一上手就令网友直呼「生图能力」比GPT-4o更强?!
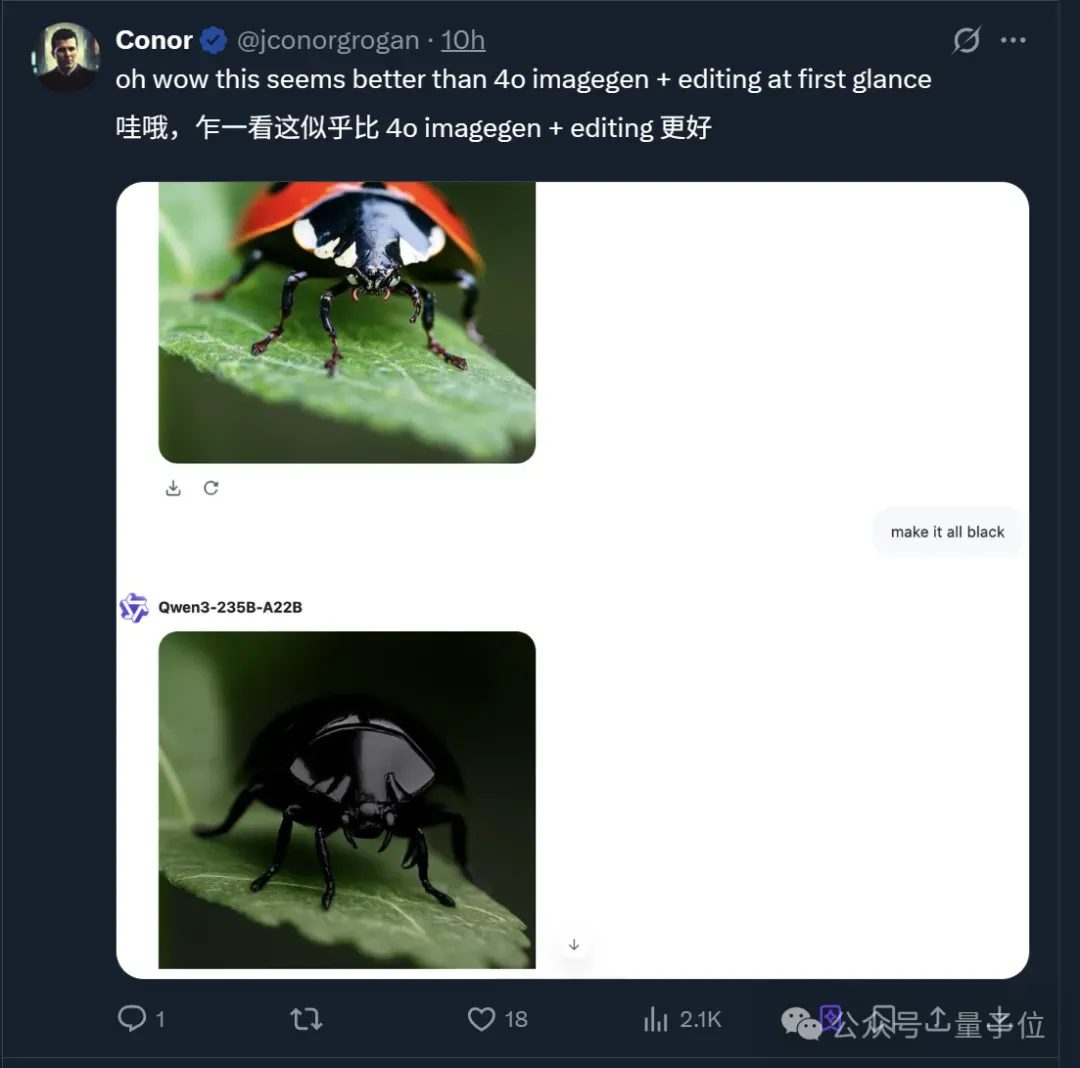
就在昨夜,阿里带着全新多模态模型Qwen-VLo开启炸场模式。
据介绍,Qwen-VLo在阿里原有的多模态理解和生成能力上进行了全面升级,具备三大亮点:
- 具有增强的细节捕捉能力,能在整个生成过程中保持高度语义一致性;
- 一个指令即可实现图像编辑,包括风格替换、素材增删、添加文字等等;
- 支持中英等多语言,全球用户使用更方便。
而且无论是输入端还是输出端,Qwen-VLo都支持任意分辨率和长宽比,不受固定格式的限制。
同时在官方释出的demo中,除了那些GPT-4o已经有的玩法(如连续生成、吉卜力风格、添加文字),它还支持一些脑洞大开的idea。
前者无需多言,它现在也能像“连续剧”一样生成各种精准符合指令的图片:

至于后者,比如我们像在超市选购日用品一样,让Qwen-VLo生成一张“洗浴用品都在购物篮里”的图片。
结果啪的一下,还真立马完成装货了(⊙ˍ⊙):

不是没有一些小瑕疵,但有一说一,其“理解”能力确实比之前更强。
官方介绍,这种理解能力不止体现在图像生成上,还包括对图像的识别解释。
比如完成生图任务后,再让它介绍一下图中小猫小狗的品种(正确识别为虎斑猫和比格):

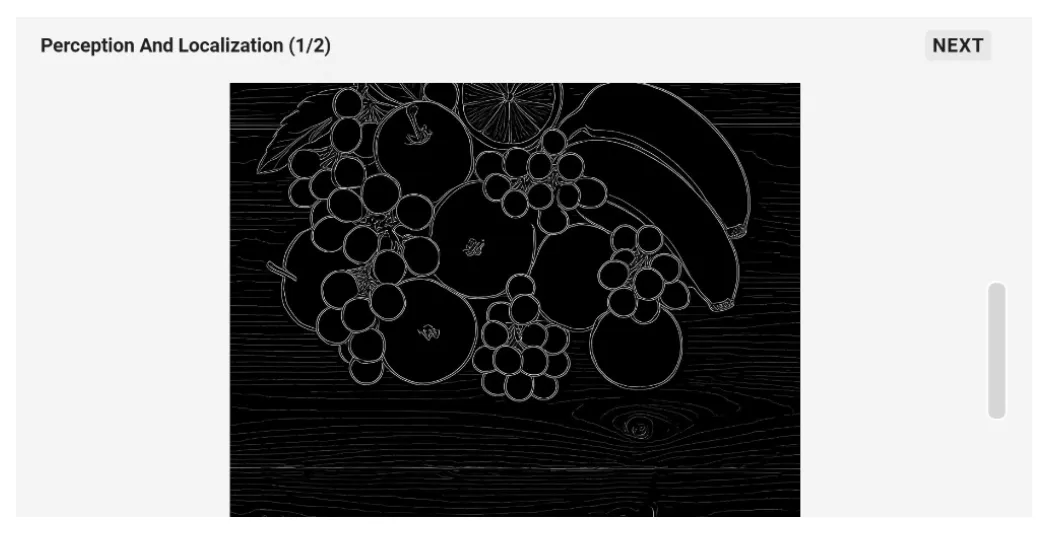
而且和以往模型稍显不同的是,Qwen-VLo还可以对现有信息进行注释(如检测、分割等)。
下图中,它成功用红色Mask分割出了香蕉的边缘。
……
目前模型人人免费可玩(当前为预览版),具体请认准Qwen3-235B-A22B,直接在首页输入框提需求就行。
话不多说,我们先一起来上手实测一波走起。
Qwen-VLo,你到底有多能编辑?
根据Qwen介绍的亮点,即“强细节捕捉”和“一句话编辑图像”,我们着重在测试中考查了Qwen-VLo的各种编辑能力。
毕竟这点真的很吸引人啊!
一方面几乎所有的模型生图都需要抽卡,但前一次的生成效果并非让人完全不满意,所以二次/多次编辑能力非常重要。
另一方面,强编辑能力,真的给P图废材省不少事儿……
开胃小菜先走起!
第一测,让它先生成一张北极熊喝可乐的照片。
这一回合主打的是非现实风格。
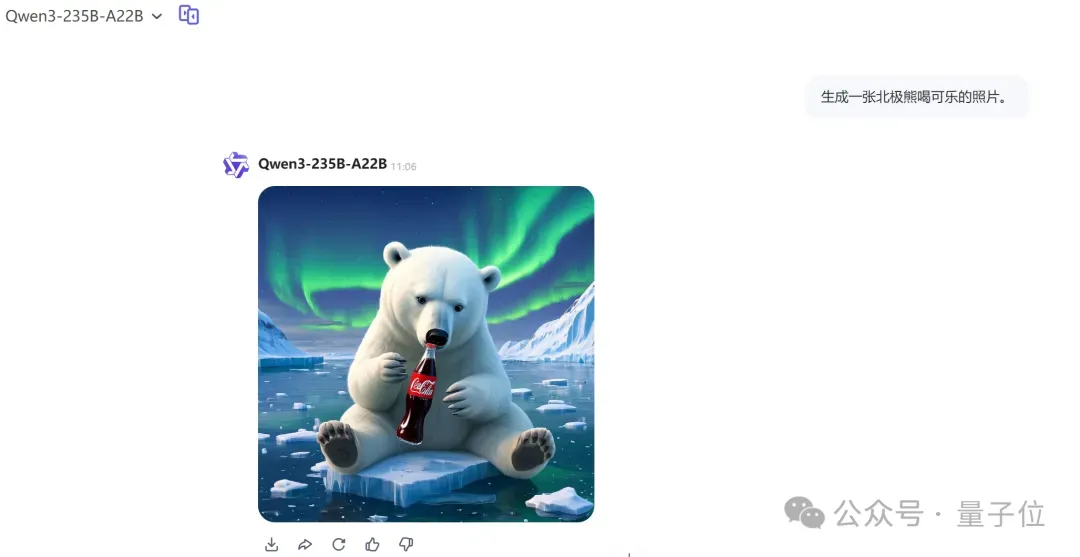
在此基础上,继续通过对话将可乐换成牛奶。

一次成功,Qwen-VLo确实完成了替换。
且背景、北极熊本熊都几乎没被乱改。
但非要挑挑毛病的话,还是能观察出来,前后两张图中北极熊的眉眼部分和毛发质感稍微有那么一丁点不一样。
第二测,先让它帮忙生成一张小鸟的照片。
这一回合主打的是现实摄影风格。
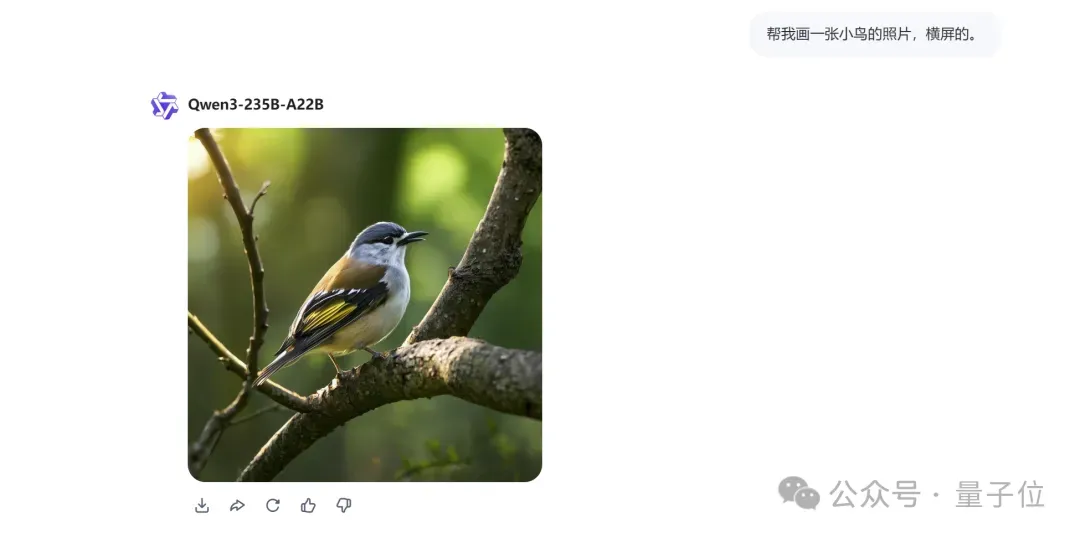
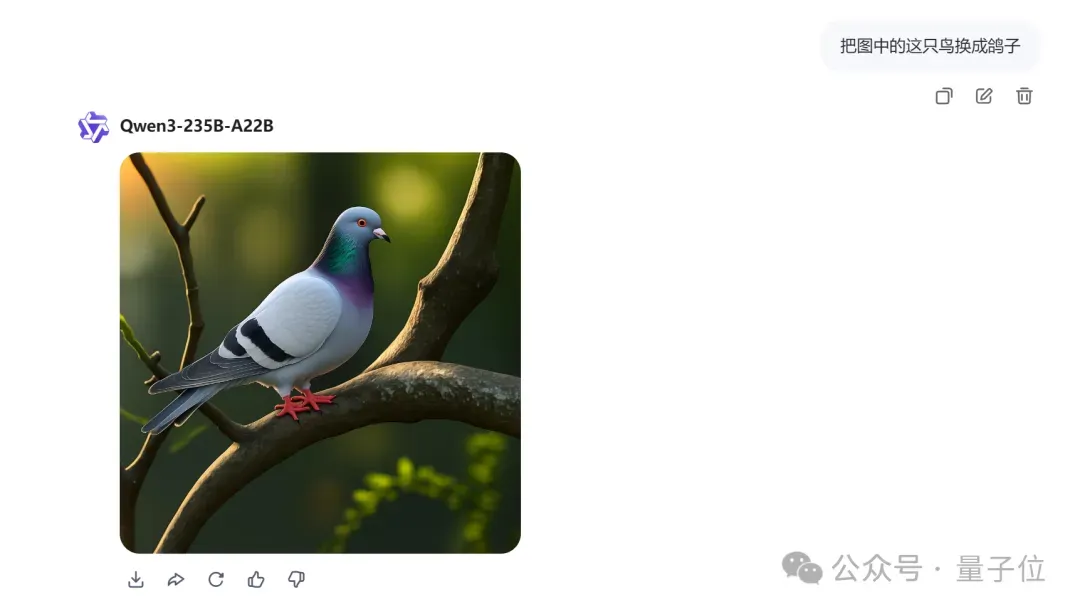
然后不用读霍格沃茨,只需一句“把图中的这只鸟换成鸽子”,你就能施展魔法:
但我们尝试玩儿个“蒜鸟”的梗,Qwen-VLo就没get到。
(注:“蒜鸟”一词是近期爆梗。短视频画外音中的武汉方言“算了算了,都不容易”,被网友谐音称“算鸟”,后来演变成“蒜鸟”)
不过,虽然没get到梗,Qwen-VLo还是努力想完成编辑任务。
看下图成果,在不改变其它元素的基础上,Qwen-VLo给咱们把图中的鸽子换成了别的鸟。

也算是一种换鸟了?

第三测,来个多步骤任务,全方位测试Qwen-VLo“描绘”世界的同时,重点考察下它在图像上的文本编辑能力。
过程是「让Qwen-VLo生成草图——上色——加字——编辑汉字」。
来,怕动图滑太快,咱们连看过程中顺次截取的四张图,感受它每一步带来的改变:


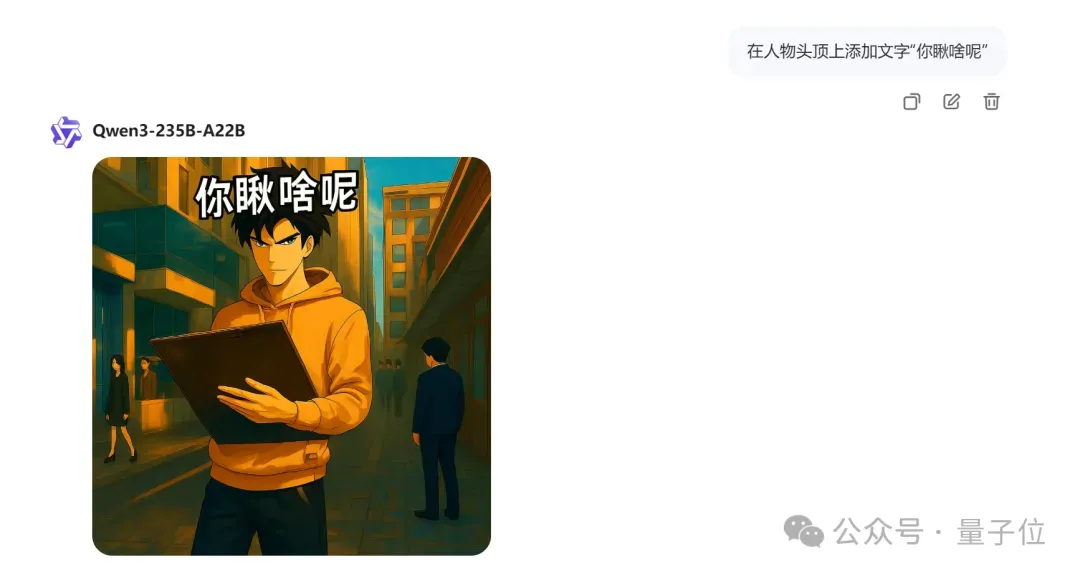
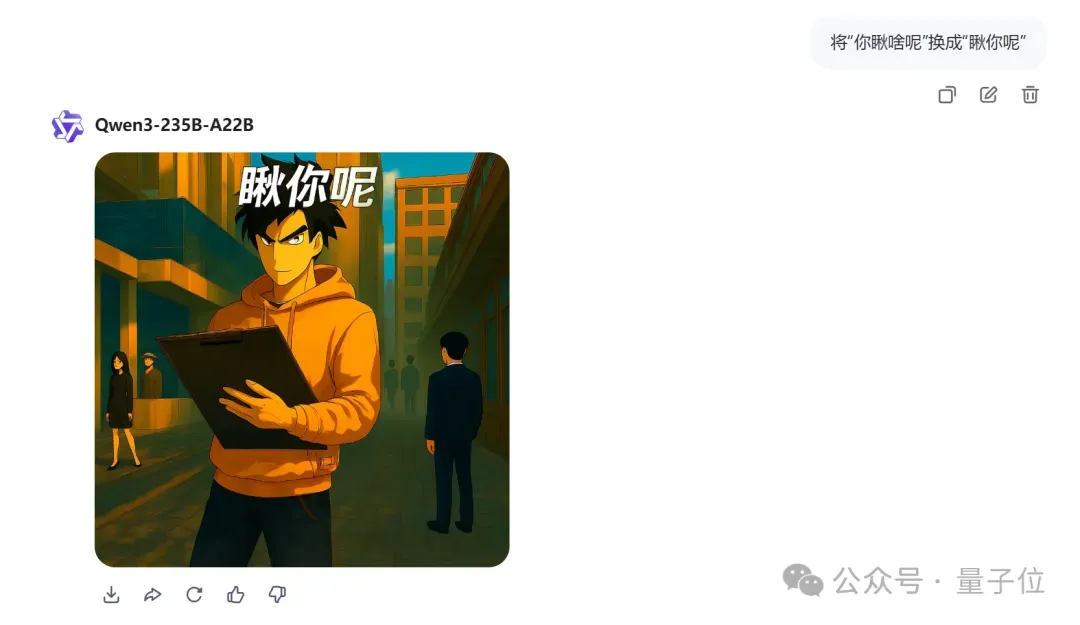
虽然图里小帅同学的五官在变,但人物主体稳定,背景没变,一整套下来,编辑汉字的任务算是搞得不错,
最后来个附加题,编辑英文——
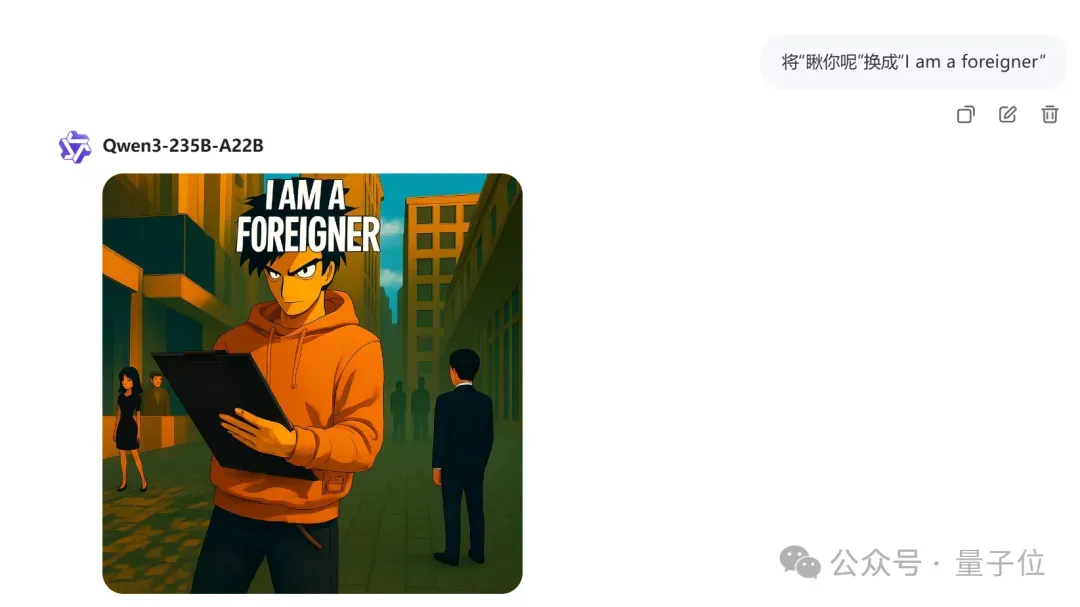
字编辑对了,多人物主体位置没变,背景依旧,总体没错。
但如你所见,小帅同学也长得比较美漫风了(手动笑死)。
同样是逐步展示,但Qwen-VLo这背后真有活
这里我们展开补充一点,大家上手玩儿的时候应该都能注意到。
那就是Qwen-VLo生成图像的过程,是酱婶儿的——

是不是有点熟悉的味道?
没错,GPT-4o也是从上到下逐块生成图像的:先显示模糊轮廓,再逐步填充细节。
不过当时港中文研究逆向工程研究发现,用户看到的逐行渲染效果只是OpenAI的障眼法,不是真的由上至下逐像素生成。
这样做的目的,既满足用户对“实时生成”的心理预期,又避免了真正逐行渲染的技术负担。
但Qwen这么做就不是上演OpenAI的戏码了。
敲敲黑板——
首先,Qwen官方表示Qwen-VLo的这种渐进式生成方式,不仅是从上到下,还是从左至右逐步清晰地构建整幅图片。
我们多次实测,暂时没有肉眼观察到“从左至右”的前端效果。
但从上到下逐渐构成照片的前端效果是保准会有的:

其次,Qwen引入这个形式,它是真·有用啊:
在生成过程中,模型会对预测的内容不断调整和优化,从而确保最终结果更加和谐一致。
这种生成机制不仅提升了视觉效果,生成效率,还特别适用于需要精细控制的长段落文字生成任务。
例如,在生成带有大量文本的广告设计或漫画分镜时,Qwen-VLo会逐步生成,慢慢修改。
这个生成过程,其实有点思维链“一步一步慢慢想”具像化的意思了!
网友实测脑洞开很大,来吧展示
除了以上量子位实测,诸多网友也火速贡献了一波有趣玩法…
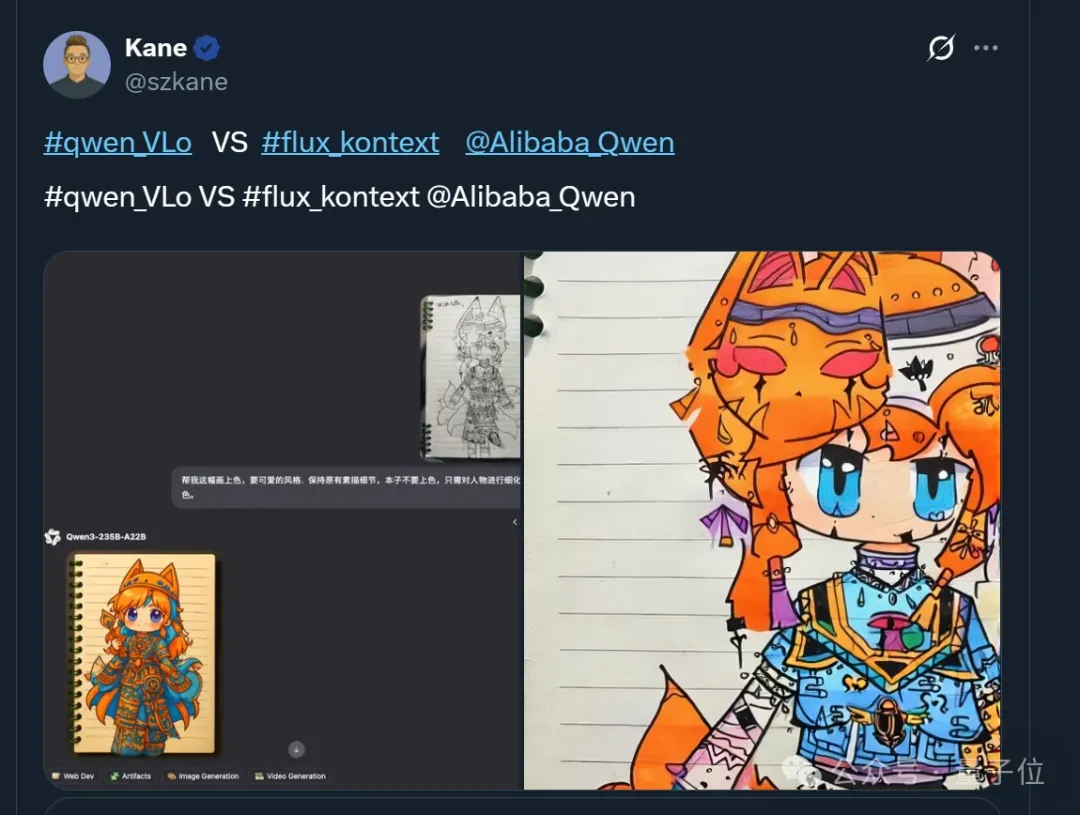
随手一张动漫角色草图, Qwen-VLo便能帮忙一键上色。
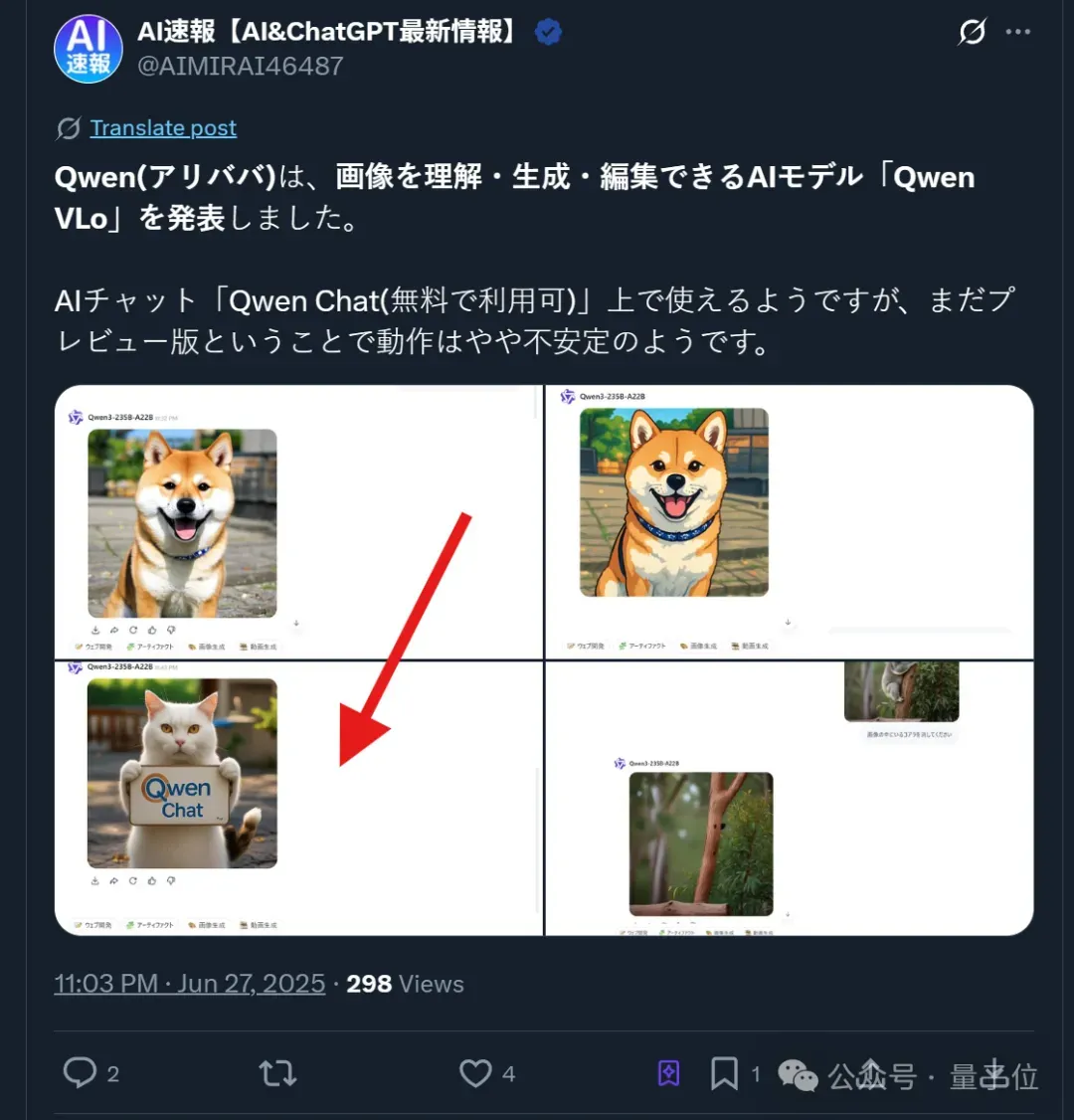
让小猫担任宣传员,还能直接生成带有“Qwen Chat”字样的看板。
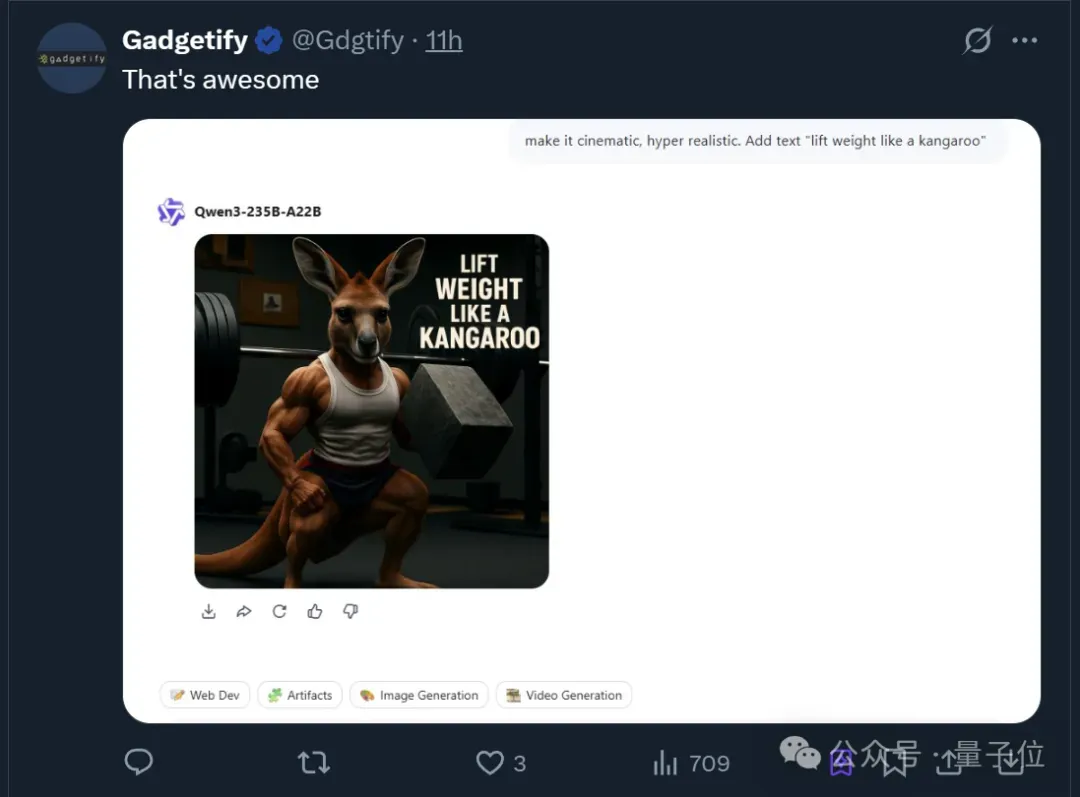
或者也可以借鉴下面网友的做法,以后用来制作一些梗图(doge)。
顺便一提,连Qwen团队成员之一Binyuan Hui也出来给大家打样,分享了吉卜力风格的某近日顶流。
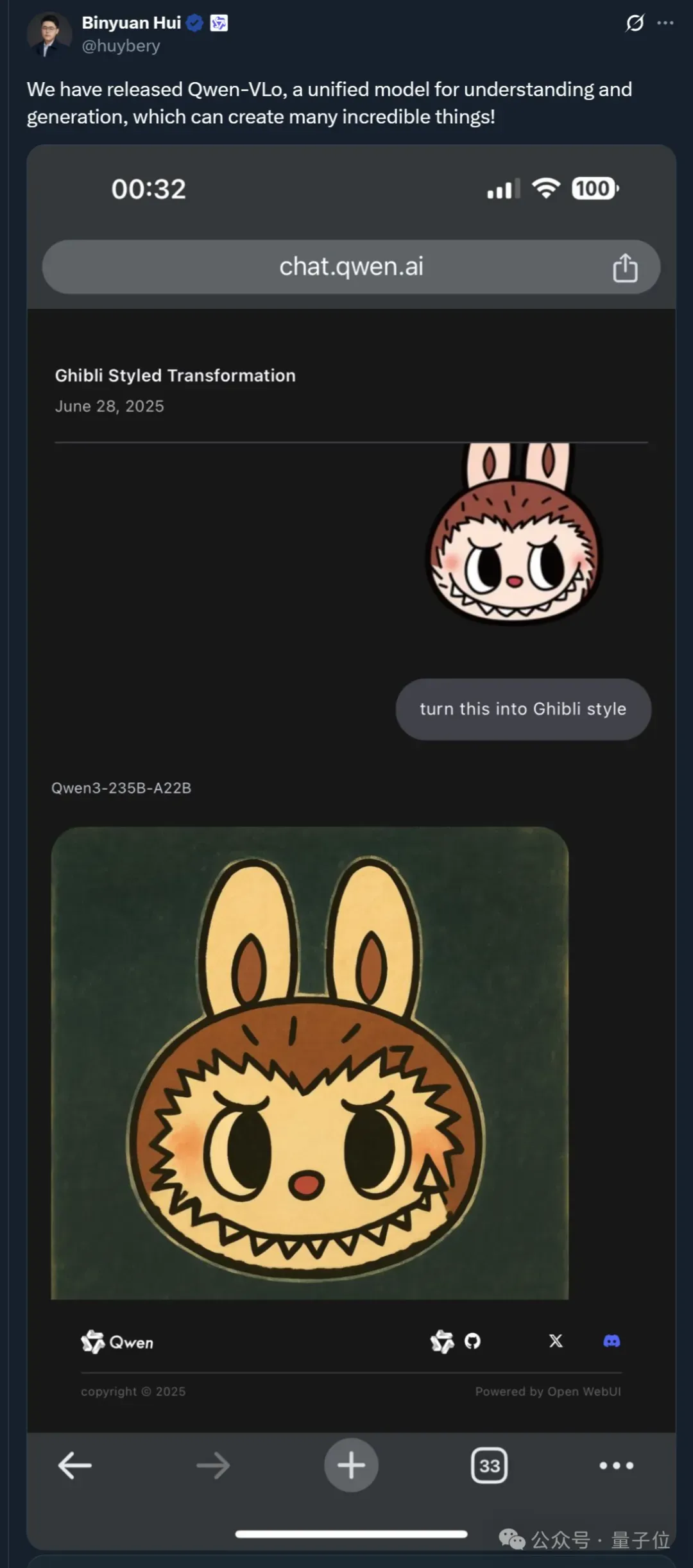
好了,更多例子就不一一展示了,只说一句:
目前模型免费开放,评论区可带图,记得回来分享一波~
在线体验:https://chat.qwen.ai/博客:https://qwenlm.github.io/blog/Qwen-VLoo/


