梦晨 发自 凹非寺量子位 | 公众号 QbitAI
GPU编程变天了。
英伟达发布最新版CUDA 13.1,官方直接定性:这是自2006年诞生以来最大的进步。
核心变化是推出全新的CUDA Tile编程模型,让开发者可以用Python写GPU内核,15行代码就能达到200行CUDA C++代码的性能。

消息一出,芯片界传奇人物Jim Keller立即发问:
英伟达是不是亲手终结了CUDA的“护城河”?如果英伟达也转向Tile模型,AI内核将更容易移植到其他硬件上。
Jim Keller参与设计过AMD Zen架构、苹果A系列芯片、特斯拉自动驾驶芯片的”硅仙人”,他的判断在行业里相当有分量。
那么问题来了:CUDA这次到底改了什么?为什么会被认为是”自毁长城”?
要理解这次更新的意义,得先回顾一下传统CUDA编程有多折磨人。
过去20年,CUDA一直采用SIMT(单指令多线程)模型,开发者写代码时,需要手动管理线程索引、线程块、共享内存布局、线程同步,每一个细节都要自己操心。
想要充分利用GPU性能,特别是用上Tensor Core这类专用模块,更是需要深厚的经验积累。
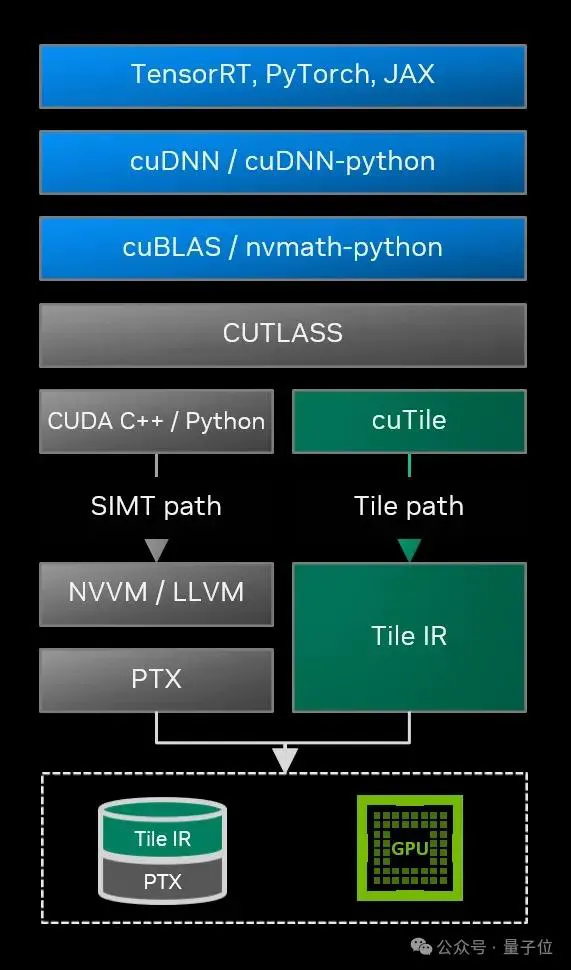
CUDA Tile彻底改变了这套玩法:
开发者不再需要逐线程地编写执行路径,而是把数据组织成Tile(瓦片),然后定义在这些Tile上执行什么运算。至于怎么把这些运算映射到GPU的线程、Warp和Tensor Core上,编译器和运行时会自动搞定。
就好像NumPy之于Python。

英伟达为此构建了两个核心组件:
CUDA Tile IR是一套全新的虚拟指令集,它在高级语言和硬件之间加了一层抽象,确保基于Tile编写的代码能在不同代际的GPU上运行,从当前的Blackwell到未来的架构都能兼容。
cuTile Python则是面向开发者的接口,直接用Python写GPU内核,门槛一下子从“HPC专家“降到了”会写Python的数据科学家都可以干。
另外,这次更新还带来了一系列面向Blackwell的性能优化:
- cuBLAS引入了FP64和FP32精度在Tensor Core上的仿真功能
- 新增的Grouped GEMM API在MoE(混合专家模型)场景下能实现高达4倍加速
- cuSOLVER的批处理特征分解在Blackwell RTX PRO 6000上相比L40S实现了约2倍的性能提升
- 开发者工具Nsight Compute新增了对CUDA Tile内核的性能分析支持,可以把性能指标直接映射回cuTile Python源代码。
目前CUDA Tile仅支持Blackwell架构(计算能力10.x和12.x),开发重点集中在AI算法上。英伟达表示未来会扩展到更多架构,并推出C++实现。
那么Jim Keller为什么说英伟达可能”终结了自己的护城河”?
关键就在于Tile编程模型不是英伟达独有的。AMD、Intel以及其他AI芯片厂商的硬件,在底层架构上同样可以支持基于Tile的编程抽象。
过去CUDA难以移植,很大程度上是因为SIMT模型与英伟达硬件深度绑定,开发者要针对具体的GPU架构手写优化代码。这些代码换到别家硬件上,要么跑不了,要么性能大打折扣。
但Tile模型天然具有更高的抽象层次。当开发者习惯了“只管定义Tile运算,硬件细节交给编译器”这种思维方式后,理论上同一套算法逻辑更容易适配到其他支持Tile编程的硬件上。
正如Jim Keller所说:”AI内核将更容易移植。”
不过英伟达也考虑了后手,CUDA Tile IR提供了跨代兼容性,但这种兼容性是建立在CUDA平台之上的。
开发者写的代码确实更容易移植了,但移植的目标是英伟达自家的不同代GPU,而非竞争对手的硬件。
从这个角度看,CUDA代码可以从Blackwell无缝迁移到下一代英伟达GPU,但要迁移到AMD或Intel的平台上,依然需要重写。
不管护城河是加深还是削弱,有一点是确定的:GPU编程的门槛确实在大幅降低。
过去能熟练驾驭CUDA的开发者是稀缺资源,会写Python的人一抓一大把,但能把代码优化到跑满Tensor Core的专家寥寥无几。
CUDA Tile和cuTile Python打通了这个瓶颈。英伟达在开发者博客中提到,一个15行的Python内核性能可以媲美200行手动优化的CUDA C++代码。
大量数据科学家和AI研究者从此可以直接上手写高性能GPU代码,不用再等HPC专家来帮忙优化。
参考链接:[1]https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware[2]https://x.com/jimkxa/status/1997732089480024498