银河通用昨日(1 月 9 日)宣布,联合北京智源人工智能研究院(BAAI)及北京大学和香港大学研究人员,发布首个全面泛化的端到端具身抓取基础大模型 GraspVLA。
AI在线注:“具身智能”是指将人工智能融入机器人等物理实体,赋予它们感知、学习和与环境动态交互的能力。

据介绍,GraspVLA 的训练包含预训练和后训练两部分。其中预训练完全基于合成大数据,训练数据达到了有史以来最大的数据体量 —— 十亿帧「视觉-语言-动作」对,掌握泛化闭环抓取能力、达成基础模型。
预训练后,模型可直接 Sim2Real(AI在线注:从模拟到现实)在未见过的、千变万化的真实场景和物体上零样本测试,官方宣称满足大多数产品的需求;而针对特别需求,后训练仅需小样本学习即可迁移基础能力到特定场景,维持高泛化性的同时形成符合产品需求的专业技能。
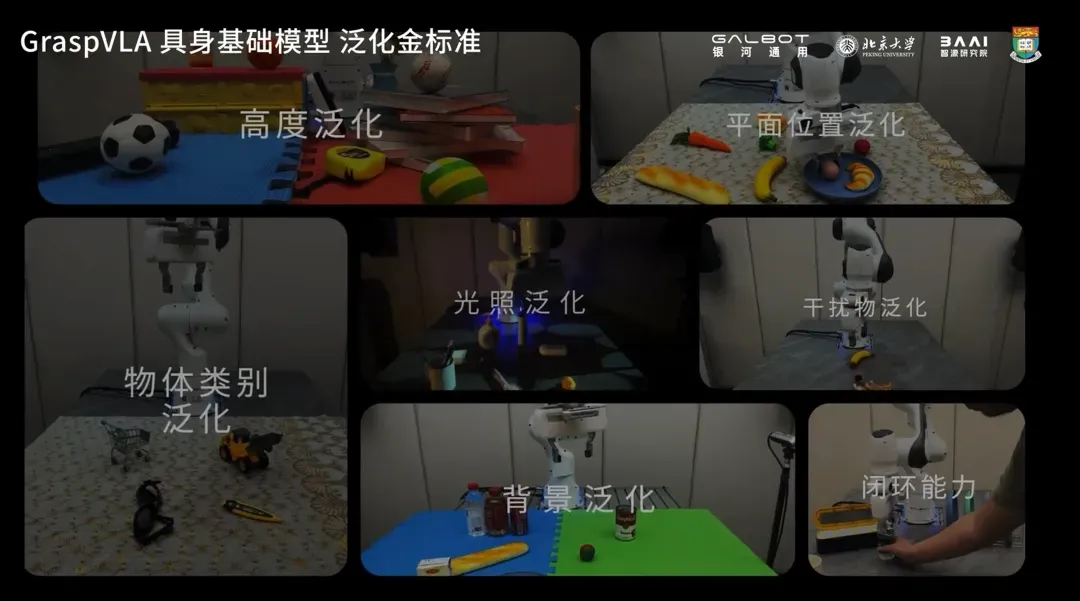
官方公布了 VLA 达到基础模型需满足的七大泛化“金标准”:光照泛化、背景泛化、平面位置泛化、空间高度泛化、动作策略泛化、动态干扰泛化、物体类别泛化。









