
大家好,我是肆〇柒。今天我们一起了解一项来自香港科技大学(HKUST)与蚂蚁集团(Ant Group)联合团队的创新研究——HoloCine。这项研究首次实现了分钟级、多镜头、高一致性的电影级视频整体生成,不仅在Transition Control指标上达到0.9837(远超现有方法),更展现出对镜头语言、角色记忆甚至电影术语的“理解”能力。它标志着AI视频生成正从“片段合成”迈向“自动拍片”的新阶段。
当前最先进的文本到视频(Text-to-Video, T2V)模型虽能生成高质量的5秒单镜头视频,却难以构建电影叙事的核心要素——连贯的多镜头序列。这一断层被研究者明确界定为"叙事鸿沟":现有技术擅长生成孤立片段,却无法创造连贯、多镜头的叙事,而后者正是讲故事的本质。HoloCine的突破性进展首次实现了分钟级、多镜头、高一致性的电影级视频整体生成,其Transition Control指标达到0.9837,远超次优方法的0.5370。这一技术不仅解决了长期困扰行业的连贯叙事难题,更标志着AI视频生成从"片段合成"迈向"导演场景"的范式转变,为自动化影视创作开辟了全新路径。

多镜头视频叙事示例
从上图可见,仅凭文本提示,HoloCine就能生成连贯的电影级多镜头视频叙事。图中展示了模型的多样性能力,包括原创场景(上三行)和对《泰坦尼克号》的电影致敬(下三行)。所有场景均展现出卓越的角色一致性和叙事连贯性,底部扩展行则展示了镜头内平滑的运动和质量。这一成果证明了模型在单一生成过程中实现多镜头叙事的可能性。
当前 T2V 模型的根本局限
电影、电视剧和纪录片并非单个长镜头的简单延续,而是由多个不同镜头通过剪辑组合而成的叙事结构。当前最先进的文本到视频模型虽能生成高质量的单镜头视频,却缺乏构建连贯多镜头叙事的能力。这一根本性断层构成了生成式AI在视觉媒体领域应用的关键瓶颈。
现有解决方案主要面临三重挑战。分段生成方法通过逐块生成长视频,不可避免地导致误差累积和视觉质量随长度下降;两阶段方法先创建关键帧再独立合成连接镜头,虽然能在关键帧层面保障一致性,但各镜头的视频填充仍孤立进行。

定量结果。最佳和亚军结果以加粗和下划线标出
如上表所示,Wan2.2单独模型的Inter-shot Consistency为0.6772,而StoryDiffusion与Wan2.2结合后提升至0.8487,但仍低于HoloCine的0.7509。这一数据差异揭示了关键问题:两阶段方法在镜头间一致性上存在固有局限,如下图中中Shot 4-5的人物特征变化所示。StoryDiffusion和IC-LoRA都生成了男孩和女人在一起的中景镜头,而非预期的特写。更严重的是,它们在Shot 4-5中角色特征明显漂移,证明了两阶段方法在长程一致性上的不足。

多镜头生成对比
上图直观展示了现有方法的局限。基础模型Wan2.2无法理解多镜头指令,仅生成静态单镜头;两阶段方法StoryDiffusion和IC-LoRA虽能生成不同图像,但在提示保真度和长程一致性上表现不佳。例如,提示要求Shot 2为"Medium close-up of woman's pensive expression",但这两个方法都生成了男孩和女人在一起的中景镜头。更关键的是,它们在Shot 4-5中角色特征明显漂移——同一角色的发型、服装和面部特征发生不一致变化。这些缺陷源于两阶段方法的本质:关键帧生成与视频填充分离进行,导致视觉属性随镜头数量增加而退化。
更根本的问题是"控制稀释"。大家可能会问:为什么不能简单地将多个镜头提示拼接起来让模型生成?答案是"控制稀释"问题——当使用全局提示指导多镜头生成时,针对特定镜头的指令在整体上下文中被稀释,难以实现精确的镜头内容控制与转场。
整体生成范式为解决这些问题提供了新思路。以LCT为例,这种方法将整个多镜头序列在一个统一的扩散过程中联合建模,天然保障了全局一致性。然而,这一方向面临两大挑战:如何实现精确的导演控制,以及如何克服自注意力机制带来的计算瓶颈——其复杂度随序列长度呈平方级增长,使分钟级视频生成变得不切实际。HoloCine通过两项创新性架构设计,成功解锁了整体生成范式的潜力。
HoloCine 的核心突破:整体生成 × 精准控制 × 高效计算
HoloCine通过三大技术支柱,构建了完整的多镜头叙事生成框架:整体生成基础、精准导演控制和高效计算机制。这三大要素协同工作,使分钟级多镜头视频的整体生成成为可能。
在整体生成框架中,所有镜头的潜在表示在扩散模型中同步处理。通过共享的自注意力机制,模型自然维持长程一致性,确保角色身份、背景细节和整体风格在镜头边界处保持连贯。这一框架建立在强大的14B参数wan2.2模型基础上,为分钟级视频生成提供了坚实基础。
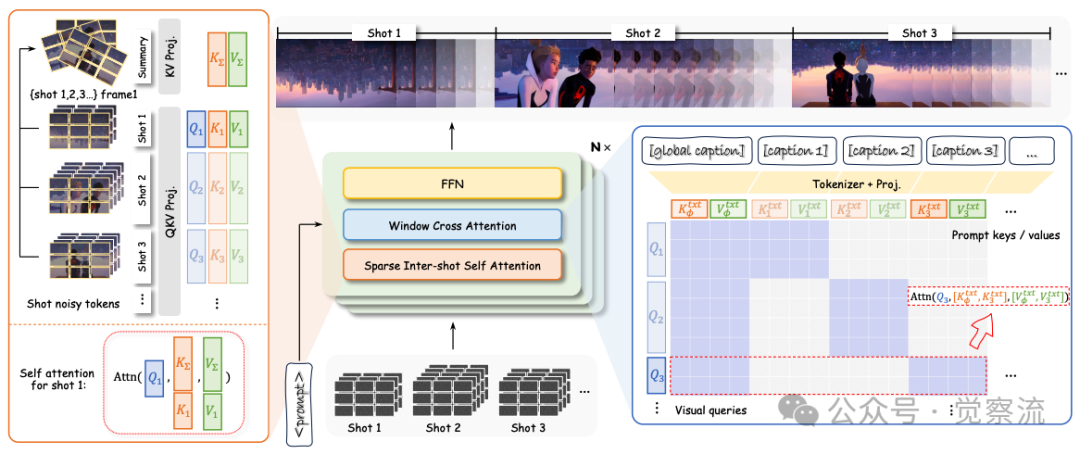
整体架构设计
上图展示了HoloCine的整体架构。左侧是分层提示处理流程:全局提示与各镜头提示被拼接,通过[shot cut] token明确界定边界;中间是核心的注意力机制:Window Cross-Attention确保每镜头仅关注相关提示,Sparse Inter-Shot Self-Attention实现高效的镜头间通信;右侧是视频生成结果,展示了平滑的镜头过渡和一致的角色表现。这一设计的关键在于将文本提示结构与视频生成过程对齐,使模型能理解"镜头1:中景,镜头2:特写"等指令的精确含义。
HoloCine通过一种创新的稀疏注意力模式,将计算复杂度从O(L²)降低到近线性,使分钟级视频的整体生成成为可能。这种模式的核心思想是:镜头内需要密集连接保证动作流畅,镜头间则可通过稀疏摘要实现高效通信。

整体架构设计

HoloCine的数据构建是实现整体生成的关键基础。如上图所示,通过将镜头边界检测、严格过滤和分层标注相结合,HoloCine构建了40万样本的多镜头数据集,其中[shot cut] token的引入使模型能够明确识别镜头边界,这是实现精确镜头切换的基础。上图展示了完整的数据处理流程:首先使用镜头边界检测算法分割影视内容;然后严格过滤掉含字幕、过短、过暗或美学评分低的片段;接着按5s/15s/60s目标时长聚合连续镜头,形成多样化样本;最后通过Gemini 2.5 Flash进行分层标注。这种分层标注结构包含三个关键元素:全局提示描述整体场景(角色、环境、剧情);各镜头提示详述具体动作、摄像机运动;[shot cut] token明确界定镜头边界。这一设计使模型既能理解全局叙事,又能执行精确的镜头级控制。
实证效果:不只是"看起来不错"
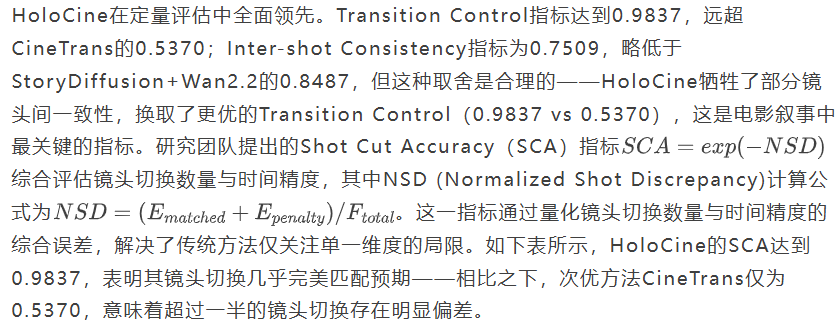

定量评估结果对比
上表全面展示了HoloCine与其他方法的性能对比。在Transition Control指标上,HoloCine达到0.9837,远超CineTrans的0.5370和StoryDiffusion的0.7364,表明其在镜头切换控制上的显著优势。Inter-shot Consistency指标为0.7509,略低于StoryDiffusion+Wan2.2的0.8487,但高于Wan2.2单独模型的0.6772。值得注意的是,虽然StoryDiffusion在Aesthetic Quality上略胜一筹(0.5773 vs 0.5598),但这恰恰反映了HoloCine的取舍——牺牲微小的美学质量换取叙事连贯性,而这正是电影叙事的核心需求。
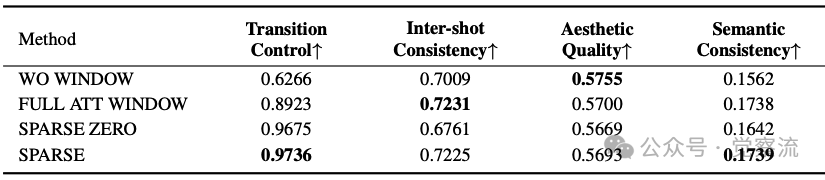
消融实验结果
上表的消融实验提供了关键点。完全移除Window Cross-Attention(WO WINDOW)导致Transition Control从0.9736降至0.6266,证明了该机制对镜头控制的必要性。这一下降意味着镜头切换的准确性从"几乎完美"降至"严重错误"——在10次镜头切换中,有近4次无法正确执行,导致叙事断裂。使用全自注意力(FULL ATT WINDOW)虽能达到0.8923的Transition Control,但计算成本过高;而稀疏注意力(SPARSE)在Transition Control上仅轻微下降(0.9736 vs 0.8923),却大幅提升了效率。特别值得注意的是,移除跨镜头摘要token(SPARSE ZERO)导致Inter-shot Consistency从0.7225降至0.6761,证明了这一机制对维持角色一致性的关键作用。

消融实验定性结果
上图的消融实验揭示了各组件的关键作用。移除Window Cross-Attention(第一行)导致模型无法执行镜头切换,忽略新内容提示(如Shot 3的特写),并锁定在初始场景中。这一结果证明了Window Cross-Attention对实现精确镜头控制的必要性。使用全自注意力(第二行)虽能生成高质量视频,但计算成本过高;而稀疏注意力(第四行)在美学质量上仅轻微下降(0.5693 vs 0.5700),却大幅提升了可扩展性。最严重的是移除跨镜头摘要token(第三行),导致角色一致性完全崩溃——老人的身份和外观在不同镜头间发生剧烈变化,这一结果证明了Sparse Inter-Shot Self-Attention中摘要token的关键作用——它们作为镜头间的"记忆桥梁",使模型能够在不同镜头间保持角色一致性。没有这些桥梁,每个镜头就像孤立的岛屿,无法形成连贯叙事。

商业模型对比
上图定性对比直观展示了HoloCine的技术优势。基础模型Wan2.2无法理解多镜头指令,仅生成静态单镜头;两阶段方法StoryDiffusion和IC-LoRA虽能生成不同图像,但在提示保真度和长程一致性上表现不佳。例如,提示要求Shot 2为"Medium close-up of woman's pensive expression",但这两个方法都生成了男孩和女人在一起的中景镜头。它们在Shot 4-5中角色特征明显漂移的问题尤为突出。CineTrans虽尝试整体生成,却无法正确执行复杂镜头转换,画面质量显著下降。相比之下,HoloCine成功解析分层提示,生成五个不同镜头的连贯序列,每个镜头都精确匹配相应文本描述,同时在整个视频中保持高角色和风格一致性。
更值得注意的是与商业模型的对比:Vidu和Kling 2.5 Turbo完全无法解析多镜头指令,仅生成单镜头视频;而HoloCine与Sora 2表现相当,均能准确执行"从中景到特写"的镜头转换,这是开源模型首次在叙事能力上媲美顶级闭源方案。上图清晰展示了这一差异:HoloCine成功执行了从人物中景到面部特写的镜头转换,同时保持角色一致性,而商业模型则无法理解这一指令。
在训练细节上,HoloCine在128块NVIDIA H800 GPU上训练10k步(学习率1×10⁻⁵),采用混合并行策略:使用Fully Sharded Data Parallelism(FSDP)分片模型参数,结合Context Parallelism(CP)分割长序列。该模型支持5秒、15秒和60秒不同长度的视频生成,最多包含13个镜头,为实际应用提供了灵活选择。
超越生成:涌现能力揭示模型"理解"叙事
HoloCine展现出令人惊讶的涌现能力,表明模型不仅学习了表面视觉转换,还构建了对场景和对象的隐式持久表征。

模型持久记忆能力
上图揭示了HoloCine令人惊讶的持久记忆能力。在角色身份跨视角一致性方面(a),艺术家的金发、灰色T恤和围裙在不同角度和表情的镜头中保持高度一致;在长程重现能力上(b),教授在Shot 1引入后,经Shot 2(图书馆环境)干扰,Shot 5中仍能准确重现,证明模型具有超越相邻镜头的记忆能力;最引人注目的是细粒度细节记忆能力(c),背景中的蓝色磁铁(非显著元素)在Shot 1和Shot 5中位置完全一致,表明模型具备对场景的全面理解。这些能力并非显式编程,而是从数据中自然涌现的。这一细粒度记忆能力表明模型不仅关注主要角色,还构建了对场景的完整理解,这是实现真实电影叙事的关键——在专业电影制作中,道具的连续性是保证叙事可信度的基本要求。
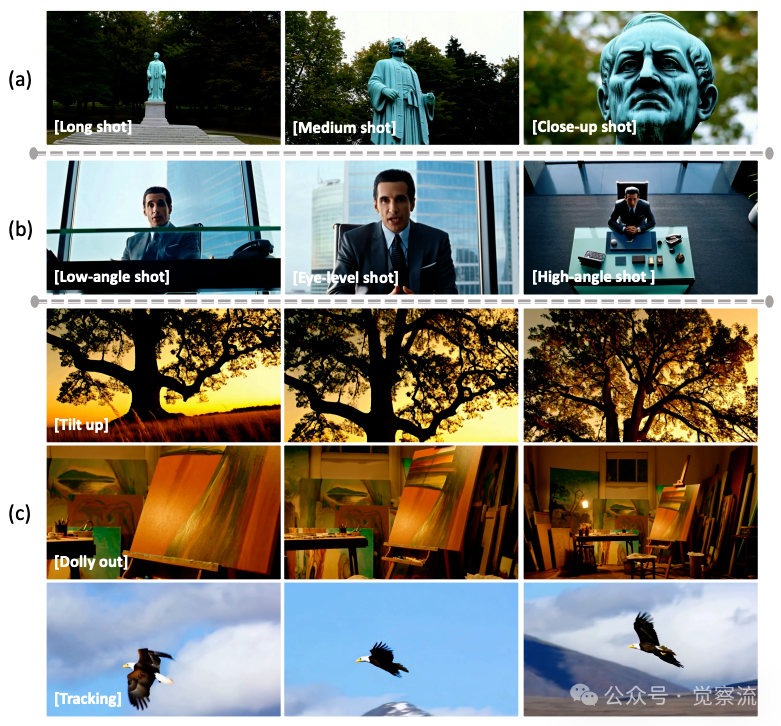
电影语言控制能力
上图展示了HoloCine对电影语言的精确控制。在镜头尺度控制方面(a),模型能准确生成Long/Medium/Close-up镜头,符合电影工业定义;对于摄像机角度(b),模型能精确响应Low-angle/Eye-level/High-angle指令;对于摄像机运动(c),模型执行Tilt up(向上倾斜)时,生成了从树根到树冠的平滑垂直运动,准确捕捉了这一电影术语的含义;Dolly out(后拉)则使相机向后移动,逐步揭示艺术家工作室的全貌;Tracking则正确跟随主体移动,保持鹰在画面中心。这一对专业电影语言的理解表明,HoloCine已发展出对电影语言的隐式理解,能够将文本指令转化为符合电影规范的视觉表达。
局限与启示
尽管HoloCine在视觉一致性方面表现出色,但在因果推理能力上仍有明显局限。

因果推理失败案例
上图揭示了HoloCine的深层局限。面对"空杯→倒水→结果"的场景序列,模型无法理解动作的物理后果:Shot 1显示空杯,Shot 2展示倒水动作,但Shot 3仍渲染为空杯状态。这一失败表明模型优先考虑与初始镜头的视觉一致性,而非动作的逻辑结果。这一局限源于HoloCine的训练目标——它被优化为保持视觉一致性,而非物理逻辑。在训练数据中,镜头间可能存在视觉相似但物理状态不同的场景,模型学习到的是"保持初始状态"而非"执行物理变化"。对于希望将HoloCine应用于需要物理常识的场景(如产品演示、教育视频)的开发者,需要额外添加因果推理模块,或在提示中明确指定结果状态。这一局限意味着HoloCine难以生成需要物理连贯性的场景,如"倒水→水杯变满"或"推门→门打开"等因果序列。在实际应用中,创作者需特别注意避免这类需要物理推理的叙事场景。
这一局限为未来研究指明了方向:需要将物理常识与视觉一致性相结合,推动模型从感知一致性向逻辑因果推理演进。同时,HoloCine提出的稀疏注意力模式为长视频生成提供了新思路,其分层提示结构也证明是实现精准导演控制的关键要素。
范式跃迁的意义
HoloCine不仅弥合了"叙事鸿沟",更标志着从"片段合成"到"导演场景"的范式转变。通过整体生成框架,模型能够理解并执行电影叙事语言。对工业界而言,这一技术为自动化短视频制作、影视预演和游戏过场提供了新工具;对学术界而言,"整体生成+结构稀疏注意力"的架构范式为解决长视频生成的计算瓶颈提供了新思路。
HoloCine代表了通向自动化电影制作的关键一步,使端到端电影生成成为一个切实可行的未来。这一进展不仅推动了技术边界,更重新定义了AI在创意产业中的角色——从工具到协作者,最终可能成为真正的"数字导演"。


