知识图谱推理(Knowledge Graph Reasoning)是人工智能的重要组成部分,在问答系统、推荐系统、语义检索和知识增强大模型等场景中具有广泛应用。
然而,随着知识图谱规模的爆炸式增长,现有推理方法在计算效率、模型表达能力和泛化能力方面面临巨大挑战。
现有知识图谱推理方法主要存在以下三类问题:
- 推理效率低:随着知识图谱实体规模增长,候选实体空间极速膨胀,导致推理阶段计算成本急剧上升;
- 表达能力不足:轻量级嵌入模型虽计算高效,但难以捕捉多跳关系和高阶语义结构;
- 过平滑问题突出:基于全局注意力或深层GNN的方法容易在图上过度聚合信息,导致表示不具判别力(如图1所示)。
这些瓶颈严重限制了知识图谱推理在真实大规模场景中的落地。
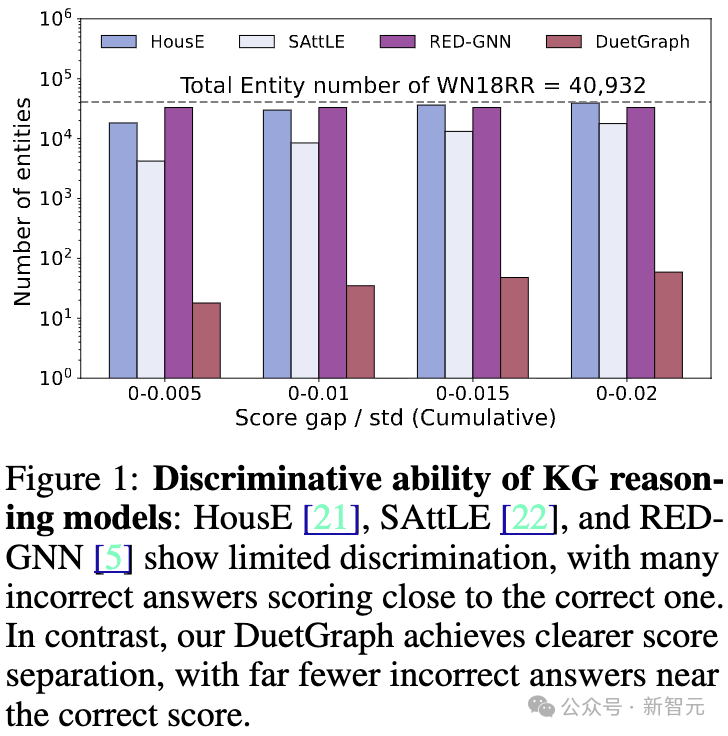
图1 知识图谱推理模型区分能力对比
为此,中科大研究团队在NeurIPS 2025上提出了DuetGraph:一种双阶段粗到细推理框架,并创新性地引入了Dual-Pathway Global-Local Fusion Model(双通路全局-局部特征融合模型)。

论文链接:https://arxiv.org/pdf/2507.11229
代码链接:https://github.com/USTC-DataDarknessLab/DuetGraph.git
DuetGraph在推理精度与推理效率之间实现了新的平衡,为高效大规模知识推理提供了可落地的系统性解决方案。
DuetGraph解决方案
粗到细的协同推理
DuetGraph的核心思想是将推理拆分为粗粒度召回和细粒度精排两个阶段,在候选空间和模型表达能力之间取得平衡:
- 粗粒度阶段(Coarse Reasoning)使用高效的知识图谱嵌入模型在全图范围内进行快速推理,召回一小部分高概率候选实体,从而大幅缩小搜索空间。
- 细粒度阶段(Fine Reasoning)对召回的候选实体使用更具表达力的推理模型进行高质量排序,实现复杂推理路径的精准捕捉。
这种两阶段的Coarse-to-Fine架构,将原本不可承受的全图精排,转化为在小规模候选集上的高效精排,使得性能与计算成本得到兼顾。
双通路全局-局部特征融合模型
在细粒度推理阶段,DuetGraph并未简单采用传统的单一的Transformer和GNN路径,而是设计了一个创新的双通路架构:
- Local-Pathway:利用图神经网络(GNN)建模局部结构信息,捕捉实体之间的邻域交互模式,强调局部语义一致性;
- Global-Pathway:采用Transformer的全局注意力机制捕捉全局结构依赖,挖掘长距离、多跳推理路径信息。
为了避免简单拼接带来的信息冗余和过平滑,DuetGraph引入了Adaptive Fusion 模块,通过一个自适应参数α在局部路径与全局路径之间进行动态加权,实现:
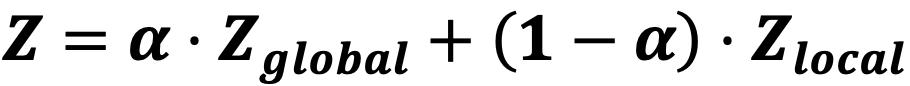
其中α可在训练过程中自动学习,适应不同关系模式和上下文复杂度。这一机制兼具局部鲁棒性与全局表达能力,使 DuetGraph在复杂推理任务中具有更强的泛化性。
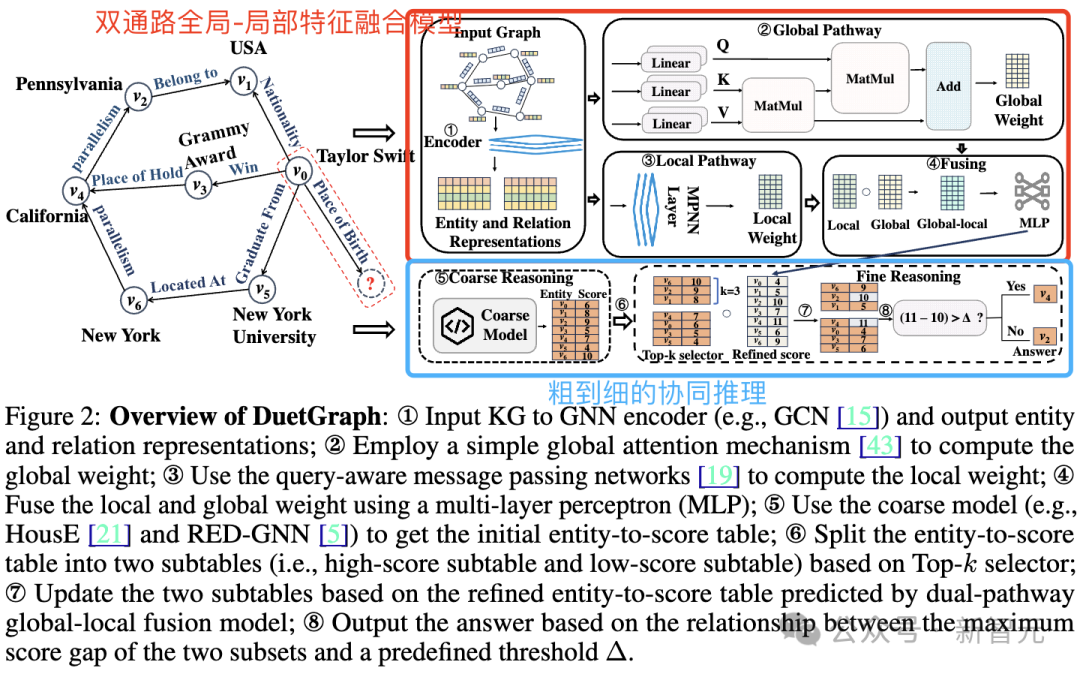
图 2 DuetGraph框架示意图
理论分析
在知识图谱推理中,过平滑(over-smoothing) 是影响推理精度的核心瓶颈之一。
随着传播层数增加,实体的表示逐渐趋同,正确答案与干扰实体之间的得分差距被快速抹平,从而导致模型的判别能力下降。
DuetGraph 在理论设计上,通过双通路全局-局部特征融合(Dual-Pathway Global-Local Fusion)和粗到细推理(Coarse-to-Fine Reasoning),在结构上减缓了得分收敛速度,并在推理过程中放大了正确与错误实体的得分差距,从而显著缓解过平滑问题。
双通路融合:从结构上减缓过平滑
传统单通路模型通常将GNN和Transformer串联,会导致特征经过多层传播后快速趋同,使得实体得分的上界以指数形式收敛。
DuetGraph将推理分解为局部路径(Local Pathway)和全局路径(Global Pathway),并通过自适应融合参数α对两路输出进行动态加权。
从理论上来看,模型中得分差距的收敛速度与其特征传播矩阵的最大奇异值(σ(max))直接相关。
- 单路径模型的传播矩阵
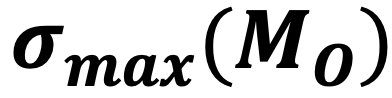 较小, 因此得分差异在多层传播后被迅速压缩;
较小, 因此得分差异在多层传播后被迅速压缩; - 双通路模型的传播矩阵
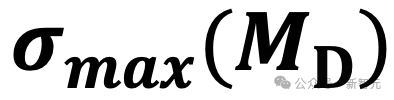 ,由于引入了包含α的加权融合机制,其理论上界显著大于单路径模型,即
,由于引入了包含α的加权融合机制,其理论上界显著大于单路径模型,即
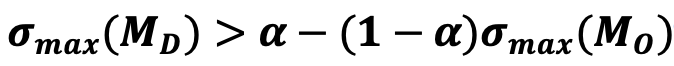
在实际训练过程中,α的取值始终处于稳定且合理的范围,使得该不等式始终成立,即
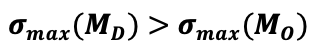
这意味着在相同传播深度下,双通路模型的得分差距上界下降得更慢,模型更不容易陷入过平滑状态。
换句话说,DuetGraph在模型结构层面天然具备抗过平滑能力,即便在大规模图和多跳推理场景中,也能保持对实体间差异的敏感性。
粗到细推理:放大得分差距,增强判别力
除了结构上的改进,DuetGraph在推理过程中进一步引入粗粒度 + 细粒度的两阶段策略。
在粗粒度阶段,模型首先利用轻量级推理机制快速筛选出一小部分高概率候选实体,并划分为高分子集与低分子集;
在细粒度阶段,对两个子集分别使用双通路模型精排,并通过设定阈值Δ来动态选择最优答案。
理论推导表明,由于低分子集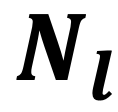 的规模远大于高分子集
的规模远大于高分子集 ,二者得分的期望差值满足:
,二者得分的期望差值满足:
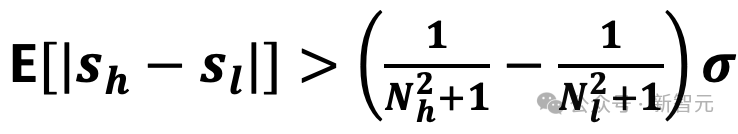
其中σ为实体得分的标准差。
在实际数据集(如FB15k-237)上,的比例可超过1000,因此两者的得分下界差值可达0.1σ以上,而传统单阶段推理的得分差距通常不足0.02σ这种显著的得分差距放大,使模型在最终决策时拥有更加清晰的判断边界,从而有效提高正确实体的命中率P:
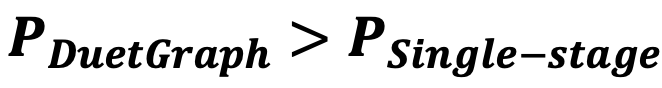
实验评估
在多个大规模知识图谱基准数据集上对DuetGraph进行了系统评估,涵盖Transductive与Inductive两类推理场景。
结果表明,DuetGraph取得了显著性能提升:
- 推理质量:在Transductive场景中,DuetGraph在Hits@K和MRR等指标上全面超越Baseline模型,充分彰显了其卓越的推理质量与精确性。
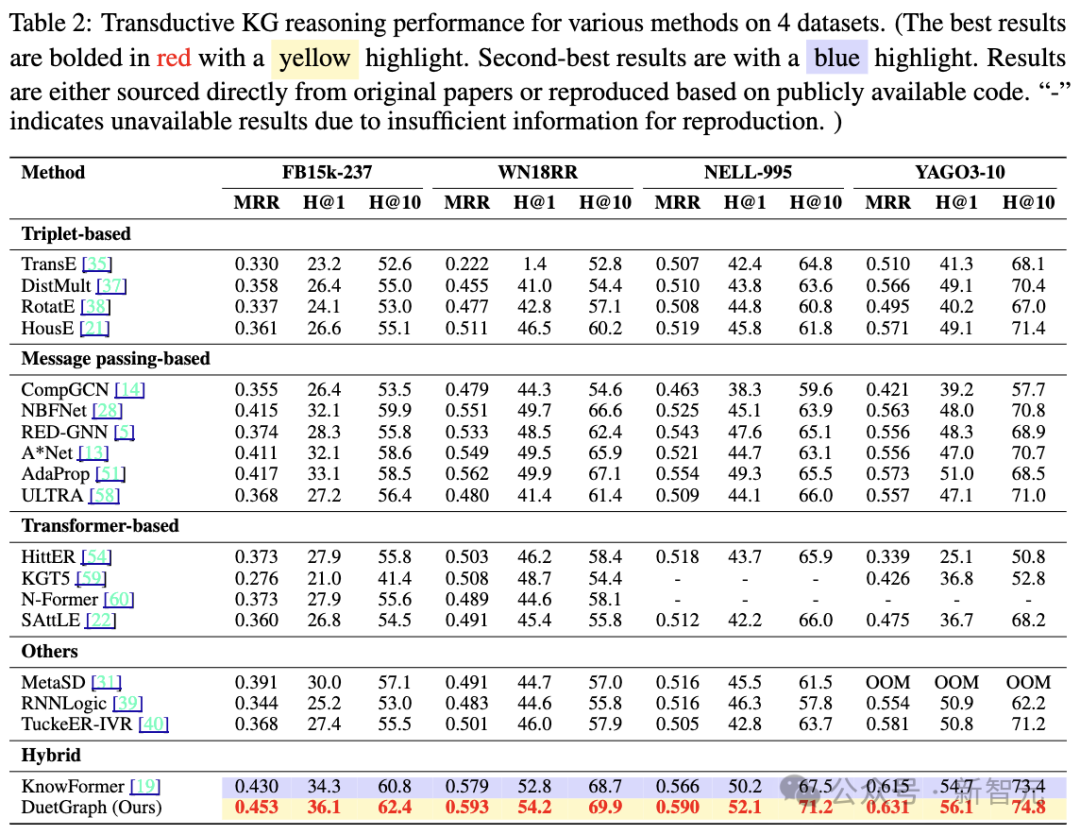
- 泛化能力:在更具挑战性的Inductive场景中,DuetGraph的表现进一步领先于其他Baseline方法,凸显了其在未见三元组上的强大泛化能力与稳健性。
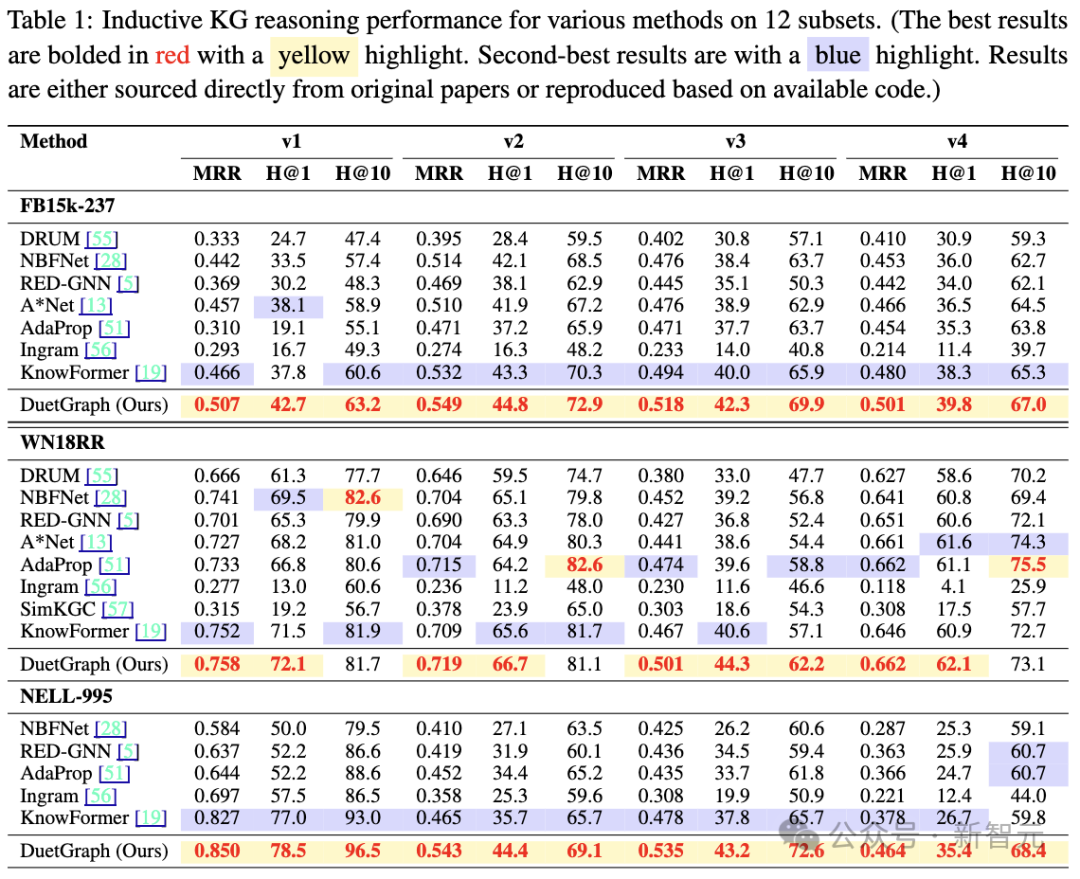
- 推理效率与可扩展性:无论是在训练阶段还是在超大规模知识图谱上的推理阶段,DuetGraph都表现出显著的时间优势,充分验证了其高效的推理能力和良好的大规模数据可扩展性。
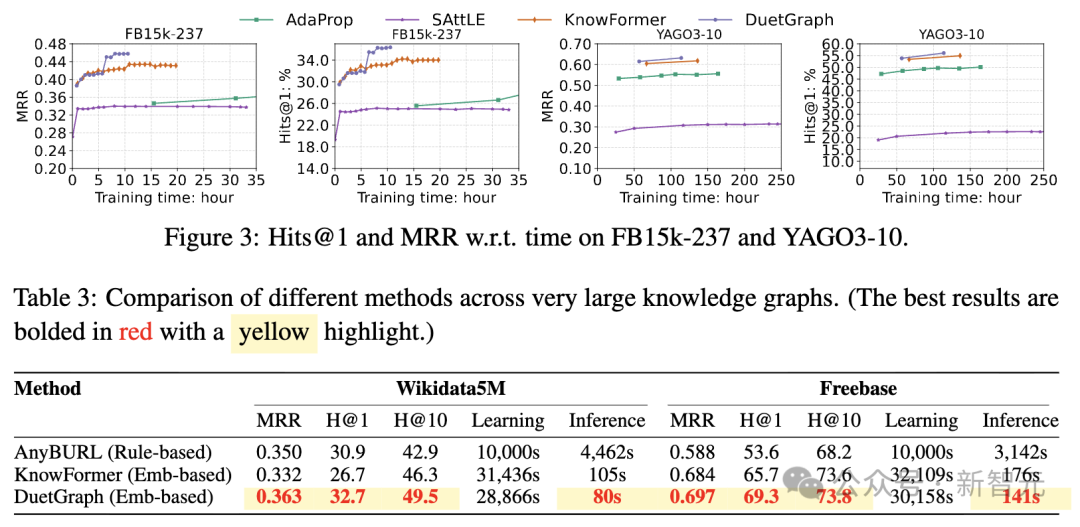
- 鲁棒性:当更换了不同的粗粒度模型后,DuetGraph依然能够保持SOTA的性能,充分体现了其出色的鲁棒性与稳定性。

- 通用性:DuetGraph不仅在知识图谱补全任务中表现优异,在三元组分类等其他知识图谱任务上同样展现出出色的性能,体现了其良好的任务适应性与广泛适用性。
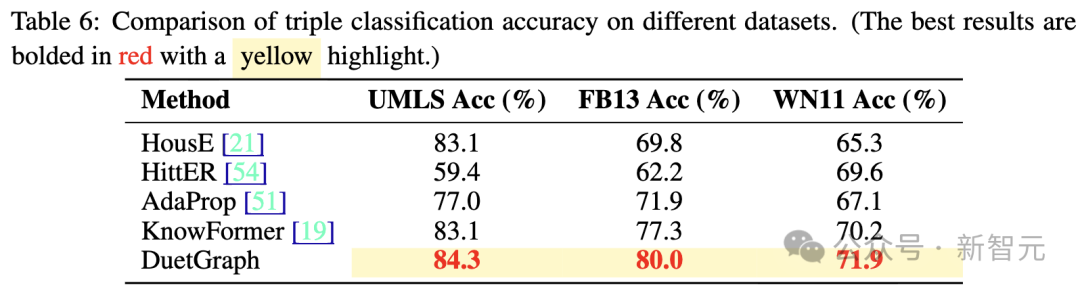
未来展望
灵活模型组合:DuetGraph框架支持在保持细粒度模型不变的前提下灵活更换粗粒度模型,从而适配不同的任务场景与应用需求。
与LLM融合:未来将探索将DuetGraph与大语言模型结合,提升结构化知识推理能力;
真实场景落地:在推荐、搜索、金融风控、问答等高复杂度推理任务中具有巨大潜力。


