
请想象……
一个 AI—— 它要完整看完一场几十分钟的世界杯决赛,不只是数球门数,更要跨越上百个镜头的线索、情绪、战术细节,甚至要像人一样推断:谁会赢点球大战?

足球比赛预测分析
预测《星际争霸 2》这样的即时战略游戏同样需要考虑许多不同的变量,难度也非常巨大。

星际争霸 2 比赛预测分析
再换个场景:同样是 AI,在一场紧张的德州扑克超级豪客赛上,面对职业牌手的每一次下注、加注、弃牌,能否像一个顶尖牌手一样,推理出对手藏在手里的那两张底牌?

德州扑克比赛猜牌
不只是「看」,还要记住所有公共牌、下注顺序、翻牌后的心理博弈,甚至对手的打法偏好 —— 然后在最后一张河牌翻开时,做出最优推断。
再换一个小游戏:三只杯子,一颗小球。人盯着屏幕都可能跟丢,AI 能不能像魔术师一样,在上百帧交换里牢牢盯住那颗小球的位置?

移动杯子猜测小球位置
这背后,AI 需要的不只是「识别」,更是跨时域、跨模态的推理、记忆和博弈洞察。
这,正是 Long-RL 想要解决的挑战:如何让大模型在面对长视频和复杂策略推理时,不只是看见,更能理解和推演。
今天,视觉语言模型(VLM)和大语言模型(LLM)越来越强,但现实里,当它们需要处理小时级视频、多模态输入、需要长时一致性和上下文推理时,传统的开源方案往往力不从心。
要跑长序列?显存炸了。
要多模态?上下游兼容难。
要 RL 高效?采样慢,回报低。
针对这些难题,英伟达近日联合 MIT、香港大学、UC Berkeley 重磅推出 Long-RL,其能提升 RL 训练数据长度上限,让训练速度翻倍。

论文:Scaling RL to Long Videos
项目地址:https://github.com/NVlabs/Long-RL
论文链接:https://arxiv.org/abs/2507.07966
 简单来说,Long-RL 是一个真正面向长序列推理和多模态强化学习的全栈训练框架。支持小时级长视频 RL:单机可稳定训练 3600 帧(256k tokens)。
简单来说,Long-RL 是一个真正面向长序列推理和多模态强化学习的全栈训练框架。支持小时级长视频 RL:单机可稳定训练 3600 帧(256k tokens)。
Long-RL 的核心是 MR-SP 并行框架
MR-SP 的全称是 Multi-modal Reinforcement Sequence Parallelism,即多模态强化序列并行,可在不同帧数下显著降低长视频推理的训练耗时和显存:启用 MR-SP 后,训练速度提升可达 2.1×,而传统方案会因显存不足直接 OOM。
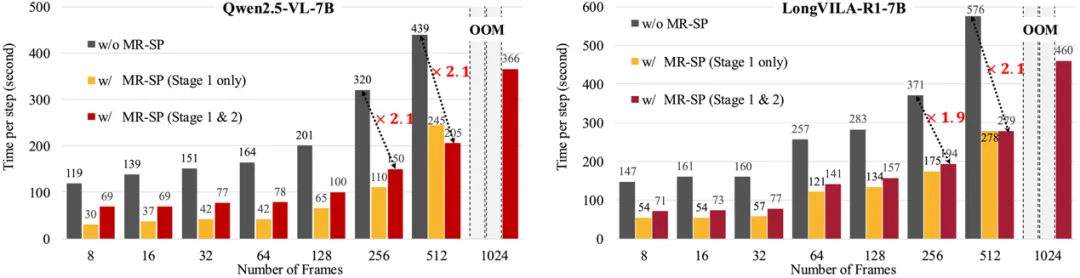
那么,这是如何做到的呢?具体来说,MR-SP 分为两个阶段。
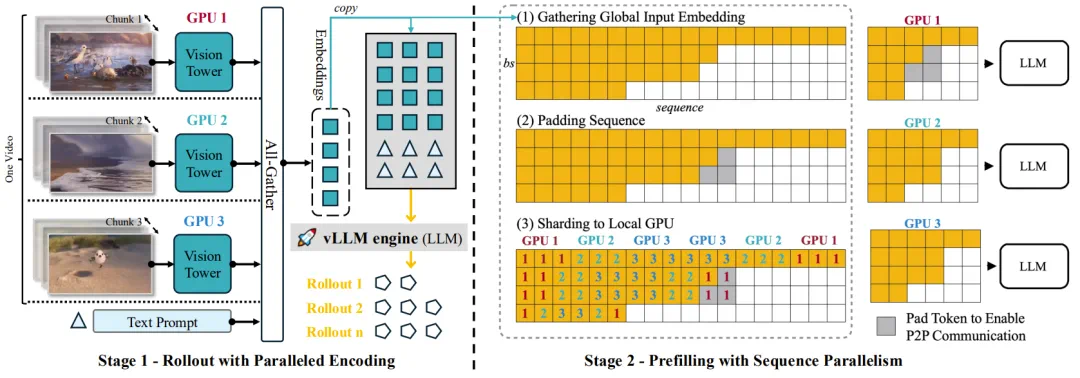
Multi-modal Reinforcement Sequence Parallel (MR-SP) 系统
其中,第 1 阶段是使用并行编码的 Rollout。
为了高效地支持长视频强化学习,该团队在视频编码阶段采用了序列并行 (SP) 机制。
如上图左所示,输入视频帧首先会被均匀地分配到多台 GPU(例如,GPU 1 至 GPU 3)上,每台 GPU 都配备了各自的视觉塔(vision tower)。每台 GPU 独立处理视频的一部分,并且仅对其中一部分帧进行编码。然后,生成的视频嵌入将通过 all-gather 操作与文本嵌入进行聚合,如图中 All-Gather 箭头所示。此策略可分散编码工作负载,使系统能够利用更多 GPU 来处理更长的视频,同时避免 GPU 内存溢出的风险。
并行编码方案可确保视觉塔的均衡利用,并实现可扩展的长视频处理,而这在单台设备上是无法实现的。
视频嵌入在被全局收集后,将在整个强化学习流程中被下游重复使用。
如上图所示,收集到的嵌入在多次 rollout 过程中可重复使用,且无需重新计算。例如,在每个训练步骤中,通常会执行 8 到 16 次 rollout。如果不进行回收,同一视频每一步都需要重新编码数十次,这会严重影响训练速度。通过缓存和重用收集到的嵌入,MR-SP 可消除这种冗余,并显著加快训练速度。
第 2 阶段则是使用序列并行进行预填充。
对于每次 rollout,参考模型和策略模型都需要在强化学习中对长视频进行计算密集型预填充。通过复用第 1 阶段收集到的嵌入,可使用序列并行在各个设备之间并行化推理阶段。
如上图右所示,这里的方案是全局收集输入嵌入 —— 这些嵌入首先会被填充到统一长度(Padding Sequence),然后均匀地分配到各台 GPU(Sharding to Local GPU)。
这样一来,每台 GPU 在预填充期间只需处理输入序列的一部分。这种并行性适用于策略和参考模型的预填充。然后,每台 GPU 会在本地计算其 token 切片的 logit,并且并行进行预填充。
Long-RL 也是一个多模态 RL 工具箱
该团队也将 Long-RL 打造成了一个完整的多模态 RL 工具箱,能适配:
多模型:除了 VILA 系列、Qwen/Qwen-VL 系列这些 LLMs/VLMs,也支持 Stable Diffusion、Wan 等生成模型。
多算法:GRPO、DAPO、Reinforce,一行切换。
多模态:不仅文本,视频、音频一起上。

LongVILA-R1
使用 Long-RL,英伟达的这个团队构建了 LongVILA-R1 训练框架。从名字也能看到出来,这个训练框架基于 VILA—— 一个同样来自该公司的视觉-语言模型(VLM),详见论文《VILA: On Pre-training for Visual Language Models》。
训练流程方面,LongVILA-R1 基于 LongVILA 的基础训练流程,然后进一步使用 MM-SP 以通过长 CoT 在长视频理解任务进行 SFT。然后,通过多模态强化序列并行 (MR-SP) 进行强化 scaling 学习。

LongVILA-R1 训练流程
框架上,LongVILA-R1 集成了 MR-SP 来实现可扩展视频帧编码和 LLM 预填充。强化学习采用了基于 vLLM 的引擎,并带有缓存的视频嵌入,并针对 LongVILA rollout 进行了定制。针对准确度和格式的奖励将作为策略优化的引导。

LongVILA-R1 强化学习训练框架
LongVILA-R1 可以说是 Long-RL 的「明星学员」,专门攻克长视频推理这块硬骨头。
总结起来,它的创新点可以用三个关键词概括:
大规模高质量数据 LongVideo-Reason:52K 长视频推理样本,涵盖 Temporal / Goal / Spatial / Plot 四大类推理。
两阶段训练:先用 CoT-SFT 把链式推理打基础,再用 RL 强化泛化,学得更稳更深。
MR-SP 高效并行:多模态长序列并行,特征可复用,一次缓存多次用。
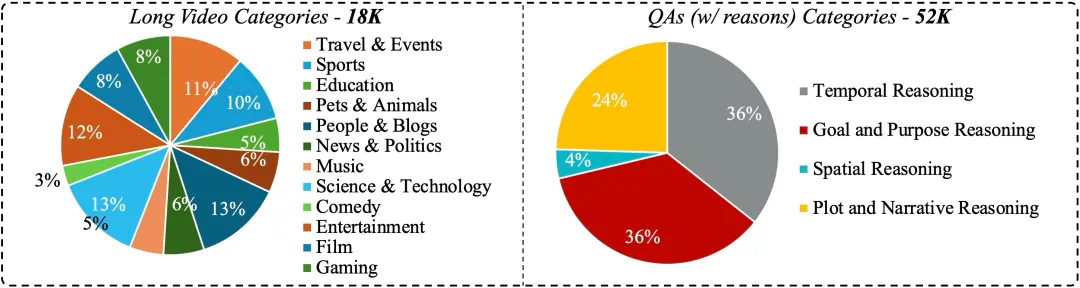
大规模数据集 LongVideo-Reason
效果如何?
在 LongVideo-Reason-eval 这种强推理基准上,随着帧数增加,加入推理显著提高了准确度,并且相比无推理设置优势逐渐扩大。
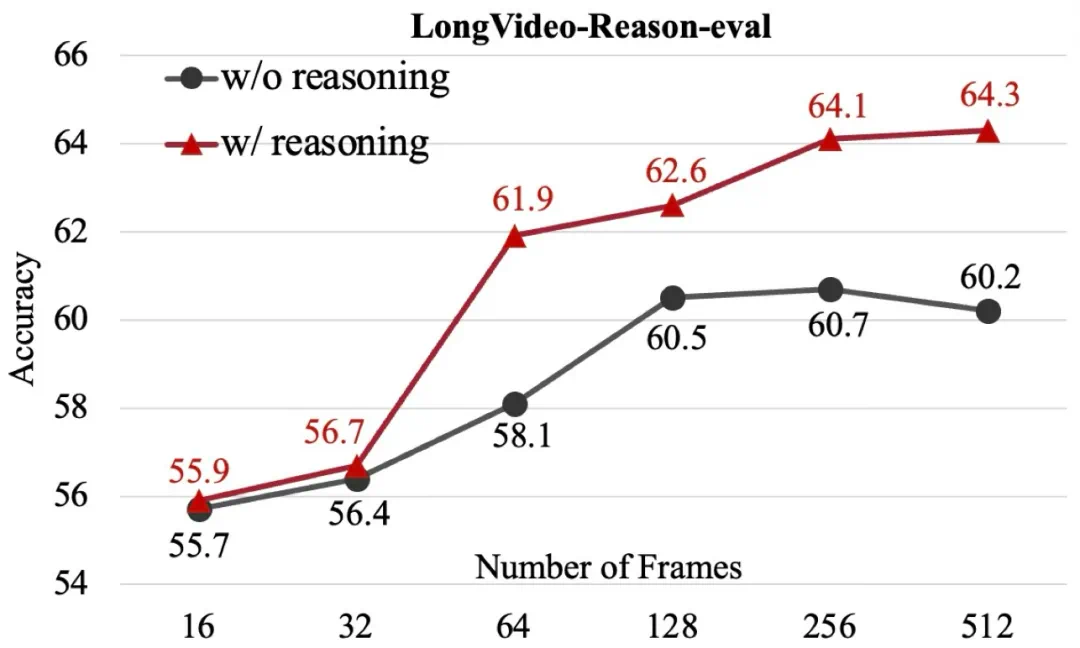
该团队也通过消融实验验证了各组件的有效性。

在真实世界里,无论是看一场完整的足球赛、跟人多轮对话,还是让机器人长时间工作,都需要 AI 能在长时间里保留上下文、持续推理,并根据反馈自我调整。这正是强化学习(RL)擅长的:不断试错、获取回报、做出更优决策。
该团队表示:只有把 RL 和长序列推理结合起来,AI 才可能跨越「一次推理」走向「持续智能」—— 这也是 AGI 的必经之路。
研究团队

陈玉康现任 NVIDIA 研究科学家,于香港中文大学获得博士学位,从事大语言模型(LLM)、视觉语言模型(VLM)、高效深度学习等方面研究。目前已在国际顶级会议和期刊发表论文 30 余篇;多项研究成果在 ICLR、CVPR 等顶级会议上获选口头报告,并在 Google Scholar 上累计引用超过 5,000 次,代表作包括 VoxelNeXt, LongLoRA, LongVILA, Long-RL. 他作为第一作者主导的多个开源项目在 GitHub 上已获得超过 6,000 星标。并在包括 Microsoft COCO、ScanNet 和 nuScenes 等多个国际知名竞赛和榜单中取得冠军或第一名的成绩。

黄炜,香港大学二年级博士生。主要研究方向为轻量化(多模态)大语言模型,神经网络压缩以及高效多模态推理模型训练,在 ICML、ICLR、CVPR 等会议和期刊发表多篇文章。在 NVIDIA 实习期间完成此工作。

陆垚现任 NVIDIA 杰出科学家,UCSD 博士。目前主要研究方向为视觉语言模型和视觉语言动作模型。他是开源视觉语言模型 VILA 系列的负责人。在加入 NVIDIA 之前,他是 Google DeepMind 的研究经理,曾一起领导研发 SayCan, RT-1, RT-2 等具身智能领域的奠基性工作。

韩松是 MIT 电气工程与计算机科学系副教授、NVIDIA 杰出科学家,斯坦福大学博士。他提出了广泛用于高效 AI 计算的「深度压缩」技术,并首创将权重稀疏性引入 AI 芯片的「高效推理引擎」,该成果为 ISCA 50 年历史引用量前五。他的团队致力于将 AI 模型优化、压缩并部署到资源受限设备,提升了大语言模型(LLM)和生成式 AI 在训练和推理阶段的效率,成果已被 NVIDIA TensorRT-LLM 采用。他曾获 ICLR、FPGA、MLSys 最佳论文奖,入选 MIT 科技评论「35 岁以下科技创新 35 人」,并获得 NSF CAREER 奖、IEEE「AI’s 10 to Watch」奖和 Sloan 研究奖。


