
为什么一个中国公司的开源模型,能让硅谷的闭源巨头们感到紧张?
昨天看到月之暗面发布Kimi K2的消息,我特意去测试了一下。说实话,刚开始我还是有点怀疑,毕竟之前见过太多"对标GPT-4"的宣传最后都不了了之。
但这次不一样。
在SWE-bench Verified这个被称为"AI编程能力终极考验"的基准测试中,Kimi K2拿下了65.8%的成绩。要知道,GPT-4.1在同一测试中只有54.6%,就连业界标杆Claude Sonnet 4也只是略微领先。
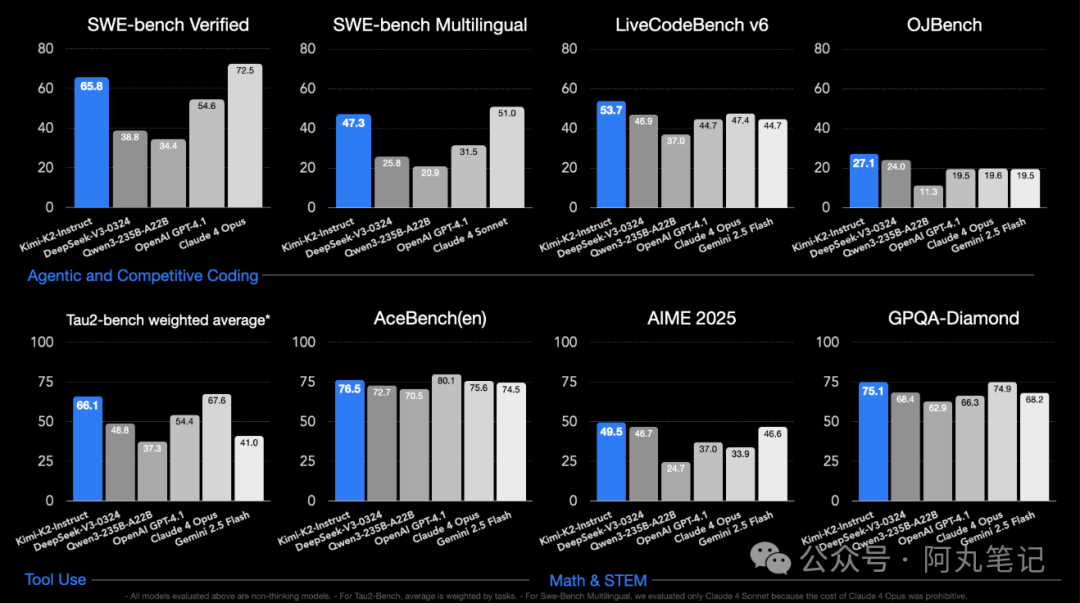
更关键的是,Kimi K2是完全开源的。
SWE-bench到底测什么?
我查了一下SWE-bench的资料,发现这个测试确实挺狠的。它不是简单的代码生成,而是给AI一个真实的GitHub仓库和一个bug报告,让AI自己去理解代码、找到问题、写出修复方案。
整个过程包括:
• 理解复杂代码结构 - 不是几行代码,是几万行的真实项目
• 跨文件关联分析 - 修改一个函数可能影响十几个其他文件
• 生成准确补丁 - 既要修复bug,又不能破坏现有功能
这种测试难度,让很多模型的通过率连20%都达不到。Kimi K2的65.8%,确实算是个突破。
技术上有什么特别?
Kimi K2最有意思的地方,是它专门为"AI代理"场景优化。什么意思呢?就是不光能聊天,还能真的去执行任务、调用工具、解决问题。
月之暗面展示了一个demo:给Kimi K2一个数据分析任务,它能自己分析远程工作薪资数据,做统计评估,最后生成一个可交互的HTML页面。整个过程完全自主完成。
这就像是从"会做题的学生"变成了"会解决实际问题的工程师"。
技术细节上,Kimi K2用了一个叫MuonClip的新优化器,替代了业界标准的AdamW。训练过程据说非常稳定,没有出现大模型训练常见的崩溃问题。
模型规模也挺有意思:1万亿参数,但每次推理只激活320亿。这种混合专家架构,在保证性能的同时控制了计算成本。
开源的震撼
但最让我惊讶的,其实是开源这件事。
现在想用Claude Sonnet 4,每百万token要付15-60美元。GPT-4.1也差不多。而Kimi K2,你可以直接下载模型权重,本地部署,只要硬件够用,用多少都不收费。
当然,本地部署的门槛不低。官方建议至少要两台512GB内存的苹果M3 Ultra,或者多张NVIDIA B200 GPU。对普通开发者来说,还是通过API使用比较现实。
但关键是选择权在你手里。想要隐私保护?本地部署。想要便宜?云端API。想要定制?拿去微调。
这意味着什么?
我觉得Kimi K2的发布,可能标志着AI模型竞争格局的一个转折点。
之前,顶级AI能力基本被几家美国公司垄断。开发者要么接受他们的定价,要么用性能差很多的开源替代品。现在突然出现一个开源模型,性能直接对标顶级闭源产品,这个冲击可想而知。
对开发者来说,这是好事。更多选择,更低成本,更大的技术自主权。
对那些闭源模型的提供商来说,压力就大了。光靠技术领先已经不够,还得考虑如何在开源竞争中保持优势。
我试了试Kimi K2处理一个简单的代码重构任务,速度和质量确实不错。虽然还没有深度测试,但第一印象是:这确实是个值得关注的突破。
如果你也对AI编程感兴趣,建议去试试。月之暗面提供了API接口,也有详细的本地部署文档。看看这个"中国制造"的AI,能不能在你的项目中发挥作用。
技术无国界,好工具大家一起用。


