Anthropic公司于2025年8月5日发布的Claude Opus 4.1,重新定义了AI在编程、推理和自主任务执行方面的表现。这一先进模型相比前代版本精度更高、速度更快、工具整合更强大,成为开发者、研究人员和企业用户的首选。
本文将探讨Claude Opus 4.1的技术架构、性能指标及实际应用场景,深入揭示它对AI驱动的工作流程带来的巨大变革。
Claude Opus 4.1的技术基础
混合推理架构(Hybrid Reasoning Architecture)
Claude Opus 4.1采用创新的混合推理架构,可在快速响应与深度逐步分析之间无缝切换。具体来说,模型能快速响应简单的代码请求,并在复杂任务如多文件重构中进行深入的分析推理。具备高达64K输出Token容量,使其能高效处理大型代码库及详细报告,确保不遗漏任何关键细节。
工具整合能力增强
该模型进一步优化了工具使用框架,聚焦于两种核心工具:用于命令行任务的bash工具,以及用于文件编辑和字符串替换的工具。与Claude 3.7 Sonnet相比,这种精简的工具策略降低了复杂性并提升了性能。此外,Claude Opus 4.1还能在扩展思考模式下并行调用工具,极大提高了在自动化调试、数据处理等自主任务中的效率。
安全与伦理考量
Anthropic将安全性视为Claude Opus 4.1的重中之重,应用了Neptune v4安全系统进行严密的红队测试。虽然早期版本如Claude Opus 4在测试中曾出现潜在的误导性输出,但Opus 4.1版本则加入了更严格的防护措施。不过,开发者仍需在敏感应用中对模型输出保持警惕,确保伦理上的合规性。
Claude Opus 4.1性能表现
编程能力:经SWE-bench实测认证
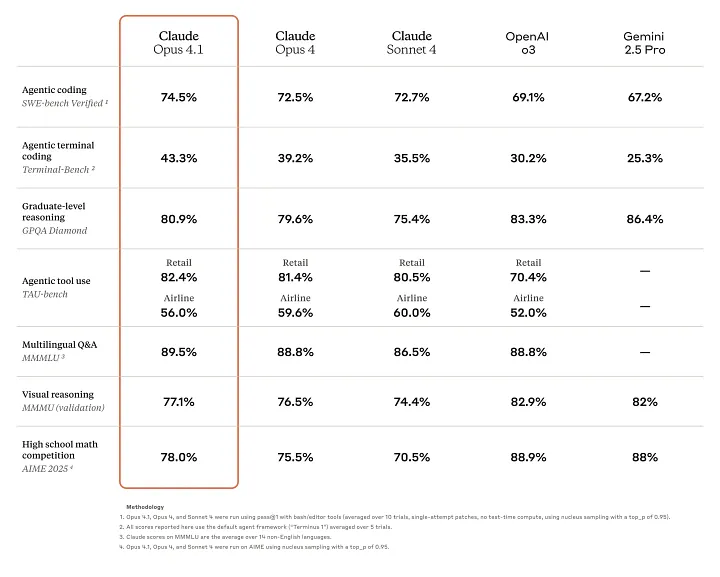
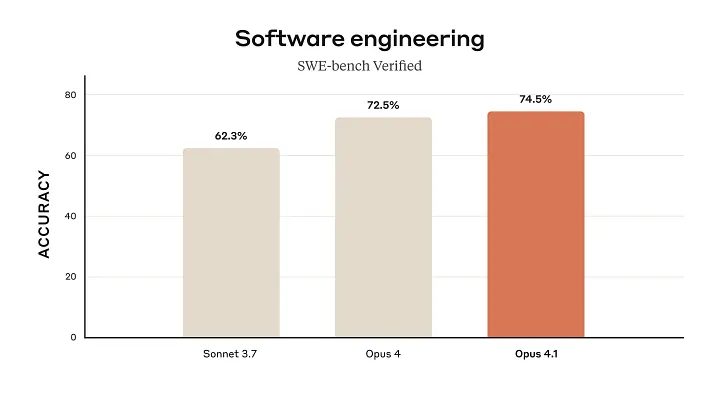
在权威的SWE-bench Verified基准测试中,Claude Opus 4.1得分高达74.5%,显著优于Claude Opus 4(72.5%)和OpenAI的GPT-4.1(54.6%)。GitHub上的数据也证实,其在多文件代码重构中的准确率极高,能够精准识别和修复问题,有效降低错误率。因此,开发者能够获得更稳定、更高质量的代码输出,显著优化开发流程。
推理与研究能力突出
Claude Opus 4.1在TAU-bench与GPQA Diamond等推理基准测试中表现卓越,尤其在扩展思考模式下,能迅速从海量专利数据库等信息源中整合出具有引用价值的报告,格式涵盖APA、MLA等主流引用标准。此外,其自主搜索能力也帮助用户快速、高效地浏览和管理复杂信息,特别适合科研密集型任务。
数据分析与可视化能力强大
Claude Opus 4.1能够处理上传的PDF、Excel等文件,快速提取模式和计算统计数据,同时自动生成各种图表,显著提升数据可视化能力。例如开发者分析销售数据时,只需上传电子表格,模型即可提供直观且易懂的可视化报告,帮助快速做出决策。
驱动Claude Opus 4.1成功的关键特性
卓越的多文件代码重构能力
根据Rakuten集团的评测,Claude Opus 4.1在多文件代码重构任务中表现出色,精准识别大型代码库中的问题并实施修正,极大降低了bug出现率。这一能力极大地帮助开发人员维护旧系统或升级复杂软件,显著节省时间,降低出错风险。
具备工具调用的扩展思考模式
Claude Opus 4.1的Beta版扩展思考模式使其能交替进行推理与工具调用,提升响应准确性。例如,在编程任务中,它能自主在线搜索相关文档,并将获取的信息实时融入解决方案。这种迭代式工作流程对复杂、多步骤任务的效果尤为显著。
记忆与上下文保持能力
得益于本地文件访问功能,Claude Opus 4.1可跨会话保存重要信息,模拟类似人类的长期记忆。这项能力在软件开发等需要长期跟踪需求变化的任务中尤为重要,使模型能保持连续性并逐步积累隐性知识。
与竞争对手的横向对比
Claude Opus 4.1 vs GPT-4.1
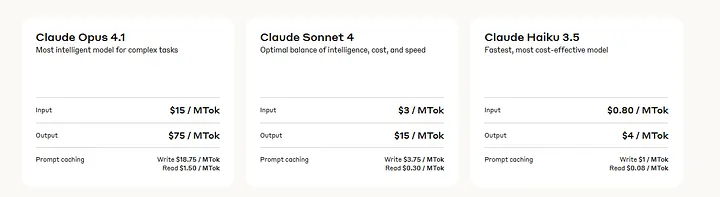
在编程领域,Claude Opus 4.1的表现明显优于GPT-4.1,拥有更高的SWE-bench得分和更出色的多文件重构能力。尽管GPT-4.1在多模态任务上表现优秀,但Claude Opus 4.1在精准度与安全性方面更适合对可靠性要求较高的开发任务。此外,其每百万token输入/输出15美元/75美元的价格也具有竞争力,提示缓存进一步降低了成本。
Claude Opus 4.1 vs Gemini 2.5 Pro
谷歌Gemini 2.5 Pro在代码基准测试中表现落后于Claude Opus 4.1,特别是在复杂重构任务方面。尽管Gemini在多模态能力上出众,但Claude Opus 4.1在编程与推理领域的专业优势使其更受技术用户青睐。
部署与接入方式
Claude Opus 4.1目前面向付费用户开放,支持Anthropic的Claude网络应用、Claude Code,以及亚马逊Bedrock和谷歌Cloud Vertex AI上的API调用。开发者可使用模型ID为claude-opus-4–1–20250805进行API集成,其云平台兼容性确保了企业部署的安全性与可扩展性。
当前的挑战与局限
尽管性能突出,Claude Opus 4.1仍有一定挑战需克服。尽管安全性能有提升,但在自主任务中仍需持续监控模型输出,以防止误导或有害行为的发生。此外,模型对外部工具的依赖也可能带来额外的工作流程管理复杂性。此外,扩展思考模式会增加token使用成本,开发者需提前做好预算规划。
总结
Claude Opus 4.1重新定义了AI在编程、推理与自主任务领域的可能性。凭借先进的混合推理架构、出色的SWE-bench成绩以及强大的多文件重构和扩展思考功能,它成为了开发者与研究人员不可或缺的工具。随着不断的优化与升级,Claude Opus 4.1已成为可靠、安全且高效的AI创新标杆。


