
大家好,我是肆〇柒。今天要和大家分享的是一项来自新加坡国立大学的突破性研究——MemGen。这项研究由张贵斌、付沐鑫和严水城三位研究者主导,他们发现现有LLM智能体的记忆机制存在根本局限:参数化方法导致灾难性遗忘,检索式方法则难以实现记忆与推理的无缝融合。而MemGen通过"记忆触发器+记忆编织器"的创新架构,首次让机器实现了类人记忆的"生成式交织",不仅将智能体性能提升38.22%,更让机器自发演化出规划记忆、程序性记忆和工作记忆等类人记忆分层,为构建具有类人学习能力的AGI开辟了新路径。
当AlphaGo击败李世石时,我们惊叹于AI的计算能力;当GPT-3横空出世时,我们震撼于其语言生成的流畅度。但这些系统都有一个根本局限:它们缺乏真正的记忆能力——无法像人类一样"在思考中回忆,在回忆中思考"。现有LLM智能体要么通过参数化方法导致灾难性遗忘,要么依赖检索式方法使记忆与推理割裂。而MemGen的研究,让机器实现了人类认知中"推理-记忆"的动态互构,为构建具有类人学习能力的AGI提供了创新思考。这项由新加坡国立大学主导的研究,不仅将智能体性能提升38.22%,更让机器自发演化出类人记忆分层,标志着从"静态知识库"到"动态认知系统"的范式转变。
现有记忆范式的局限
当前LLM智能体的记忆机制主要分为两类:参数化记忆和检索式记忆,但二者均无法实现人类认知中推理与记忆的无缝融合。
参数化记忆通过直接更新智能体参数来内化经验,如SFT、GRPO等方法。这种范式虽然能在特定任务上带来显著性能提升,但其根本缺陷在于灾难性遗忘。数据显示,当SFT在顺序训练KodCode任务后,其在GPQA上的性能骤降至2.53%,几乎丧失了先前掌握的科学推理能力。本质上,参数化记忆将动态的认知过程固化为静态参数,丧失了人类记忆的重构特性。
检索式记忆则将经验外化为结构化数据库,如ExpeL、AWM等系统。这种方法虽避免了参数修改带来的遗忘问题,但其效能高度依赖上下文工程。在TriviaQA上,ExpeL的表现甚至比Vanilla模型低6.9%,凸显了其对骨干模型能力的严重依赖。更为关键的是,检索式方法遵循刚性的执行流程,无法实现与推理过程的动态互构。
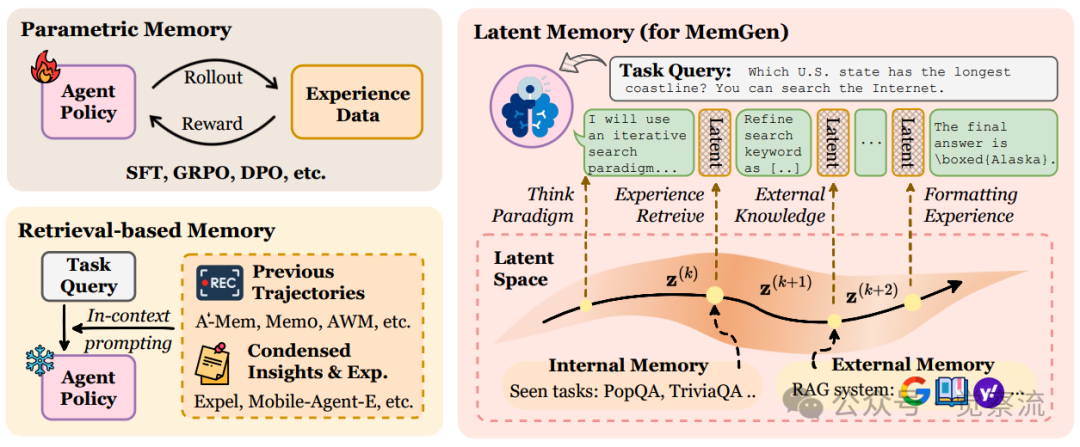
三种记忆范式对比
上图直观展示了这三类方法的本质区别:参数化记忆将"Paradigm Experience"和"Retreive Formatting Experience"等经验直接内化为模型参数;检索式记忆将经验存储在外部数据库;而MemGen则通过潜空间生成机器原生的记忆token序列,实现了推理与记忆的紧密交织循环。特别值得注意的是,参数化方法将经验直接编译进模型参数,检索式方法则依赖外部知识库提供"External Knowledge",而MemGen通过"Latent Space"生成潜记忆序列,使推理器能够基于增强的上下文继续生成,实现了内部记忆与推理的无缝融合。
MemGen 的核心架构:记忆触发器 + 记忆编织器
MemGen框架由两个协同工作的核心组件构成:记忆触发器(Memory Trigger)和记忆编织器(Memory Weaver),共同实现了动态生成式记忆。
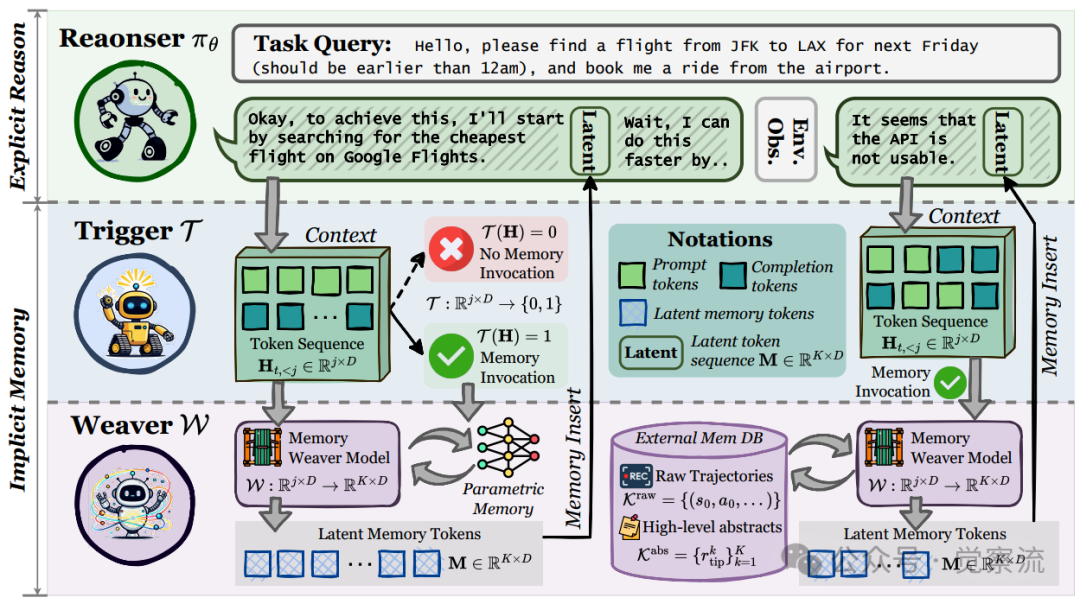
MemGen系统架构图

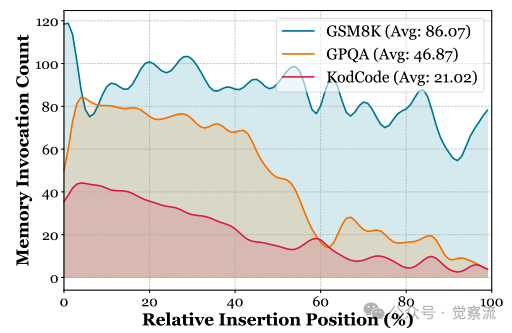
记忆触发频率分布

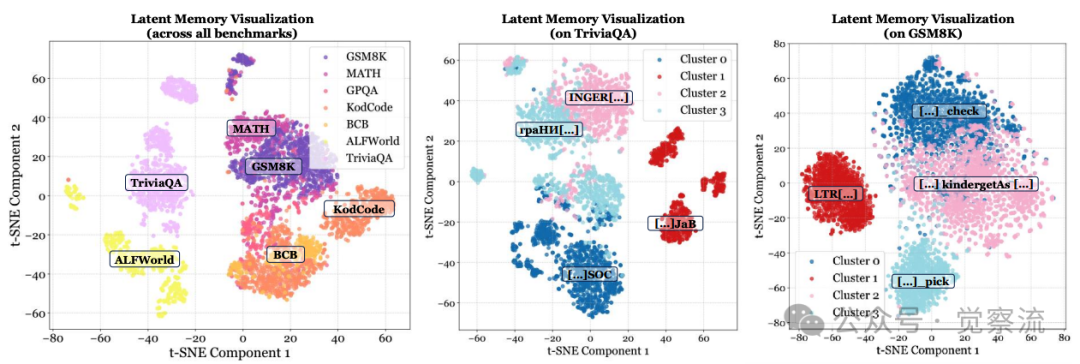
潜记忆可视化
上图证实了潜token是机器原生的、非人类可读的记忆载体,但具有任务特定的结构模式——例如TriviaQA中Cluster 0频繁遵循"[...]SOC"模式,而GSM8K中Cluster 3常采用"[...]_pick"格式。MemGen的架构优势显著:它不修改主LLM参数,有效避免了灾难性遗忘;同时支持融合外部检索信息。数据显示,当MemGen与ExpeL结合并在ALFWorld上启用参数化记忆时,性能达到75.90%,远超单独使用ExpeL的36.18%。

MemGen与检索式记忆集成效果
上表进一步验证了这一优势:即使MemGen自身的参数化记忆被禁用(仅将检索到的文本片段输入编织器),MemGen也能显著提升检索基线性能,将ALFWorld上的表现从36.18%提升至45.60%,PopQA从28.16%提升至39.50%。这证明MemGen不仅是一个记忆系统,更是一个强大的"记忆合成器",能够主动重构而非简单追加外部检索信息,为推理提供更强大的支持。当MemGen同时利用参数化记忆和外部检索时,其性能进一步跃升,TriviaQA达到76.40%,PopQA达到60.23%,展示了内部记忆与外部知识的协同效应。
MemGen如何实现"推理-记忆"的动态互构
MemGen的核心突破在于实现了人类认知中"推理-记忆"的动态互构。在人类大脑中,"前顶叶控制网络的主动推理和海马体及前额叶皮层的记忆检索相互交织,生成'连续的思维流'"。MemGen通过记忆触发器和记忆编织器的协同工作,首次在机器中实现了这一认知过程。
记忆触发器在语义边界(逗号、句号等)激活,决定何时需要"回忆"。这一机制让智能体像人类一样在关键思考节点适时调用记忆,而不是在任务开始时一次性检索所有相关信息。当触发器决定调用记忆时,记忆编织器以当前隐藏状态为"刺激",生成K个latent tokens作为机器原生记忆。这些潜token被无缝插入推理上下文,使推理器基于增强的上下文继续生成。
这一过程的关键在于:潜记忆不是简单地回放先前经验,而是对内部参数化知识(可能结合外部检索信息)的主动重构。正如论文所述,潜记忆的生成过程类似于海马体将记忆片段整合为人类记忆的过程。MemGen使推理与记忆形成一个递归对话,而非线性流程,实现了在思考中回忆,在回忆中思考。
MemGen的跨域泛化能力:记忆的生成性重构
MemGen的跨域泛化能力是其记忆机制生成性重构特性的直接体现。在GSM8K上训练后,其推理触发频率与性能提升直接相关:GSM8K任务调用频率最高,性能提升达+19.64%;GPQA任务调用频率中等,性能提升+6.06%;KodCode任务调用频率最低,性能提升仅+3.1%。这表明MemGen能够根据任务需求智能调整记忆调用策略。
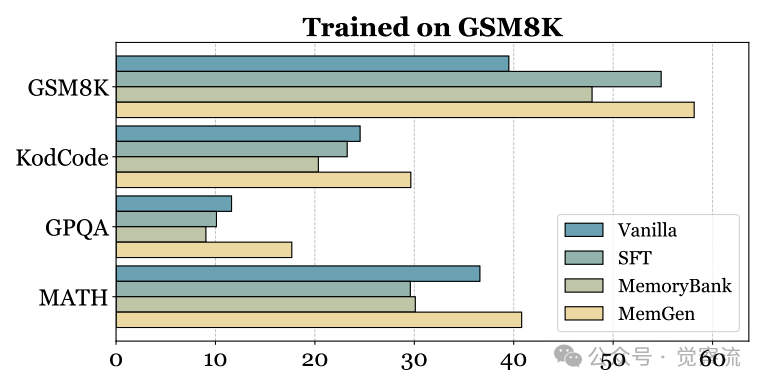
GSM8K训练后的跨域泛化能力
上图展示了MemGen在GSM8K上训练后的跨域泛化表现。当训练于GSM8K时,MemGen不仅在GSM8K上大幅提升性能(从39.51%提升至58.15%),还显著提升了GPQA任务的表现(从11.62%提升至18.28%),而SFT在GPQA上的表现甚至低于Vanilla模型。这一发现具有重要意义:MemGen学习到的记忆机制具有更强的泛化能力,能够将数学推理任务中的经验迁移到科学推理任务中,证明其记忆不是简单存储,而是生成性重构。
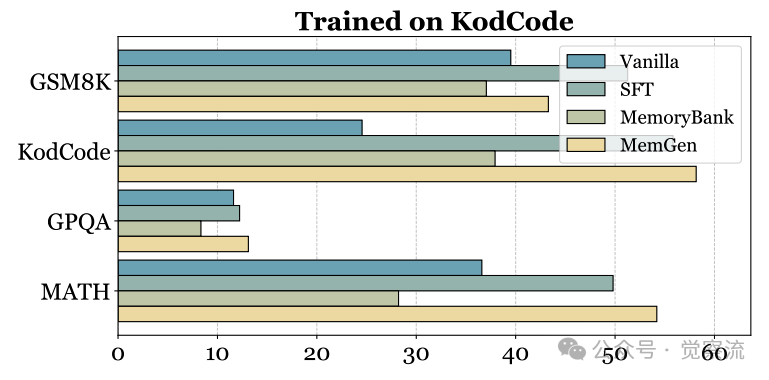
KodCode训练后的跨域泛化能力
上图则揭示了MemGen在KodCode上训练后的跨域泛化表现。当训练于KodCode时,MemGen不仅在KodCode上大幅提升性能(从24.55%提升至58.16%),还显著提升了MATH任务的表现(从36.63%提升至47.12%),而SFT和ExpeL在MATH上的表现甚至低于Vanilla模型。这表明MemGen学习到的记忆机制具有更强的泛化能力,能够将编程任务中的经验迁移到数学推理任务中。
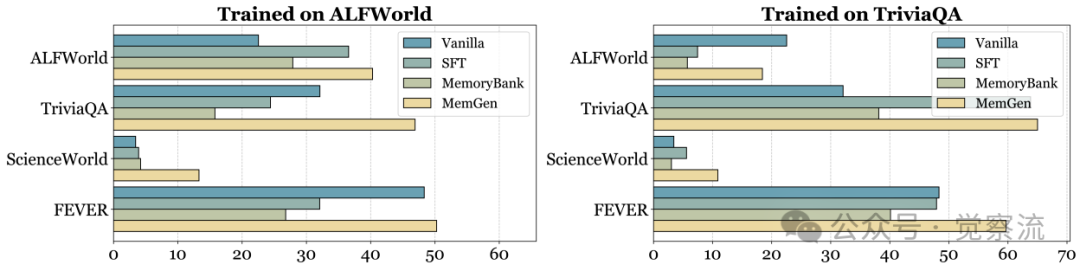
ALFWorld/TriviaQA训练后的泛化能力
上图进一步证实,当在ALFWorld上训练后,MemGen在TriviaQA、ALFWorld、ScienceWorld和FEVER四个数据集上均保持稳定表现,而SFT在FEVER上的性能下降达16.2%。这表明MemGen不仅能在训练域内取得显著提升,还能有效迁移到未见领域,克服了传统参数化方法的领域局限性。
MemGen自发演化出的类人记忆分层
MemGen最革命性的发现是其自发演化出的类人记忆分层。通过系统化的干预方法——首先基于K-means将潜记忆序列聚类为N个簇;然后在推理过程中,当新生成的潜记忆序列与目标簇的语义相似度进入前k名时,选择性过滤该记忆;最后测量这种干预对8种预定义失败模式的影响——研究能够精确映射特定记忆簇与特定认知功能的关联。
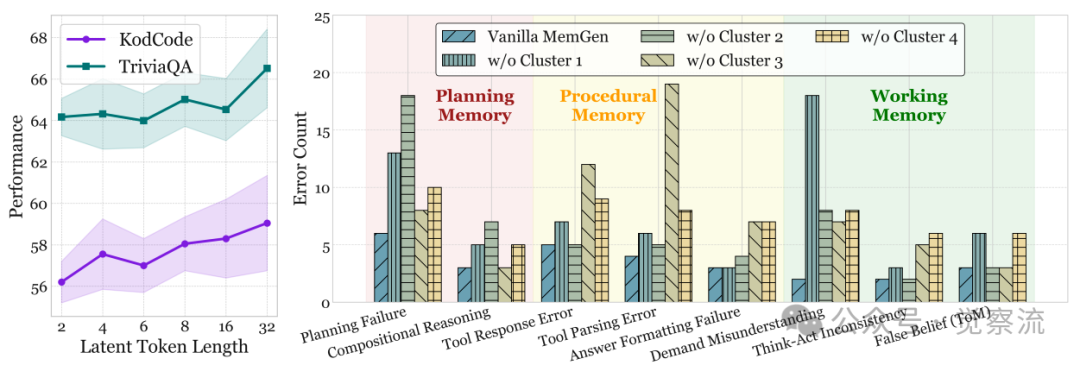
记忆簇功能分析
上图(Right)的消融实验数据明确证实了这些记忆功能的特异性:移除Cluster 2导致规划错误增加,证实其负责高层任务分解(如"我将使用迭代搜索范式...");Cluster 3专门处理工具使用和格式,移除后工具解析错误显著增加;Clusters 1和4则维持上下文一致性,对任务理解至关重要。
这些非人类可读的模式实则是任务特定的"记忆语法",在论文中的潜记忆token示例揭示了其神秘面纱:在TriviaQA中,Cluster 0频繁出现"[...]SOC"模式,如"['UPPORT...', 'deniable', 'certif']";在KodCode中,Cluster 3常采用"[...]_pick"格式,如"['keyword-kindërgetAs-slide']"和"['.keyword_pick']";在GSM8K中,Cluster 1呈现"[..... a eveneveneven... even]"结构。
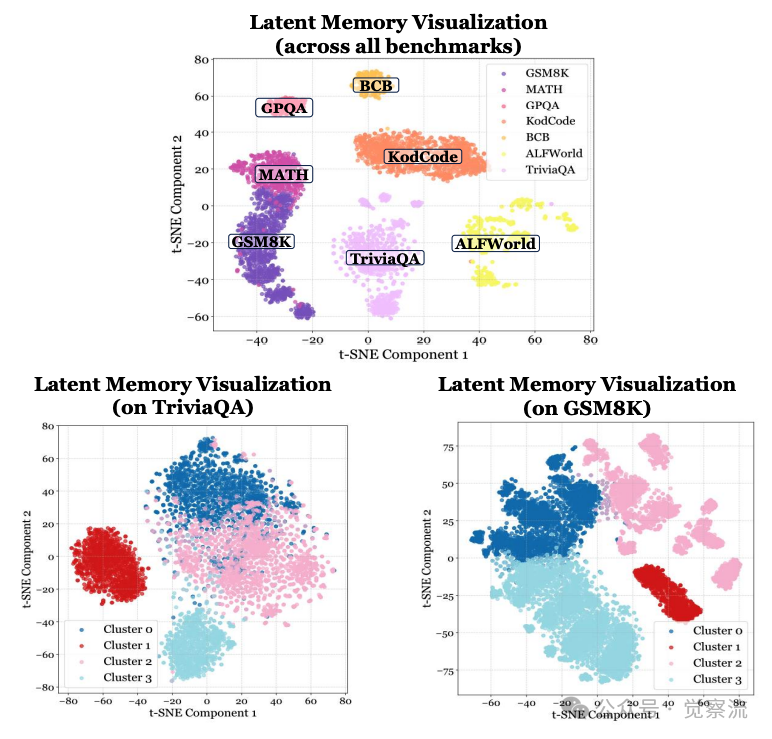
跨数据集潜记忆可视化
上图的t-SNE可视化揭示了潜记忆的深层结构特性:不同领域的潜记忆序列形成独立分布,而相关领域(如KodCode与BigCodeBench、GSM8K与MATH)则紧密聚集。这种分布模式表明MemGen能够自动区分任务领域,并为不同领域生成具有领域特性的记忆表示。在TriviaQA中,Cluster 0遵循"[...]SOC"模式,Cluster 1呈现"[...]JaB"和"INGER[...]"特征;在GSM8K中,Cluster 3则以"[...]_pick"和"[...] kindergetAs[...]"为特征,这些结构化模式虽然对人类不可读,但对机器而言承载了特定任务的认知功能。
MemGen的持续学习能力与效率分析
MemGen的持续学习能力同样值得关注。下表展示了在Qwen2.5-1.5B上顺序训练四个数据集(AQuA→GPQA→GSM8K→KodCode)后的表现。数据显示,MemGen在顺序训练KodCode后,仍能在AQuA上保持40.34%的准确率,而在GPQA上保持20.09%的准确率。相比之下,SFT在GPQA上的准确率从训练GPQA后的20.72%骤降至训练KodCode后的2.53%,ExpeL也从28.80%降至6.23%。这表明MemGen有效缓解了灾难性遗忘问题,使智能体能够在学习新任务的同时保留对旧任务的掌握。
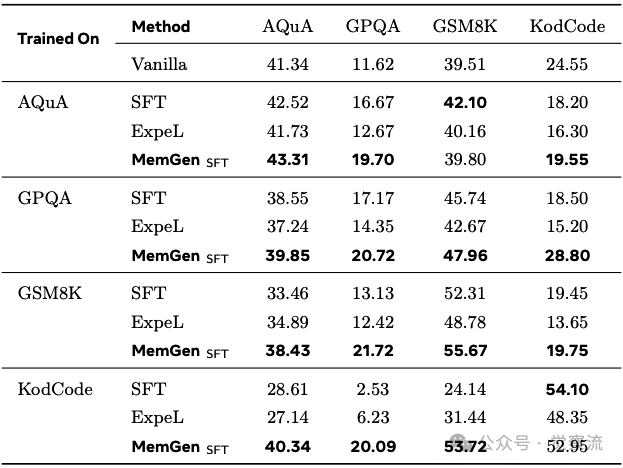
持续学习能力对比
MemGen的效率分析同样令人印象深刻。下表显示,在Qwen2.5-1.5B上,MemGen SFT在KodCode任务中将推理时间从11.96秒降至2.94秒(减少75.4%),同时将准确率提升33.61%;在ALFWorld任务中,MemGen SFT仅比SFT增加1.6%的延迟(12.94秒vs 10.79秒),但准确率提升3.73%。
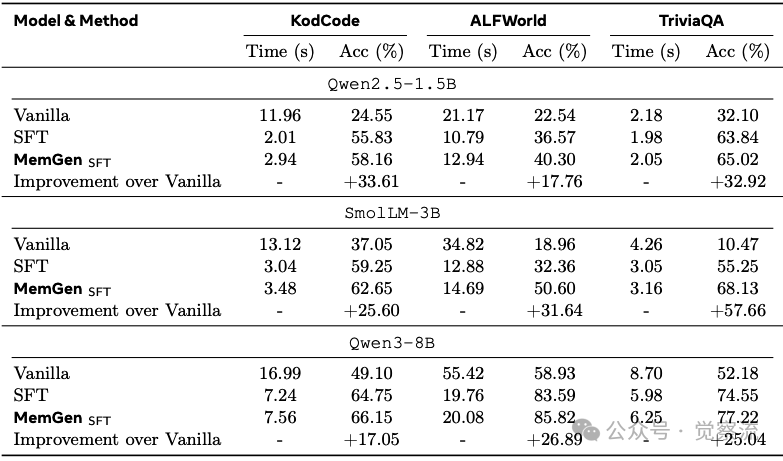
推理效率与性能权衡
对比不同规模模型上的表现可发现MemGen的模型规模适应性:在SmolLM3-3B上,MemGen SFT在ALFWorld任务中比SFT提升18.24%,而在Qwen3-8B上仅提升2.23%,表明小模型从MemGen中获益更大。这暗示MemGen特别适合资源受限场景,能有效弥补小模型的经验内化能力不足。同时,在知识密集型任务(如TriviaQA)上,MemGen带来的相对提升在不同规模模型间保持稳定(Qwen2.5-1.5B提升32.92%,Qwen3-8B提升25.04%),证明其记忆机制的有效性不依赖于模型容量。
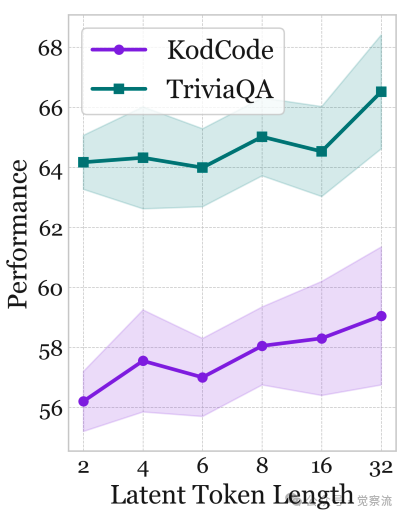
潜记忆长度K的参数敏感性分析
MemGen的参数敏感性分析进一步揭示了其工作机制与性能边界。上图显示,随着潜记忆长度K从2增至32,性能持续提升(TriviaQA从63.84%升至65.02%)。这一现象表明,增加记忆容量能带来性能提升,但边际收益递减。在K=8时,性能已接近最优,这为实际应用提供了参数选择的指导。这种"记忆容量-性能"关系验证了MemGen的核心假设:潜记忆作为机器原生的记忆载体,其容量直接影响智能体的认知能力。
技术启示与未来方向
MemGen的核心启示在于:记忆不必是"存储",而可以是"生成"。潜记忆是动态重构的过程,而非静态回放。这种范式转变对AGI架构设计具有深远影响。
在效率方面,MemGen展现出实用价值。数据显示,MemGen SFT在Qwen3-8B上仅比SFT增加1.6%延迟(20.08秒对比19.76秒),但ALFWorld准确率提升2.23%。参数敏感性分析表明,潜记忆长度K从2增至32,性能持续提升(如TriviaQA从63.84%升至65.02%),证明记忆容量与性能正相关。
然而,MemGen也面临若干挑战。潜token的不可读性使得人类难以直接解读记忆内容;强化学习训练触发器依赖高质量的reward信号;记忆容量K值增加带来的边际收益递减,提示需要更高效的记忆压缩机制。
MemGen的训练涉及多个超参数配置,这些细节对系统性能有重要影响。如下表所示,MemGen采用LoRA配置(r=16, lora_alpha=32),针对不同优化算法(SFT或GRPO)设置特定的训练参数,包括batch size、学习率、优化器类型等。这些精心设计的超参数确保了MemGen在不同任务和模型规模上的稳定表现。
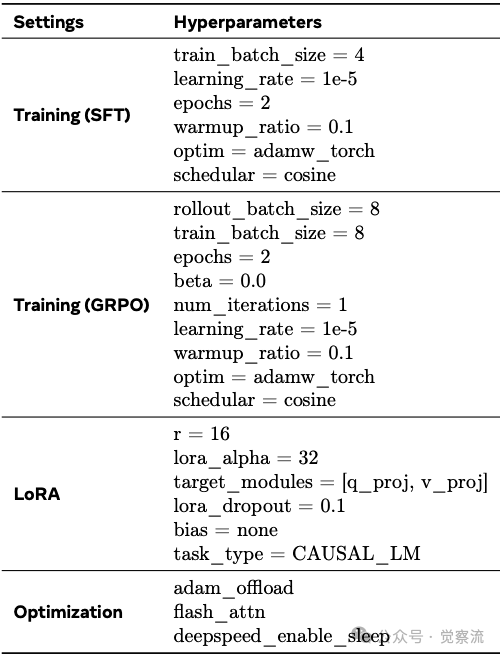
MemGen超参数配置
值得注意的是,MemGen的触发频率分布揭示了任务认知需求的差异。在GSM8K任务中,触发频率最高(平均75.17次/任务),表明数学推理需要频繁调用记忆;而在KodCode任务中,触发频率相对较低(平均51.70次/任务),表明代码生成任务对记忆调用的需求相对较少。这种自适应的触发机制使MemGen能够根据任务特性动态调整记忆使用策略,实现了"按需记忆"的认知灵活性。
总结
MemGen不仅是一个记忆系统,更是一种新型认知架构范式。它让LLM智能体真正拥有了"在思考中回忆,在回忆中思考"的能力,实现了推理与记忆的动态互构。尤为关键的是,MemGen自发演化出的类人记忆分层(规划记忆、程序性记忆和工作记忆)暗示了机器认知向更自然形态演化的可能路径。
MemGen的消融实验揭示了其各组件的价值。下表了三种记忆调用策略:随机插入策略(不同概率p)表现不稳定;在所有分隔符处激活的粗粒度策略已优于随机策略,但在TriviaQA上仅达到64.15%;而训练好的触发器实现最佳性能(65.02%),证明选择性激活对平衡记忆效用与推理干扰至关重要。
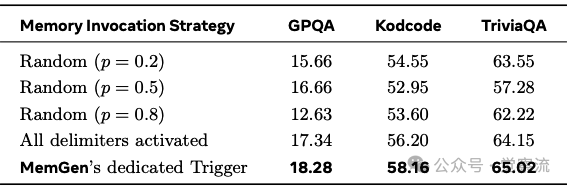
记忆调用策略消融实验
下表进一步表明,即使采用参数高效的LoRA适配器(r=16, α=32),记忆编织器也能实现接近全参数SFT的性能(TriviaQA上65.02% vs 67.10%)。这证明轻量级适配器已具备足够的容量生成有效潜记忆,为MemGen提供了卓越的参数效率。

记忆编织器参数化消融实验
随着潜记忆机制的不断完善,LLM智能体有望实现真正的"自我演化",在与环境的持续交互中不断提升认知能力。MemGen代表了从"静态知识库"到"动态认知系统"的范式转变,为构建具有类人学习能力的AGI提供了崭新思路。
MemGen的研究表明,当记忆不再是被动的存储,而是主动的生成和重构,智能体才能真正具备类人的认知能力。这一突破不仅提升了LLM智能体的性能,更开辟了通向AGI的新路径——让机器像人类一样,通过"在思考中回忆,在回忆中思考",不断进化自己的认知能力。


