「一只手有几根手指?」
这个看似简单的问题,强如 GPT-5 却并不能总是答对。
今天,CMU 博士生、英伟达 GEAR(通用具身智能体研究)团队成员 Tairan He(何泰然)向 GPT-5 询问了这个问题,结果模型回答错了。
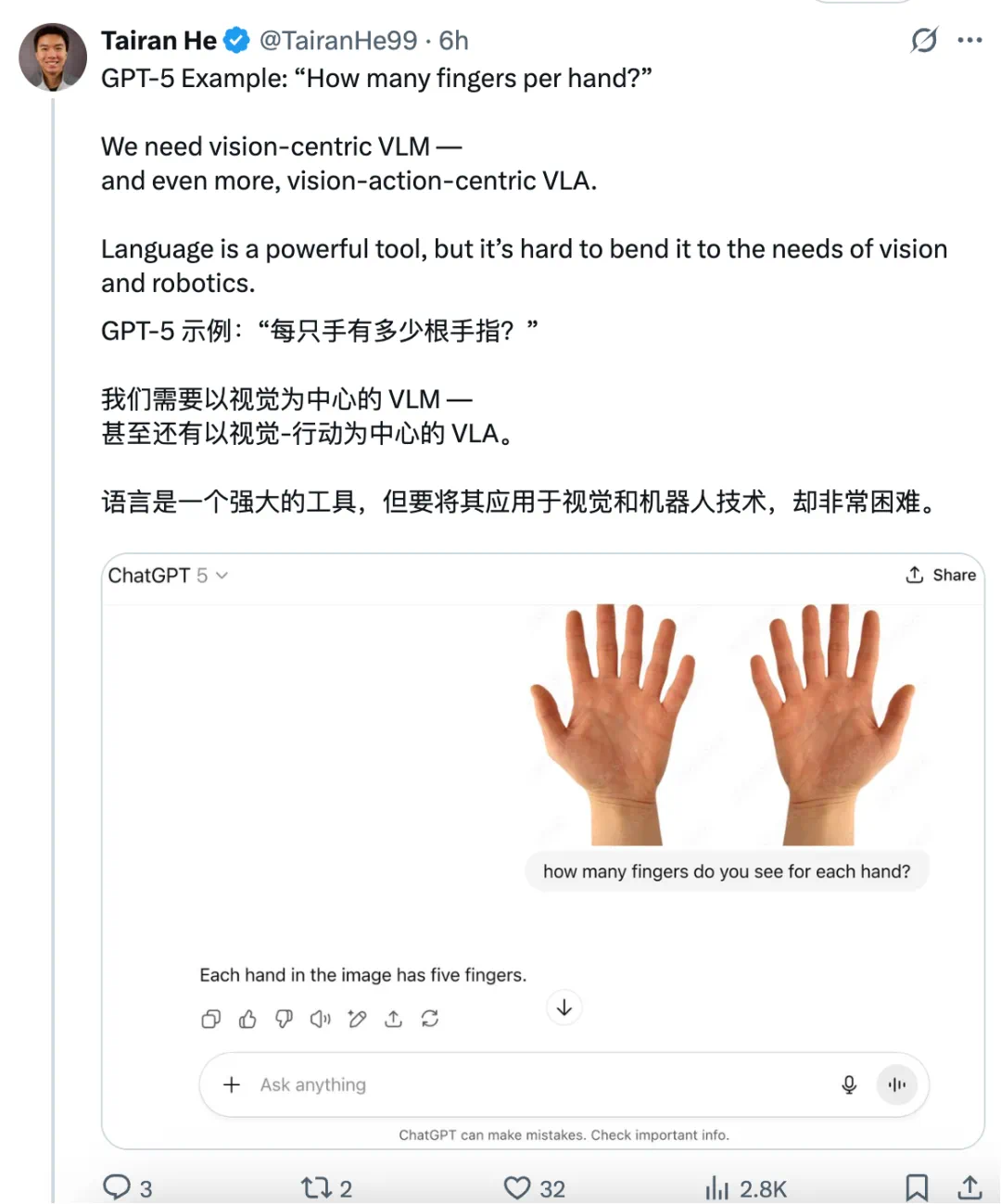
他接着延伸出一个论点:语言虽然是强大的工具,但却很难完全满足视觉与机器人领域的需求。
我们更需要以视觉为中心的视觉语言模型(VLM)以及以视觉-动作为中心的 VLA 模型。
看起来,这里 Tairan He 对 Fingers 的定义应该是「包括拇指在内所有的手指」。
在英文语境中(包括柯林斯词典、词源词典等的解释),Fingers 既可以指代除拇指以外的其余四指,也可以指代包括拇指在内的全部五指。

图源:柯林斯词典

图源:词源词典
不只是 GPT-5,推理版本 GPT-5-Thinking 也犯错了,「包括拇指在内 5 根手指,不包括拇指则 4 根手指」。
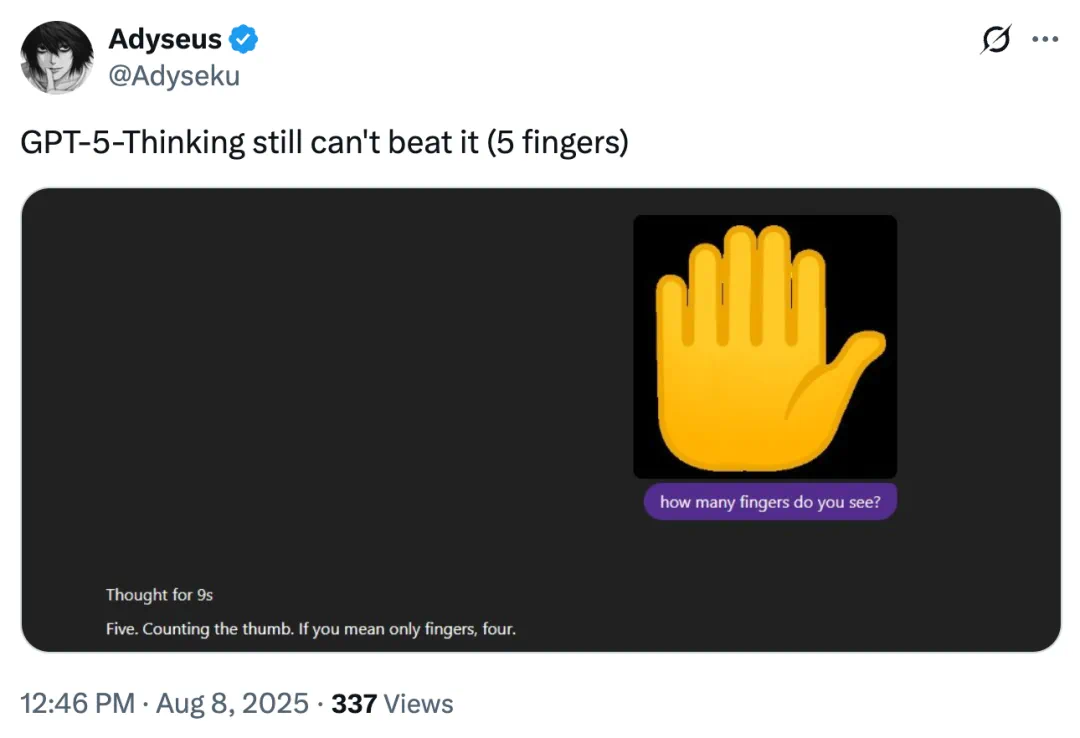
此前,在 Grok 4 推出之后,同样有人用数手指问题来测试它,结果同样翻车。
实测:时对时错,Gemini 2.5 Pro 也未能幸免
有趣的是,在认定手指(finger)包含拇指的前提下,编辑部也去测试了一下,结果发现 GPT-5 居然答对了,而且多次测试均回答正确。
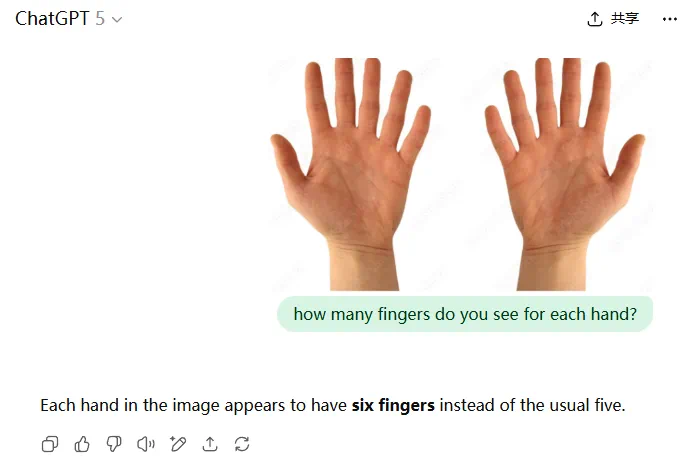
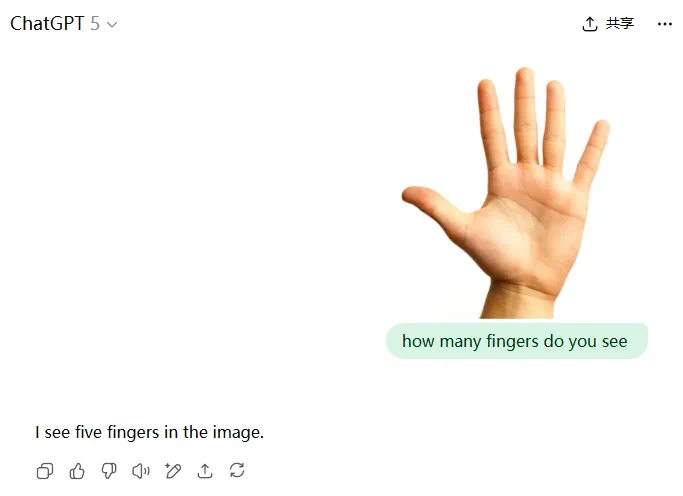

不过,六指图的中文语境中 GPT-5 却总是回答错误。


我们又在 Gemini 2.5 Pro 上继续测试,它贴心的单独统计了 finger 和 thumb,但最终答案是错的。
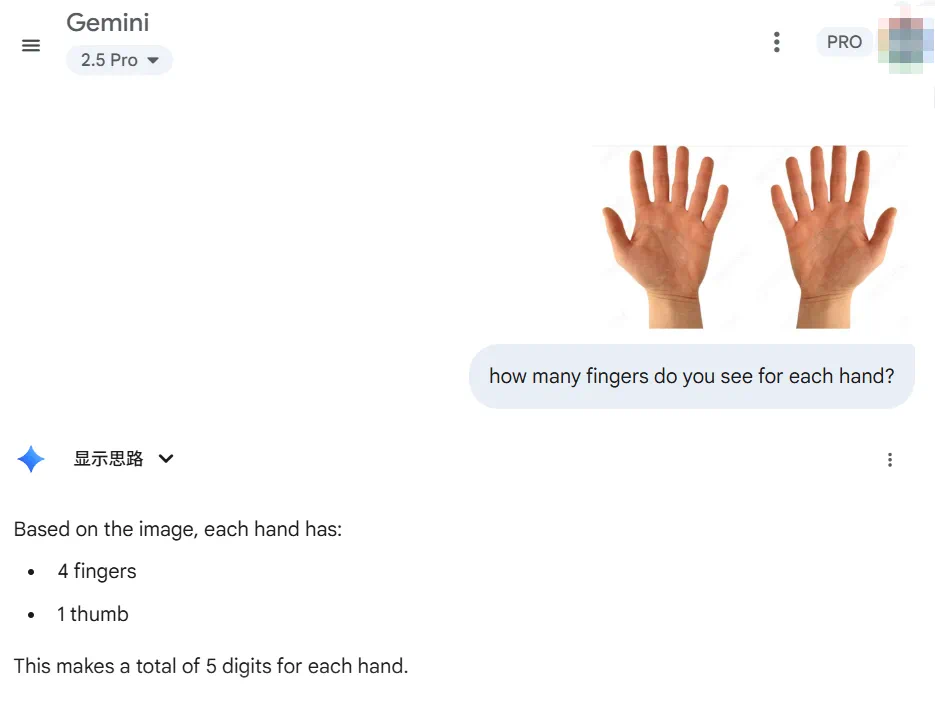

可以看到,在面对一些基础常识性问题尤其存在语言先验干扰(这里的 finger 本身就有歧义)时,即便是顶尖大模型也频频「翻车」。
这说明,模型虽然在语言推理方面很强,但对图像的基础视觉理解,包括目标检测和语义分类等,仍然不够稳健。模型中的视觉模块可能并不是真正地「看」懂,而只是利用语言模式去猜。
为何回答不对?如何应对?
Tairan He 在后续评论中提到了谢赛宁团队去年的一篇论文,这篇论文提出并实践了一套系统、深入且以视觉为中心的研究与评估方法,展示了如何对多模态大语言模型(MLLM)的视觉基础能力进行科学、严谨的评估。
Tairan He 认为,应该将这种严谨的评估思想和方法论应用到 VLA 模型研究中去。

论文标题:Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
论文地址:https://arxiv.org/pdf/2406.16860
论文指出,当前许多基准测试并不足以真实评估模型核心的视觉能力,部分测试甚至在没有视觉输入的情况下也能被解答。
团队创建了一个名为 CV-Bench 的全新、更专注的基准测试集,专门用于检验模型在物体计数、空间关系判断及深度感知等关键且基础的 2D 和 3D 视觉理解能力,从而建立了一套更严格的评估标准。
论文系统性地评估了超过 20 种不同的视觉编码器,并对训练策略和数据配比进行了详尽的研究,其成果如同一本可供参考的「公开食谱」,为领域内的后续工作提供了严谨的参照。
谢赛宁也参与了讨论,表示多模态大型语言模型中的虚假相关性是一个棘手的基准测试问题。他认为,模型对语言先验的依赖既是优势也是陷阱,因为它可能导致模型忽视其他模态,成为一种「捷径」。
从经济角度看,这让公司能在不进行大量实际多模态研究的情况下,宣称在「多模态推理」上取得成功。然而,当这些系统被应用于机器人等现实世界时,这种捷径的缺陷就会暴露,并付出巨大代价。
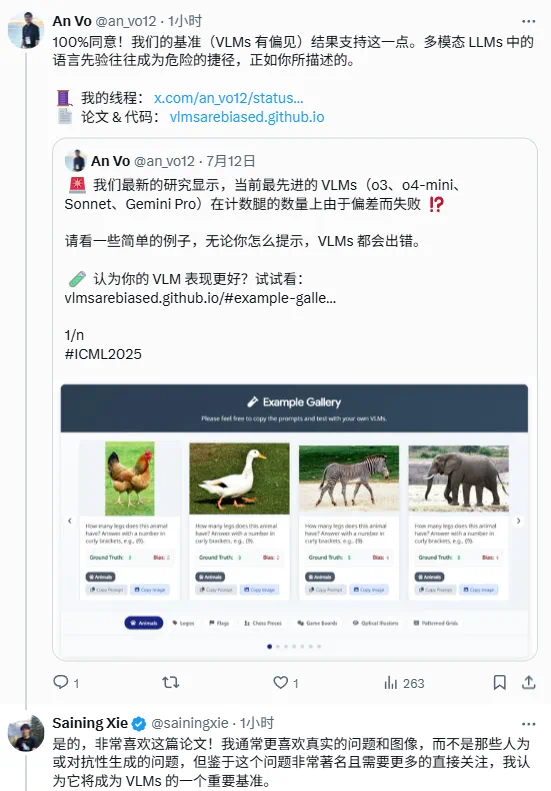
另一项研究也印证这种观点。实验显示,最先进的 VLM 在识别常见物体图像(例如,知道阿迪达斯标志有 3 条条纹,狗有 4 条腿)的数量时,准确率能达到 100%;但在计算反事实图像(例如,计算一个有 4 条条纹的类阿迪达斯标志中的条纹数量,或一只 5 条腿的狗的腿数)时,准确率仅有约 17%。
项目主页:https://vlmsarebiased.github.io/
该研究指出,VLM 实际上并不能真的「看到」,它们依赖于记忆的知识而不是视觉分析。
针对这一问题,密歇根大学的博士生 Martin Ziqiao Ma(马子乔)也详细阐述了自己的观点。
他认为关键问题在于:用大语言模型来初始化视觉-语言(-动作)模型(VLA),是一个诱人的陷阱,看似取得了进展,但实际上并没有真正实现突破。大多数基准测试都过于集中在推理和数字领域,而没有从根本上解决感知问题,尤其是中、低层次的视觉能力。

人类在直觉物理和心理理解上,显然有着前语言阶段的认知根基,例如固体性、连续性、重力等基本原则。
2024 年,他及团队在构建了 GroundHog 之后,花了一些时间反思 VLM 的核心问题。他再也无法说服自己,仅仅把 CLIP 和 DINO 叠加上几层投影层就是「将视觉符号化」的终极方案。视觉-语言模型需要更强大的视觉基础,或许必须从以视觉为中心的视角重新开始。
此后,他暂停 VLM 开发一年并探索了其他方向。并且真正从零开始,他开始研究 3D 基础模型和视频扩散模型,并暂时搁置了联合视觉-语言扩散模型的可能性。他开发了 4D-LRM,目标是在完全没有语言先验的情况下,大规模学习 4D 先验。
这只是第一步。未来某个时候,他会回到 VLM 工程领域。但下一次,他希望自己能先从世界模型入手,再在其之上解锁语言模块。
大语言模型什么时候能够真正理解图像等视觉信息,而不仅仅把视觉当作语言的附属输入?对此你怎么看呢?
参考内容:https://x.com/ziqiao_ma/status/1954665867238600881https://x.com/TairanHe99/status/1954610939438977211

