到人类同传水平。
1. 研究人员提出了一种通过模仿专业人类译员的、数据驱动的读写策略。该策略无需复杂的人类预设计,即可轻松平衡翻译质量和延迟。与大多数商业系统在翻译过程中频繁重写输出以提高质量不同,该策略保证所有输出在保持高质量的同时是确定性的。
2. 人类译员一般需要预先准备同传内容,受此启发,研究人员引入了一种多模态检索增强生成(MM-RAG)过程,使 LLM 实时地具有领域特定的知识。所提出的模块在推理过程中以最小的计算开销进一步提高了翻译质量。
3. 研究人员与专业人类同传译员密切合作,制定了新的人工评估策略 “有效信息占比”(VIP),并公开了详细的指南。同时也发布了一个更接近现实场景的长语音翻译的多领域人工标注测试集。


