编辑 | 云昭
出品 | 51CTO技术栈(微信号:blog51cto)
今天凌晨,智谱新开源了自家的最强模型 GLM 4.5。
从官方发布了的博客看,这次发布聚焦在了三项能力:推理、coding 和 Agentic 任务。
圈里一些朋友反馈看,说它拿下了新一轮的卷王宝座,小编反而觉得 GLM 这次发布没那么简单,有几项新的功能,可以说市面上仅此一家。
这里还是先“省流”地的说几点官方公开的功能亮点,然后就开始实测一波。
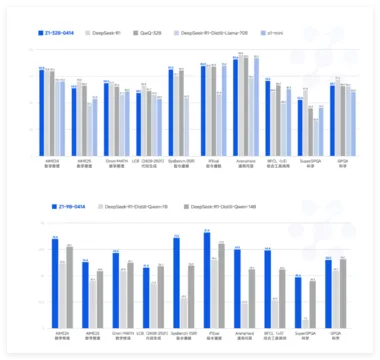
在智能体任务基准测试中,GLM 4.5 拿下了媲美 Claude 4 Sonnet 相媲美的成绩。尤其在函数调用方面,超过了 K2 和 Qwen3,登顶第一。
此外,全栈开发能力也非常强悍,开发环境中的交互能力也拿到了第一。
第三点,GLM 4.5 自带的 AI PPT 功能非常与众不同,可以结合 HTML 代码和图像搜索插件,逐页制作演示文稿,设计感碾压市面上的产品。
先说Highlight
对于大模型侧而言,智谱也是一个 AGI 的忠实拥趸。这次的 GLM 4.5,这次的重点是治理于将大模型的研发往前推进一步:解决真实世界中的实际问题。
 图片
图片
具体思路就是:
我们现在有很多模型,有的擅长写代码,有的擅长数学,有的擅长推理,却没有一个能在所有任务中都做到最优表现。
GLM-4.5 正是在努力解决这个问题:统一多种能力于一体。基于此,智谱团队围绕这个命题,将 GLM-4.5 与 OpenAI、Anthropic、Google DeepMind、xAI、阿里巴巴、Moonshot 和 DeepSeek 的多个模型进行对比,在12个基准测试中涵盖:
- Agentic(智能体类任务)3项
- Reasoning(推理任务)7项
- Coding(编程任务)2项
最后做了整体评估。综测结果显示:
1、工具调用成功率登顶:GLM-4.5 达到 90.6%,超越 Claude-Sonnet(89.5%)、Kimi K2(86.2%)和 Qwen3-Coder(77.1%)。
2、GLM-4.5 在 命令行模拟任务 Terminal-Bench 中拿下第一,展示其在开发环境中具备一定交互式控制能力。
3、在 SWE-bench 是编程实战测试中,GLM-4.5 与 Claude Sonnet 不分伯仲,显著领先 GPT-4.1。
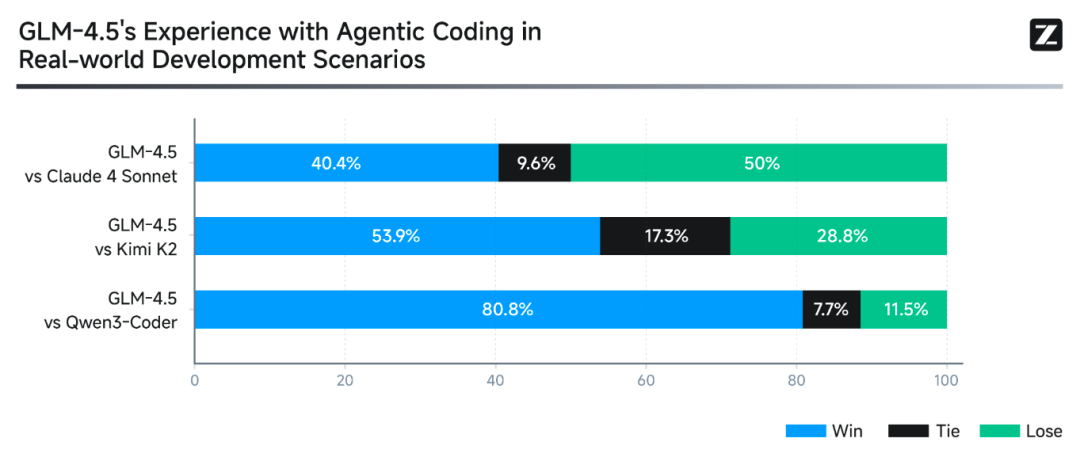
4、Agentic Coding 胜率数据:GLM-4.5 对比 Kimi K2 的 52 项任务胜率为 53.9%,对 Qwen3-Coder 胜率为 80.8%,表现强势。
上面,这一堆数字可能大家现在都免疫了。所以小编在实测了之后,总结了下 GLM 4.5 的亮点功能。大家不妨一看:
- 支持多种工具协作开发:可无缝对接 Claude Code、RooCode、CodeGeex 等插件,实现端到端开发。
- 全栈开发能力强:从前端页面、美观 UI 到后端部署,GLM-4.5 生成的界面功能性与美学兼顾,符合人类审美。
- PPT / 海报生成能力强:GLM-4.5 结合 HTML 代码和图像搜索插件,可以生成带有设计感的完整演示文稿。
- 多轮交互式开发:提供基础项目骨架后,用户只需“加需求”,模型就能自动拓展功能并调试。
实测效果究竟如何?
先说一个实测感受,就是 GLM 4.5 执行任务是真慢,但慢的理由是值得的。
因为它真的要比其他市面上的大模型,可以把我们实际工作生活中的复杂任务做出非常 amazing 效果。
出于篇幅关系,小编做了两个能力方面的用例实战。
一个是全栈开发能力方面。因为小编看到一些官网上举的一些例子:赛博功德计数器、梦幻三消小游戏什么的,感觉有些太幼稚了。
 图片
图片
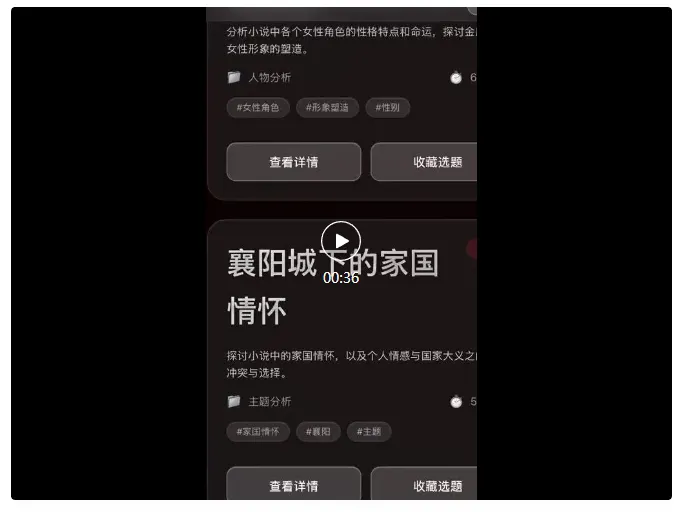
所以索性还是围绕小编目前筹划的播客站点,想了一个测试题目:
帮我设计一个射雕三部曲的播客选题的站点,要求:
1、界面是金庸武侠风格
2、背景有羽毛缓慢飘动
3、自行发挥各个板块
然后,GLM 4.5 就开始干活了,思考过程非常清晰:先搞清楚用户的意图目的,并根据我的要求,拆解规划了自己要完成的任务:
 图片
图片
非常与众不同的是,GLM 4.5 给出了非常系统的项目设计,逐项任务进行拆解,进而逐项实现,没想任务之间的划分可以说做到了相当程度的解耦,完成一项之后,就在待办事项中划掉一项。
可以说,已经非常 Agentic 了。
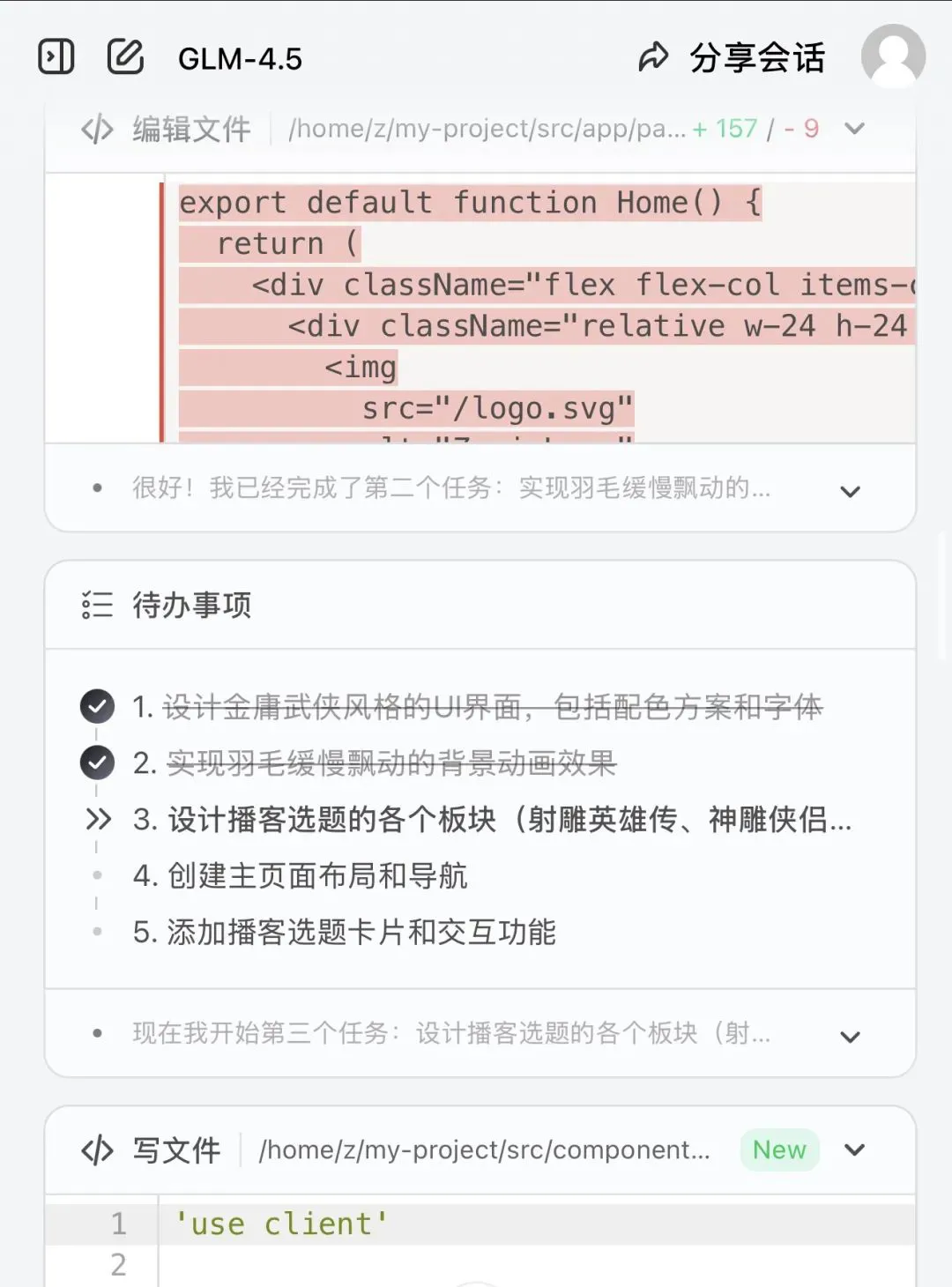 图片
图片
所以说,具备这种思路的大模型,目前小编是第一次看到,惊艳到了。
此处略去各种感叹号,直接让大家看下最后的效果。
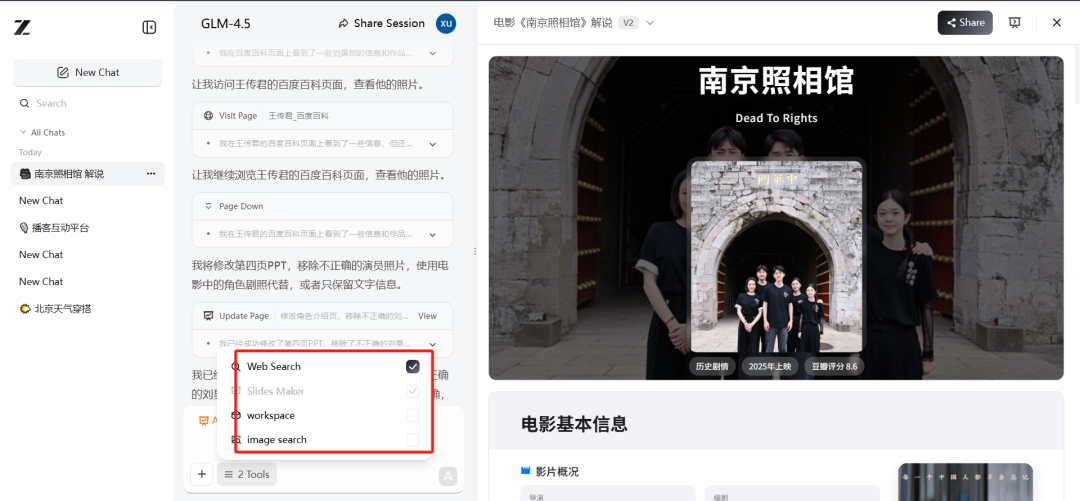
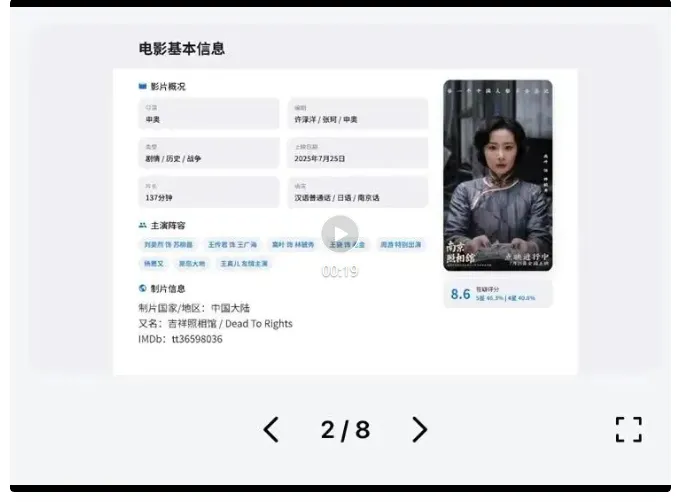
第二个实测的例子,更然小编折服了。最近小编一直想看《南京照相馆》,题材很应景,主演们:刘昊然、王传君等也都是小编一直感冒的演员。只是一直没有时间去看,所以干脆让 GLM 4.5 帮我先看看影评,做个解说PPT介绍一下了。
 图片
图片
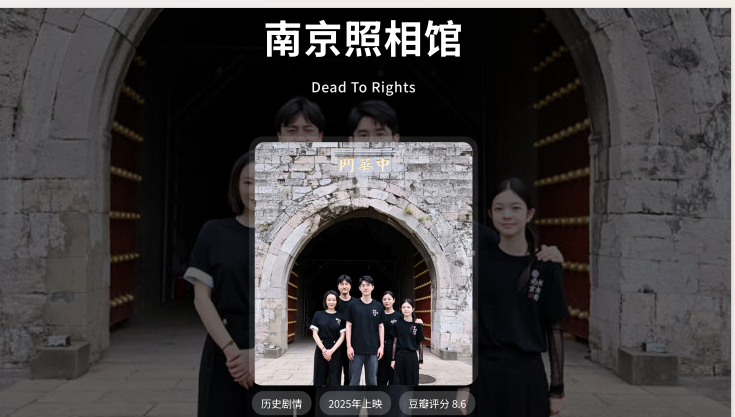
结果等了十几分钟后,PPT的界面效果出来之后,小编的瞳孔开始地震了。
设计感的确很给力,而且每个画面的布局、图文之间的混排,非常人性。
当刘昊然那张 C 位照片的透明封面出来之后,小编心想:这 AI PPT 界真的要变天了。
 图片
图片
原理上,GLM 4.5 调用了四个工具来完成 AI PPT 的任务,Web Search、Slides Maker、WorkSpace、Image Search。
通过网页代码和图像搜索结合的方式,可以说是准确度和设计感已经超过小编本人的 PPT 水平了。
最后可以直接在 Chat 界面预览,也可以导出 PDF 文件。给大家看看效果。
小编反正是彻底爱上了。虽然生成速度有些慢!
GLM 4.5 背后的技术公开
这次,智谱也 open 了这一次升级背后的 Trick。
首先在架构方面,更深的模型和更多的注意力头可以带来更佳的推理能力。
GLM-4.5 系列中,智谱团队在 MoE 层中使用了 无损负载均衡路由和 Sigmoid 门控机制。
智谱团队基于实验发现,更深的模型具有更强的推理能力。
所以,与 DeepSeek-V3 和 Kimi K2 的策略不同,他们选择减少模型宽度(即隐藏层维度与被路由专家数量),增加模型深度(即层数)。
此外,在自注意力部分,GLM 4.5 还引入了 Grouped-Query Attention,并结合了 部分位置旋转编码(Partial RoPE)。同时,团队还将注意力头的数量提升到常规的 2.5 倍(即在 5120 的隐藏维度下使用 96 个头)。
虽然直觉上注意力头数量的提升并未降低训练损失(loss),但研究人员观察到它显著提升了模型在 MMLU、BBH 等推理类基准测试中的表现。
优化器方面,智谱团队采用了 Muon 优化器,具有更快的收敛速度与更强的超大批次容忍能力。
另外,在 GLM-4.5 和 GLM-4.5-Air 中,我们都加入了 MTP(多 Token 预测)层,以在推理阶段支持推测式解码。
其次,数据方面,GLM 4.5 采用了多阶段训练的方法:
- 首先在 15 万亿 token 的通用预训练语料上训练;
- 随后追加训练 7 万亿 token 的代码与推理类语料;
- 在预训练之后,引入额外的任务增强阶段,用以提升模型在关键下游任务中的表现。
官方博客中介绍,这些阶段主要使用中等规模的领域专用数据集,包括指令调优数据。
第三,强化学习阶段,智谱还开发了一套大模型强化学习框架:slime。目的是使RL训练阶段具备出色的灵活性、效率与可扩展性。
slime 的核心创新包括:
1、灵活的混合训练架构。对于传统推理类任务而言,可同时支持同步协同训练;对于智能体类任务优化而言,可支持解耦异步训练模式。
值得注意的是,在异步模式下,训练与数据生成完全解耦,显著提高 GPU 利用率,避免算力空转。
2、智能体友好的解耦式设计。智能体训练常因环境交互延迟长、分布不稳定而拖慢训练。
slime 可将 rollout(环境交互)与训练逻辑彻底分离、并行处理,有效突破性能瓶颈。
3、 混合精度加速数据生成。使用高效的 FP8 格式 快速生成数据,同时在训练主循环中保留 BF16 以确保稳定性。这样可以大幅提升生成速率,同时保障训练质量。
通过这些设计,slime 能无缝集成多种 agent 框架、支持多样任务,并高效管理长时间跨度的训练流程。
智谱GLM4.5是如何做到统一多项能力的?
重点技巧来了,正如上文所说, GLM-4.5 这款面模型追求的是让一款模型同时具备优秀的推理、编程、通用工具调用的能力,智谱在开源模型的同时,把这项核心技术也第一时间公开了。
据悉,GLM 4.5 整合了下面几项能力:
- 来自 GLM-4-0414 的通用能力
- 来自 GLM-Z1 的推理能力
- 进一步强化了智能体能力,包括:
智能体编程(Agentic Coding)
深度搜索(Deep Search)
通用工具调用能力(General Tool-Using)
而这个整合阶段则发生在 RL 阶段。他们把流程也公开了:
第一步:有监督微调。基于精选的推理数据与合成的智能体场景,进行微调。
第二步:专用 RL 训练阶段。
- 对于推理任务,使用64K 长上下文输入,结合 难度分级课程表(curriculum),效果优于传统逐步调度。
动态温度采样,兼顾探索与收敛
自适应梯度裁剪,用于 STEM 类问题的策略稳定更新
并引入两项改进技术:
- 对于智能体任务,研究人员专注于两个可验证任务:其一是开发可扩展的 QA 生成策略,其二是编程任务则通过真实代码执行反馈驱动强化学习更新。其中专供的典型场景包括:
基于人类参与抽取网页内容
结合内容遮蔽技术合成搜索类问答
信息检索型问答(QA)
软件工程任务(SWE)
此外,GLM 4.5 团队指出,尽管 RL 阶段针对的是有限任务,但其带来的提升可以迁移到通用能力,如 tool-use。
最后,通过专家蒸馏,就可以把这些专业能力集成进主模型,赋予 GLM-4.5 全面的智能体能力。
写在最后
在短短几周内,最佳开源模型的桂冠频繁上新,先是 Kimi-K2 ,然后是 Qwen3,而今天,GLM 4.5 继续刷新榜单,拿下 Agentic 时代的 开源 SOTA!
智谱,总在每一波大的大模型发展节奏中,找到自己的发展路径。这一次 Agentic 时代,再一次用独有的实力证明:OpenAI 不是唯一正确,做通用的 AGI,智谱团队有着非常自信的发展路径,比如这次 AI PPT 的功能,就与其他产品的路线非常不同;再比如 MoE 架构方面的优化,新的强化学习阶段的统一多项专有能力的过程,也是非常厉害的。
好了,大家也可以去试试了,重申:模型是开源免费的,但API是要钱的。
尝鲜地址:https://chat.z.ai/