正在进行的 2024 世界人工智能大会(WAIC 2024)期间,智谱 AI 发布并开源代码生成大模型 CodeGeeX 的第四代产品 CodeGeeX4-ALL-9B,集代码补全和生成、代码问答、代码解释器、工具调用、联网搜索、项目级代码问答等所有能力于一体,号称是目前百亿(10B)参数以下性能最强、最全能的代码大模型。
据介绍,该模型在 GLM4 的语言能力的基础上大幅增强了代码生成能力。CodeGeeX4-ALL-9B 单一模型,即可支持代码补全和生成、代码解释器、联网搜索、工具调用、仓库级长代码问答及生成等功能,覆盖编程开发的各种场景,支持 300 + 编程语言。
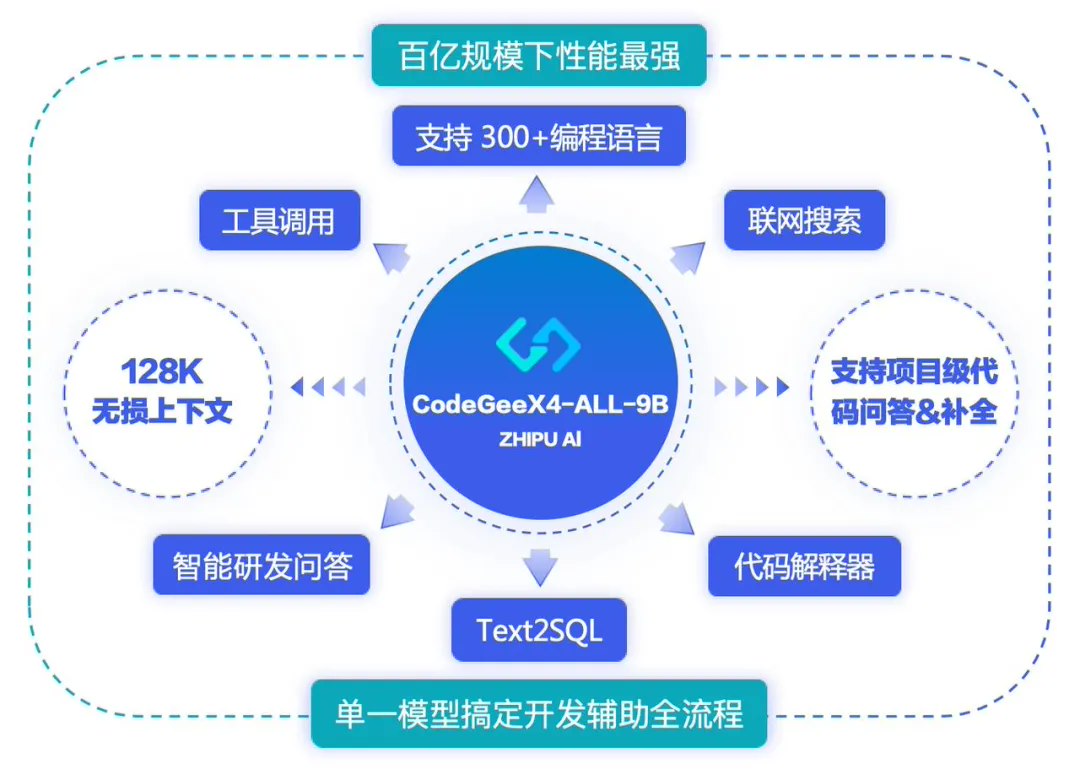
CodeGeeX4-ALL-9B 升级支持 128K 上下文,使其能够处理和利用更长代码文件,甚至是项目代码中的信息,有助于模型更深入理解复杂和细节丰富的代码。基于更长的上下文,CodeGeeX4-ALL-9B 可以处理更复杂的项目级任务,在输入显著变长的情况下,依然能准确回答不同代码文件中的内容,并对代码作出修改。
官方更称,CodeGeeX4-ALL-9B 是“目前唯一的”能实现 Function Call 的代码大模型。其在 Berkeley Function Calling Leaderboard 上进行了全面的测试,包括各种形式的函数调用、不同的函数调用场景以及函数调用可执行性的测试,在 AST 和 Exec 测试集中调用成功率超过 90%。
IT之家附开源相关链接:
GitHub:https://github.com/THUDM/CodeGeeX4
HuggingFace:https://huggingface.co/THUDM/codegeex4-all-9b
ModelScope:https://modelscope.cn/models/ZhipuAI/codegeex4-all-9b
WiseModel:https://wisemodel.cn/models/ZhipuAl/codegeex4-all-9b


