科技媒体 marktechpost 昨日(6 月 4 日)发布博文,报道称英伟达推出 ProRL 强化学习方法,并开发出全球最佳的 1.5B 参数推理模型 Nemotron-Research-Reasoning-Qwen-1.5B。
背景简介
推理模型是一种专门的人工智能系统,通过详细的长链推理(Chain of Thought,CoT)过程生成最终答案。
强化学习(Reinforcement Learning,RL)在训练中扮演非常重要的角色,DeepSeek 和 Kimi 等团队采用可验证奖励的强化学习(RLVR)方法,推广了 GRPO、Mirror Descent 和 RLOO 等算法。
然而,研究者仍在争论强化学习是否真正提升大型语言模型(LLM)的推理能力。现有数据表明,RLVR 在 pass@k 指标上未能显著优于基础模型,显示推理能力扩展受限。
此外,当前研究多集中于数学等特定领域,模型常被过度训练,限制了探索潜力;同时,训练步数通常仅数百步,未能让模型充分发展新能力。
ProRL 方法的突破与应用
英伟达研究团队为解决上述问题,推出 ProRL 方法,延长强化学习训练时间至超过 2000 步,并将训练数据扩展至数学、编程、STEM、逻辑谜题和指令遵循等多个领域,涵盖 13.6 万个样本。
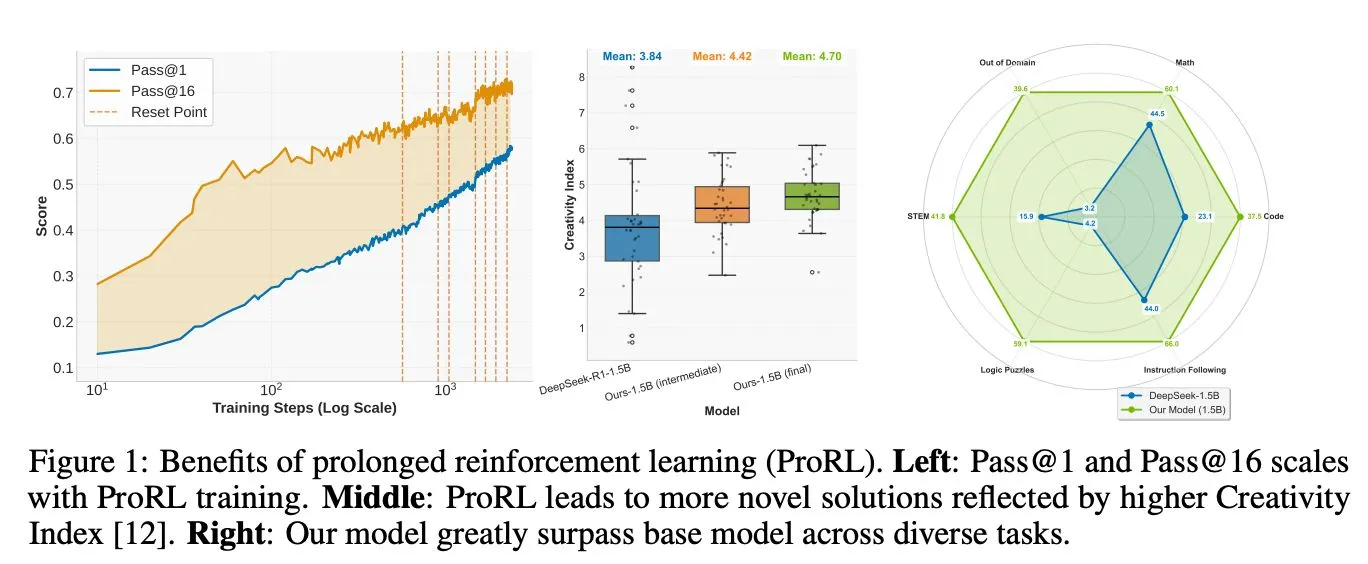
他们采用 verl 框架和改进的 GRPO 方法,开发出 Nemotron-Research-Reasoning-Qwen-1.5B 模型。
这是全球最佳的 1.5B 参数推理模型,在多项基准测试中超越基础模型 DeepSeek-R1-1.5B,甚至优于更大的 DeepSeek-R1-7B。
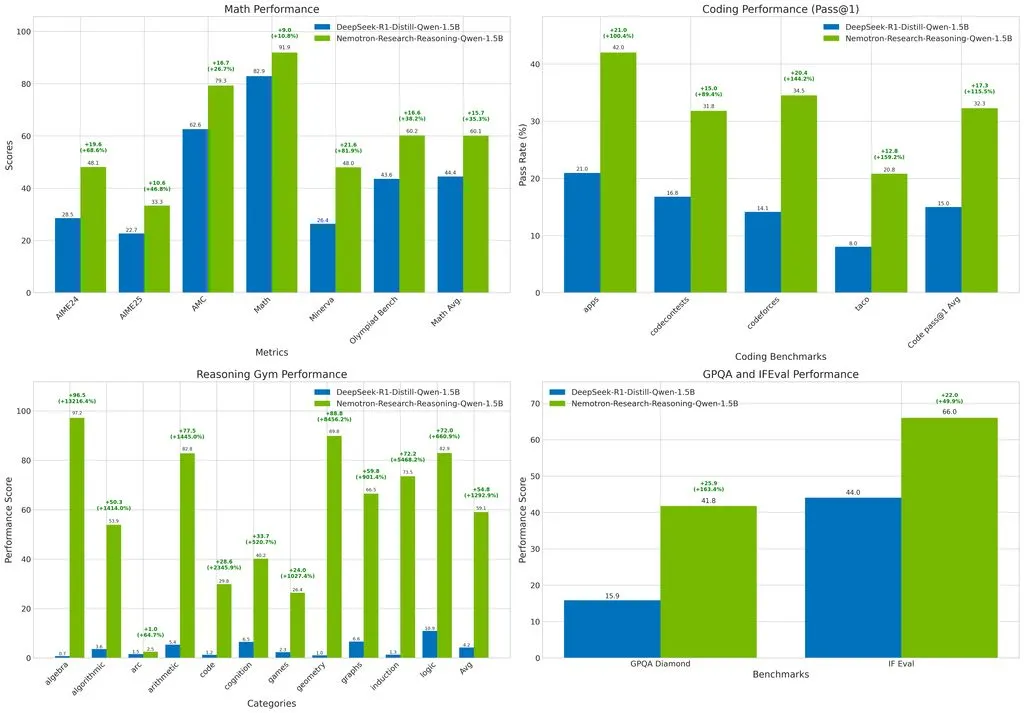
测试结果显示,该模型在数学领域平均提升 15.7%,编程任务 pass@1 准确率提升 14.4%,STEM 推理和指令遵循分别提升 25.9% 和 22.0%,逻辑谜题奖励值提升 54.8%,展现出强大的泛化能力。
AI在线附上参考地址
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
huggingface


