还记得去年 11 月底爆出来的 Q* 项目吗?这是传说中 OpenAI 正在秘密开展、或将带来颠覆性变革的 AI 项目。如果你想回忆一下,可参看机器之心当时的报道《全网大讨论:引爆 OpenAI 全员乱斗的 Q * 到底是什么?》简而言之,Q* 很可能是 Q 强化学习和 A* 搜索这两种 AI 方法的结合。
近日,斯坦福大学一个团队的一项新研究似乎为这一研究方向的潜力提供了佐证,其声称现在已经取得非凡成就的「语言模型不是一个奖励函数,而是一个 Q 函数!」由此发散思维猜想一下,也许 OpenAI 秘密的 Q* 项目或许真的是造就 AGI 的正确方向(或之一)。

论文标题:From r to Q∗: Your Language Model is Secretly a Q-Function
论文地址:https://arxiv.org/pdf/2404.12358.pdf
在对齐大型语言模型(LLM)与人类意图方面,最常用的方法必然是根据人类反馈的强化学习(RLHF)。通过学习基于人类标注的比较的奖励函数,RLHF 能够捕获实践中难以描述的复杂目标。研究者们也在不断探索使用强化学习技术来开发训练和采样模型的新算法。尤其是直接对齐方案(比如直接偏好优化,即 DPO)凭借其简洁性收获了不少拥趸。
直接对齐方法的操作不是学习奖励函数然后使用强化学习,而是在上下文多臂赌博机设置(bandit setting)中使用奖励函数与策略之间的关系来同时优化这两者。类似的思想已经被用在了视觉 - 语言模型和图像生成模型中。
尽管有人说这样的直接对齐方法与使用 PPO 等策略梯度算法的经典 RLHF 方法一样,但它们之间还是存在根本性差异。
举个例子,经典 RLHF 方法是使用终点状态下的稀疏奖励来优化 token 层面的价值函数。另一方面,DPO 则仅在上下文多臂赌博机设置中执行操作,其是将整个响应当成单条臂处理。这是因为,虽然事实上 token 是一次性只生成一个,但研究强化学习的人都知道,密集型奖励是有益的。
尽管直接对齐算法颇引人注意,但目前人们还不清楚它们能否像经典强化学习算法那样用于序列。
为了搞清楚这一点,斯坦福这个团队近日开展了一项研究:在大型语言模型中 token 层面的 MDP 设置中,使用二元偏好反馈的常见形式推导了 DPO。
他们的研究表明,DPO 训练会隐含地学习到一个 token 层面的奖励函数,其中语言模型 logit 定义最优 Q 函数或预期的总未来奖励。然后,他们进一步表明 DPO 有能力在 token MDP 内灵活地建模任意可能的密集奖励函数。
这是什么意思呢?
简单来说,该团队表明可以将 LLM 表示成 Q 函数并且研究表明 DPO 可以将其与隐式的人类奖励对齐(根据贝尔曼方程),即在轨迹上的 DPO 损失。
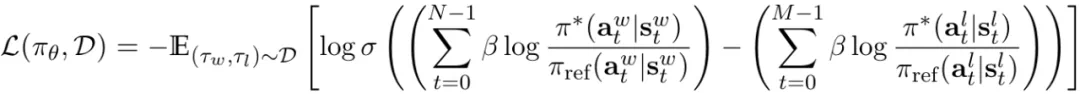
并且他们证明这种表示可以拟合任何在轨迹上的反馈奖励,包括稀疏信号(如智能体应用)。
实验
他们也进行了实验,论证了三个可能对 AI 社区有用的实用见解。
第一,他们的研究表明尽管 DPO 是作为上下文多臂赌博机而派生出来的,但 DPO 模型的隐含奖励可在每个 token 层面上进行解释。
在实验中,他们以定性方式评估了 DPO 训练的模型是否能够根据轨迹反馈学习 credit assignment。有一个代表性示例是商讨工作就职的场景,图 1 给出了两个答案。

其中左边是正确的基础摘要,右边是经过修改的版本 —— 有更高层的职位和相应更高的工资。他们计算了这两个答案的每个 token 的 DPO 等价的奖励。图 1 中的每个 token 标注的颜色就正比于该奖励。
可以看到,模型能够成功识别对应于错误陈述的 token,同时其它 token 的值依然相差不大,这表明模型可以执行 credit assignment。
此外,还可以看到在第一个错误(250K 工资)的上下文中,模型依然为其余 token 分配了合理的值,并识别出了第二个错误(management position)。这也许表明模型具备「缝合(stitching)」能力,即根据离线数据进行组合泛化的能力。该团队表示,如果事实如此,那么这一发现将有助于强化学习和 RLHF 在 LLM 中的应用。
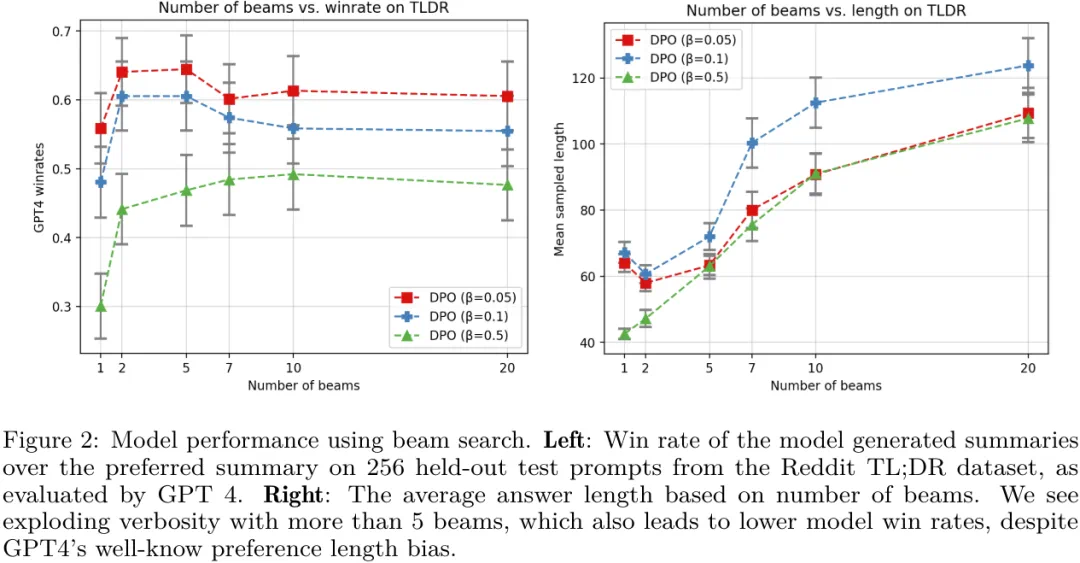
第二,研究表明对 DPO 模型进行似然搜索类似于现在很多研究中在解码期间搜索奖励函数。也就是说,他们证明在 token 层面的阐述方式下,经典的基于搜索的算法(比如 MCTS)等价于在 DPO 策略上的基于似然的搜索。他们的实验表明,一种简单的波束搜索能为基础 DPO 策略带来有意义的提升,见图 2。
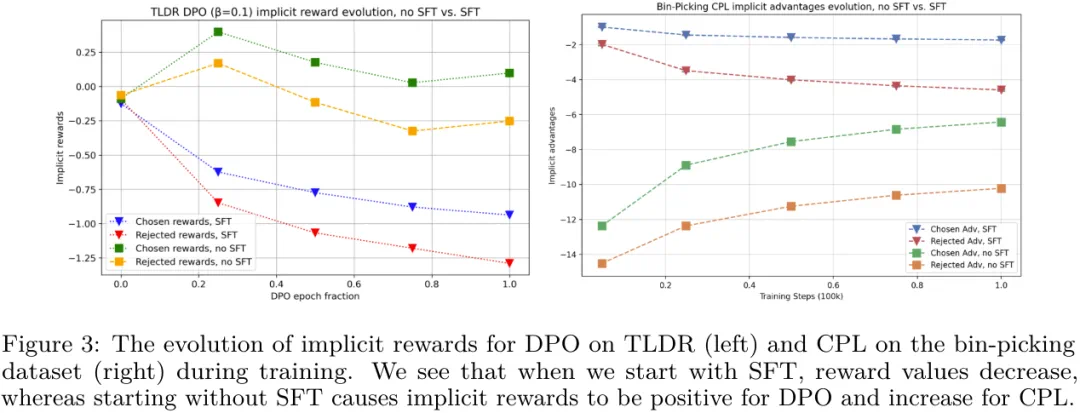
第三,他们确定初始策略和参考分布的选择对于确定训练期间隐性奖励的轨迹非常重要。
从图 3 可以看出,当在 DPO 之前执行 SFT 时,被选取和被拒绝的响应的隐含奖励都会下降,但它们的差距会变大。
当然,该团队最后也表示,这些研究结果还需要更大规模的实验加以检验,他们也给出了一些值得探索的方向,包括使用 DPO 让 LLM 学会基于反馈学习推理、执行多轮对话、充当智能体、生成图像和视频等。


