谷歌DeepMind刚刚又往前拱了一大步,宣布推出 AlphaEvolve智能体 ,目标直指更上游,用于通用算法的设计发现和优化
简单说,AlphaEvolve就像个AI界的“算法育种大师”。它把自家Gemini大模型(Gemini Flash负责广撒网,洞察力强的Gemini Pro负责深挖)和一套“自动化考官”(负责验证算法靠不靠谱、效率高不高)结合起来,再套上一个“进化论”的框架,让好算法能一代更比一代强
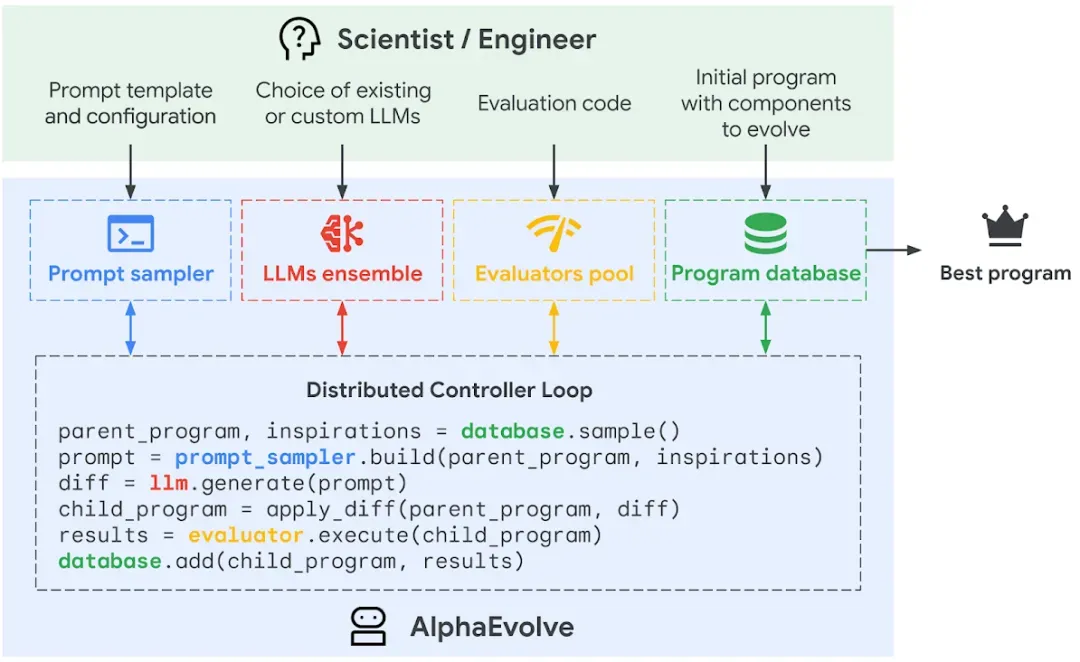
AlphaEvolve工作流程:工程师设定框架,AI通过“提示采样器”给LLM喂招,LLM出新招(程序),“考官”打分,好招进“兵器谱”,并用来启发下一轮出招。
去年DeepMind就秀过肌肉,证明LLM能生成代码函数来搞定科学问题。但AlphaEvolve的野心是进化一整个代码体系,去啃那些更复杂的算法硬骨头。
AlphaEvolve已经在谷歌内部“上岗”了
AlphaEvolve已经在谷歌的多个核心业务里默默发光发热了:
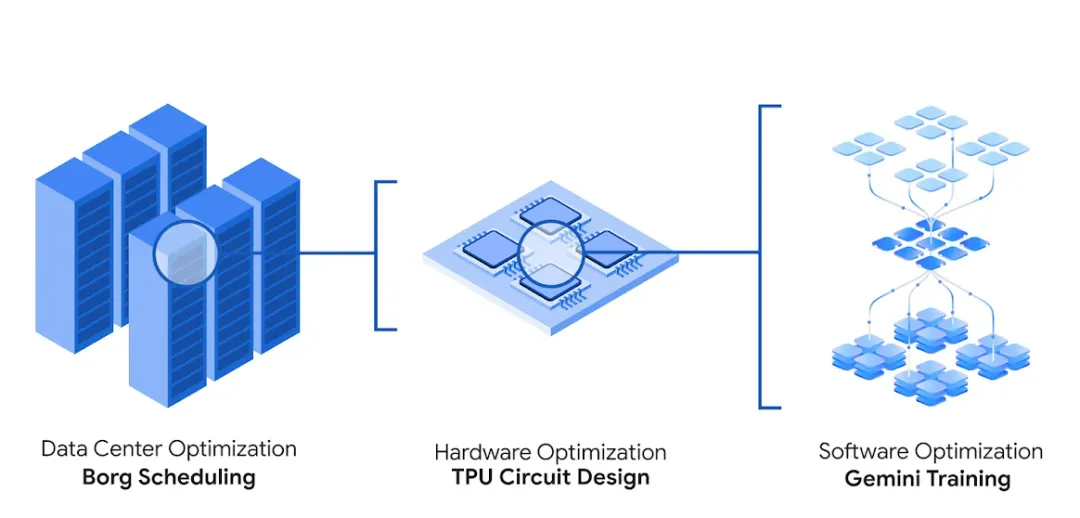
1.改善数据中心调度:
AlphaEvolve给谷歌庞大的数据中心Borg系统发现了一种简单却极其有效的启发式方法。这套方案上线一年多,平均给谷歌全球计算资源抠回了0.7%的算力
2.设计芯片 (TPU Circuit Design):
在谷歌的AI芯片TPU设计中,AlphaEvolve直接上手改起了Verilog(芯片设计语言)。它优化了一个矩阵乘法关键电路,去掉了冗余。改动通过了严格的“体检”,确认功能没问题,已经被用在了下一代TPU里
3.给AI训练和推理再提提速:
AlphaEvolve找到了更巧妙的方法来拆解大矩阵乘法,让Gemini架构里的这个核心“零部件”快了23%,最终给Gemini模型的训练省了1%的时间。对大模型训练这种“吞金兽”来说,1%也是肉。工程师们也从几周的苦哈哈优化,变成了几天的自动化实验,能更快搞创新了
它甚至还能优化底层的GPU指令。对于Transformer模型里常用的FlashAttention,AlphaEvolve给整出了最高32.5%的加速。这块通常是编译器啃的硬骨头,人一般不轻易动
不止搞工程,数学前沿它也敢闯
AlphaEvolve的目标不只是优化现有系统,它还想在更基础的数学和算法发现上取得突破:
矩阵乘法新算法:
给定一个基础代码框架,AlphaEvolve设计出了一种新颖的基于梯度的优化过程,发现了多个矩阵乘法新算法。例如,它找到了一个用48次标量乘法计算4x4复数矩阵乘积的算法,优于自1969年以来已知的Strassen算法。这比DeepMind之前的AlphaTensor(专攻矩阵乘法,但对4x4矩阵只在二元算术上找到改进)又进了一步
攻克公开数学难题:
DeepMind用AlphaEvolve尝试了超过50个来自数学分析、几何、组合学和数论的公开问题,在约 75% 的案例中,它重新发现了当前已知的最优解。在约20%的案例中,它改进了已知的最优解!
例如,在困扰了数学家300多年的“接吻数问题”(Kissing Number Problem,即一个中心球最多能同时接触多少个不重叠的等大球体)上,AlphaEvolve在11维空间中发现了一个包含593个外层球的构型,刷新了该维度下的已知下界
对数学成果感兴趣的,DeepMind也放了些结果在Google Colab上,地址:
https://colab.research.google.com/github/google-deepmind/alphaevolve_results/blob/master/mathematical_results.ipynb
写在最后
大语言模型的编码能力还在进化,AlphaEvolve也会跟着变强。谷歌目前推出了早期试用计划,先给学术圈的朋友们尝尝鲜,想尝鲜的可以去DeepMind官网填个表
https://docs.google.com/forms/d/e/1FAIpQLSfaLUgKtUOJWdQtyLNAYb3KAkABAlKDmZoIqPbHtwmy3YXlCg/viewform
想深挖的,paper地址:
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/AlphaEvolve.pdf


