“VLA的下限,就是端到端的上限”。
这是元戎启行CEO周光在VLA(视觉语言动作)模型发布会上,对VLA能力的概括。

在周光看来,此前的智能辅助驾驶系统都可以归为端到端1.0阶段,上限已至,就像尼安德特人 (智力不行的人种,已灭绝)。
VLA则是端到端2.0阶段,目前还处于及格水平,但下限已超越1.0时期的上限,就像智人(现代人类)。
“智人版端到端”采用了全新架构,标志着辅助驾驶步入大模型时代。
因此具备了全新的能力,融入了思维链,AI司机会“害怕”了,就像生物进化出了保护机制,还能给你分析当前场景,输出文字解释自己的决策。
这也是业内第一家推出VLA方案的辅助驾驶供应商。在此之前,VLA基本处于车企自研状态,而且据其中上市公司透露,其研发预算在数亿元甚至数十亿元级别。
元戎第一枪,打掉了上亿自研预算。在此之后,车企VLA立项或许都要面临拷问:是不是比元戎方案更好?有没有必要投入如此规模预算重复造轮子??
而且元戎也并没有把VLA的应用限定在辅助驾驶。
在发布会上元戎明确,要用特斯拉的方式做Robotaxi,不走依赖高精地图Waymo路线。未来机器人也会和车端基于同一套系统。
在发布会后,关于VLA的现状和未来,元戎分享了很多共识和非共识。
比如大算力,具体要多大?
在元戎看来起码要基于英伟达Thor-U,也就是700TOPS,Orin平台无法落地VLA。
元戎启行推出VLA,是端到端1.0方案进入瓶颈期的必然。
元戎透露,目前其端到端方案量产数量已接近10万台,均可实现城区NOA。随着量产规模扩大,获取到的数据增多,元戎感知到了技术瓶颈。
在元戎看来,当前的技术方案主要有三大限制:
首先是BEV(鸟瞰)视角先天就存在局限性,就像咱们日常玩“吃鸡”或者其他射击游戏,辅助驾驶系统遇到一面墙,因为看不到墙后的场景,会下意识的认为墙后不存在物体。
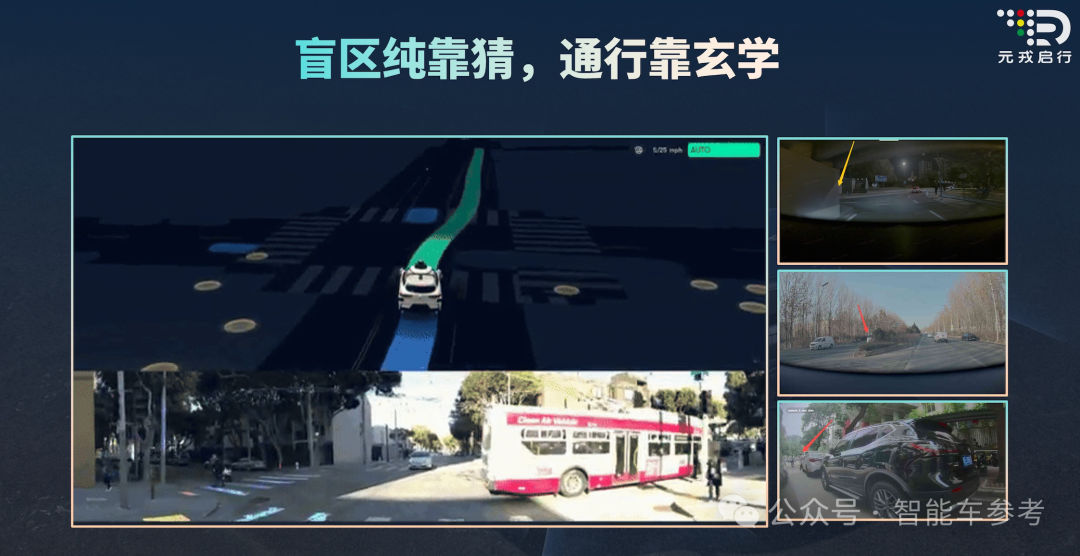
但有经验的玩家,遇到视野盲区,会下意识地思考,墙后是不是藏着什么东西,从而采取谨慎的策略往前走。
这种对空间关系的理解和思考,是端到端1.0时代基于CNN(卷积神经网络)的范式无法实现的。
其次,当前的辅助驾驶系统很多都是“文盲”,理解不了咱们日常开车会遇到的文字信息标识,比方说交通标志、临时路牌和地面上印刷的文字。
典型代表就是限制时段的公交车道,这也是今年年初马斯克坦承FSD入华面临的挑战之一。

最后,目前的端到端方案可解释性比较差,像一个黑盒子,用户不知道系统为什么此时刹车或者变道,想了解背后的逻辑。
如果系统具备语言理解能力,就能向用户做出解释,让用户用起来更有安全感。
总之,辅助驾驶需要具备语言和空间理解能力,以及更强的可解释性,但现在的范式满足不了新的需求。

元戎认为,基于传统CNN(卷积神经网络)打造的模型,无论再上多少手段和额外训练手段,提升手段都比较有限。
是时候重塑底层架构,突破技术瓶颈了。
元戎选择转向基于GPT(Generative Pre-trained Transformer)的架构,打造VLA模型。

一方面,VLA从互联网进行了海量数据蒸馏和训练,模型积累了丰富的常识,这是过去CNN或者BEV端到端系统没有的。
另一方面,VLA还具备了思维链(CoT)能力,能够理解长时序的数据并进行推理,短期记忆依靠视频类型的数据,长期记忆就依靠关键帧和语言描述。
这一点就像咱们人类的记忆系统,如果我问你今天开车上班都遇到了什么,你可能会想起从出门到目的地一路上的各种情况。

但是如果问你当年考驾照的情况,那你脑子就只记得几个关键图片或者瞬间了,比如说“扣100分,考试不通过”诸如此类。
新范式培养出新能力,会带来什么新体验?
元戎提出「防御性驾驶」,让AI学会害怕,让用户用的安心。
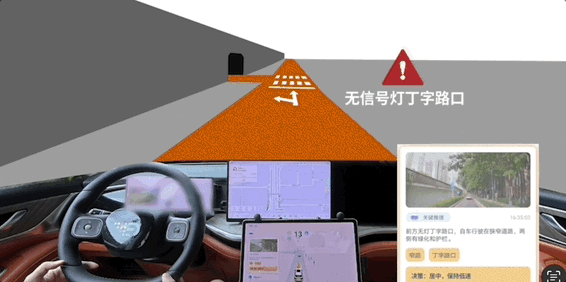
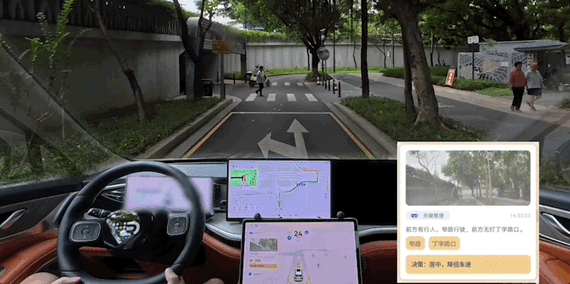
比如遇到前无信号灯、左有桥洞的岔路,系统会主动识别,减速慢行,并在右下角给出解释。
再比如雨天转向前,遇到临停车制造了盲区,系统也会降低车速,缓缓转向。

雨天遇到积水也会主动减速,避免水溅到行人。

至于语音控车,比如给车子下指令靠边停车、变道,在元戎看来是比较基础的功能,只是拨杆变道换了一种形式。
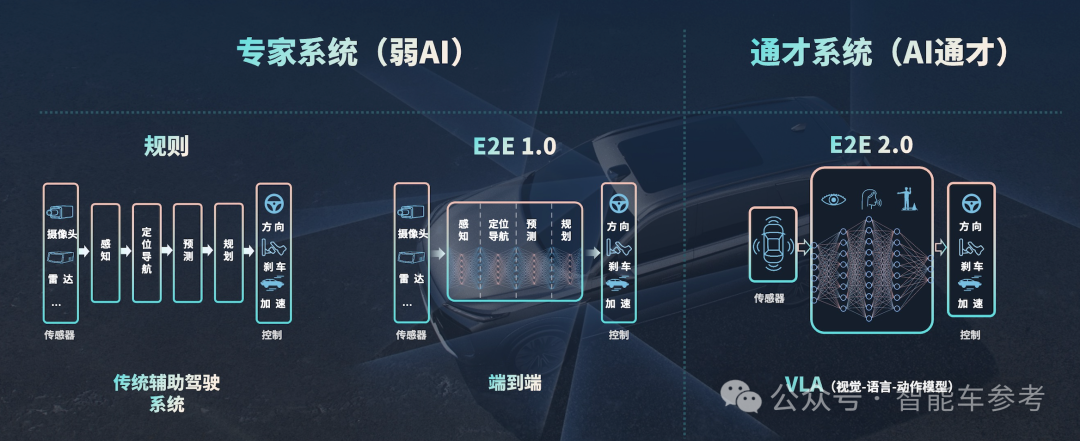
随着VLA的推出,元戎认为智能辅助驾驶也来到了新的阶段。
规则驱动和基于CNN的端到端1.0方案,属于弱专家系统,相当于人类智慧中的「小学生水平」,现在的VLA属于通才系统。这套系统同时支持融合感知和视觉方案,可以基于多芯片平台开发。
据了解,目前已经有5款车型确定将在今年搭载元戎的VLA模型,搭载元戎方案的车辆累计将达20万台。
在发布会最后,元戎总结认为,辅助驾驶和自动驾驶注定与大模型共生,行业会全面走向GPT架构的端到端模型。
当然受限于车端的条件,比如芯片算力和能耗要求,车端模型相比动辄数千亿甚至万亿参数规模的大语言模型还是一个“婴儿”,未来的方向是让模型自主学习、持续进化。
在发布会后,元戎启行创始人、CEO周光随即接受了访谈,围绕行业现状和未来,分享了一系列共识和非共识。
Q:能否通过思维链的表现来评价VLA的能力?
周光:没有CoT,就不算是VLA。目前行业还没有像NLP那样统一的评测基准,但未来可能会建立基于物理场景的专用Benchmark。
Q:满分10分你给当前版本的VLA打几分?
周光:我个人打6分,刚及格。VLA模型仍处于早期,相当于“幼年期”,但上限远高于端到端方案。新一代架构需要新一代芯片支持,这不是CNN时代可比的。
Q:从6分到8分需克服哪些困难?
周光:目前技术仍无法实现全无人驾驶。缺乏推理能力,仅靠高精地图无法根本解决泛化问题。VLA是当前最优路径,但彻底解决问题需技术持续突破。
Q:你认为语音控车属于基础功能。那么对VLA来说,真正难的是什么?
周光:最难的是思维链(Chain of Thought, CoT)和长时序推理。这才是VLA真正的核心能力。
Q:非VLA架构也可实现防御性驾驶,VLA是必须的吗?
周光:统计方法能部分实现防御策略,但复杂场景需真正推理能力。VLA因具备思维链和语言推理,能更彻底解决这些问题。BEV在空间理解上存在天然局限。
Q:元戎怎么看待世界模型和仿真数据用于训练?
周光:VLA与第一代端到端最根本的区别是模型架构变了——从CNN转向GPT。训练方法比如是否引入RL(强化学习),只是策略问题。CNN架构本身无法实现类似人类的推理和泛化能力。
Q:元戎训练数据源自哪里?
周光:数据来源多方面:包括自有测试车队、量产车数据,以及生成数据。要实现GPT架构的预训练,必须依赖大规模、多样化数据集,这是CNN模型无法胜任的。
Q:VLA模型是否也会出现“幻觉”?如何减少?
周光:预训练阶段确实可能产生幻觉,但通过后训练对齐技术,已经能极大抑制这一现象。现在主流大模型(如豆包、千问)幻觉现象已经很少,这方面已有较好的解决方案。
Q:VLA模型相比端到端方案会贵多少?成本差距大吗?
周光:主要成本差异在芯片,其余部分基本一致。芯片成本取决于制程工艺,千T级芯片算力时代已经到来,例如特斯拉2500TOPS芯片,双芯片即可实现5000TOPS。
Q:LLM强于文本推理而非空间感知,你如何看待?
周光:更准确地说,VLA本质是“基于GPT的端到端模型”。目前坚持投入大算力的公司,比如特斯拉和小鹏,其实都在朝这个方向走。
比如特斯拉AI5芯片算力达2500TOPS,CNN模型参数量有限,显然不需要如此大规模的算力,只有GPT架构天然适合扩展,才需要大参数和大算力支持,这才是未来方向。
Q:VLA模型帧率目前低于某些端到端方案(10~20帧),这是现阶段的限制吗?有没有弥补方式?
周光:帧率影响本质是延迟问题。从100毫秒降至50毫秒已有明显收益,VLA初期帧率稍低是正常现象。帧率并非越高越好,预判能力增强也能弥补帧率限制。
Q:马斯克说“激光雷达让自动驾驶更不安全”,你如何看待?
周光:短期来看,激光雷达受限于技术发展和数据集的成熟度,仍有其价值,对通用障碍物识别仍有重要作用。
长期来看,大模型有望逐步解决现在依赖激光雷达的部分任务。
Q:如果持续提升VLA的推理能力,未来可能带来哪些突破?
周光:VLA目前还未完全实现思维链,这是关键差距。长远来看,语言和推理能力是实现完全无人化自动驾驶的核心。
比如遇到“左转不受灯控”这种临时标识,依赖地图更新是不够的,需要实时理解。
VLA在这条路上任重道远,需要更多技术沉淀。特斯拉之所以投入十倍算力和参数,正是因为GPT架构是明确方向,CNN无法支撑这种扩展。
Q:车端和(未来)机器人用的VLA模型是同一套架构吗?
周光:是的,VLA本身是通用架构,不再为特定场景定制。正如我们年初发布的RoadAGI策略所说,未来这一技术可泛化至多种移动场景——包括小区、电梯、办公室等室内外环境。
现在的机器人很多还依赖遥控,你看最近的那个“机器人马拉松”比赛,一堆机器人跟在后面,比较不高端。还有的用“巡线”,我高中做机器人的时候就在用这种技术了。
我们希望能实现真正自主、通用的移动能力。
Q:元戎的VLA支持多种芯片平台,具体都有哪些?厂商可以指定芯片吗?
周光:芯片适配有一定要求,比如基础算力、带宽等。模型训练完成后会经过蒸馏和量化,适配需要满足基本条件。
合作中车厂可以提出芯片需求,适配成本(时间、资金、数据)都是可协商的。我们目前以英伟达Thor为起点,未来会支持更多芯片,并不局限于一家。
Q:VLA会加速元戎出海吗?
周光:出海的关键在于合规。如果特斯拉能进入中国训练,体验会完全不同。AI模型正越来越通用化,互联网数据训练的基础模型已具备较强泛化能力,不存在“中国模型只懂中国”的说法。AI发展的大趋势是走向通用。
Q:长期看仿真数据在训练中的占比会达到多少?仿真数据生成能力会成为壁垒吗?
周光:仿真需基于真实数据,否则无法有效模拟。现实数据仍是主体,仿真作为补充。从预训练到后训练阶段,仿真比例会逐渐提升。行业应关注大模型整体发展,避免局限在自动驾驶领域。技术本质是相通的,就像人脑神经元结构并无太大差异。
Q:元戎是否会参与L4竞争?
周光:传统自动驾驶等级划分已过时,真正的无人驾驶需推理能力,纯规则系统无法应对“红灯可否左转”这类问题。
Q:有厂商大幅减少实车测试、增加仿真里程,这是行业趋势吗?
周光:我们更专注于自身技术路线。仿真是数据来源的一种,关键不在于是真实还是仿真,而在于数据质量。高质量数据集才是模型优化的核心。
Q:辅助驾驶研发能跳过端到端,直接从规则转向VLA吗?
周光:每个阶段都无法跳过,从有图、无图、端到端到VLA,整个发展过程必不可少,最多只能压缩某些阶段的时间,但不可能完全绕过。目前VLA的下限已经超过端到端方案的上限。
Q:以后各家厂商在研发高阶智能辅助驾驶芯片时,除了做到数千TOPS算力,还必须对Transformer的原生、高效支持作为核心设计指标?
周光:确实如此。早期芯片主要针对CNN设计,未来一定会加强对Transformer的支持,尤其是在FP4、FP6等精度的优化上。
Q:为什么行业当下都在强调强化学习?
周光:强化学习只是模型训练的一种手段,属于“后训练”阶段的一部分。如今行业已进入后训练时代,但这本身并不值得过度强调——就像GPT或Waymo也不会单独强调强化学习。
Q:有厂商表示训练VLA需要数万张卡,元戎启行如何看待这种巨大的资源消耗?
周光:元戎在技术选型上一直较为精准,VLA是一个全新领域,方向选择很多,如果有清晰的技术判断,资源消耗完全可以更高效。事实上,辅助驾驶场景的GPT模型规模相对可控,比如7B模型并不需要极端庞大的算力。
Q:华为不走VLA路线,你怎么看?
周光:若车端算力不足,确实可能选择其他路径。但真正要实现思维链仍需VLA方向。
Q:VLA能上车什么价位的车型?
周光:目前15万元以上的车型都可以适配,10万级车型通过优化也有机会搭载。


