
编辑丨%
AI 正越来越广泛的应用在各类科研工作里,它对数据的处理能力在加强循证医学方面具有巨大潜力,但由于训练和评估不足而受到限制。
考虑到这种情况,美国 KeiJi AI 牵头了一项研究,提出了 LEADS,这是一种 AI 基础模型,该模型在 633,759 个样本上进行了训练,并于测试中达到了 0.81 的召回率与 0.85 的数据提取准确率。
相关研究内容以「A foundation model for human-AI collaboration in medical literature mining」为题,于 2025 年 9 月 24 日发布在《Nature Communications》。

论文链接:https://www.nature.com/articles/s41467-025-62058-5
高代价的工作还是交给AI
文献挖掘,在当下各类期刊、综述类文章频出的当下,显得越发重要,尤其是系统评价的激增。但是考虑到每年发布的文章数量与系统文件评价所需要的时间与成本,无疑让一切都显得障碍重重。
而诸如 ChatGPT 这样的大语言模型(LLMs),它们作为通用 AI 能够适应各种任务,有些还推出了以理解分析为主要导向的学习功能。这些基础模型通常通过两种主要方法适应医学任务:提示,如情境学习(ICL)、思维链(CoT)和检索增强生成(RAG);以及针对特定任务的微调,如命名实体识别和证据摘要。
但是,研究团队发现,用 GPT-4o 这样的通用模型来挖掘医学文献,常常出现召回率不足、提取信息不准的问题。换句话说,它懂语言,但不够懂「医学文献套路」。所以,大家决定打造一个专门的基础模型,LEADS 就此诞生。
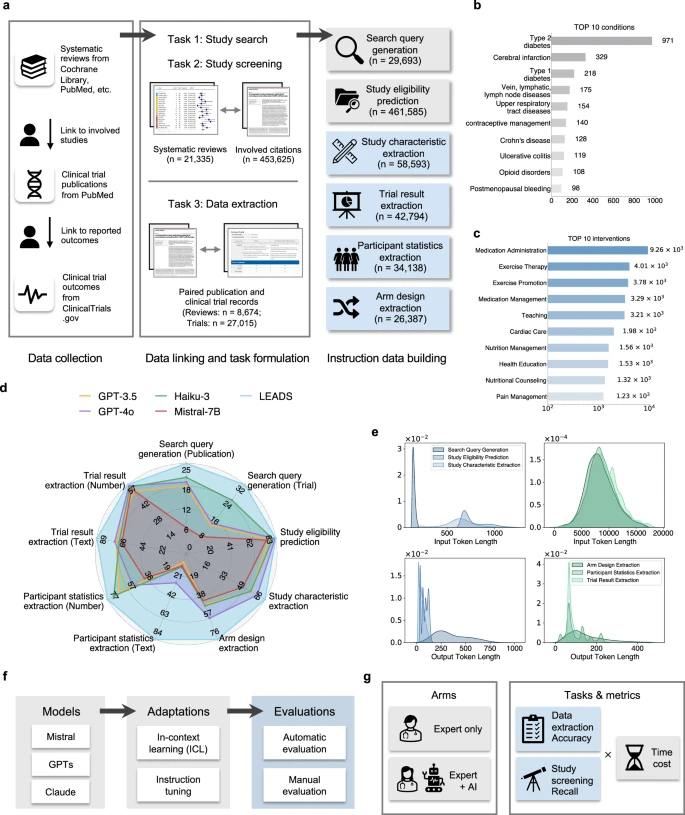
图 1:LEADS 和 LEADSInstruct 概述。
LEADS 基于通用大模型(Mistral-7B),再用大规模医学综述数据集 LEADSInstruct 进行指令微调。该数据集来源于 21,335 篇系统综述、453,625 篇相关文献、27,015 个临床试验记录,覆盖了 633,759 条指令样本。
这种全面的训练策略使 LEADS 能够实现多任务能力,处理灵活的输入请求,并在不进行额外微调的情况下泛化到各种文献主题。在团队的关于广泛综述主题和数千项系统评价的实验中,LEADS 在所有目标任务上均优于 GPT-4o 等尖端通用 LLM。
训练的方式还是很直接的,就像《我爱发明》的经典环节一样:人工组对 AI 组。
测试与人机对比
LEADS 解决了系统评价方法中的三个基本任务:文献检索、引文筛选和数据提取。在出版物和临床试验搜索任务中的性能评估里,LEADS 在两个任务中实现了 24.68 和 32.11 的召回率,分别超过了最佳基线 3.76 和 7.43。
在实际应用中,可以采用集成方法,并使用汇总结果以最大化覆盖范围,团队将此称为 LEADS + 集成。这种方法显著提高了性能,与单次遍历的 LEADS 相比,召回率提高了三到四倍,对于出版物搜索的平均召回率超过 70,对于试验搜索任务超过 65。
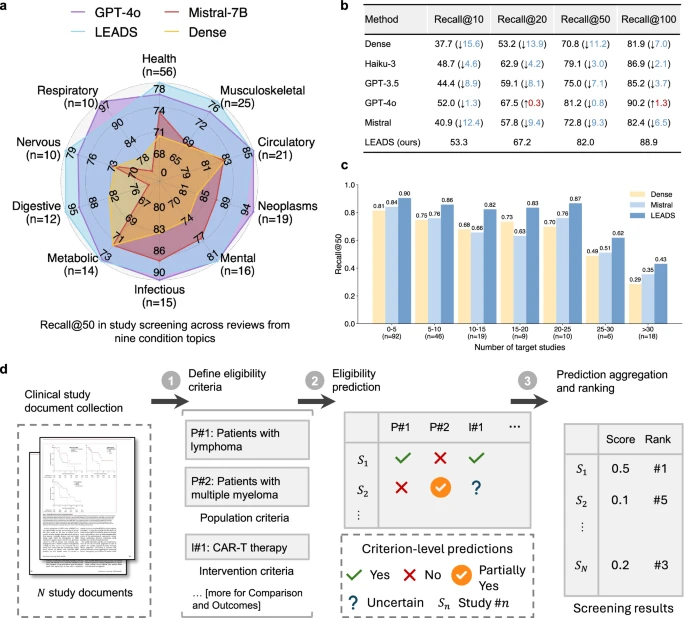
图 2:LEADS 执行文献筛选任务。
除此之外,团队还就文献检索、自动化评估与提取数据简化等方向对模型展开了评估,均表现出了优异的性能。在随后进行的专家+AI 与纯专家组的对比中,这一点会更直观地反映出来。
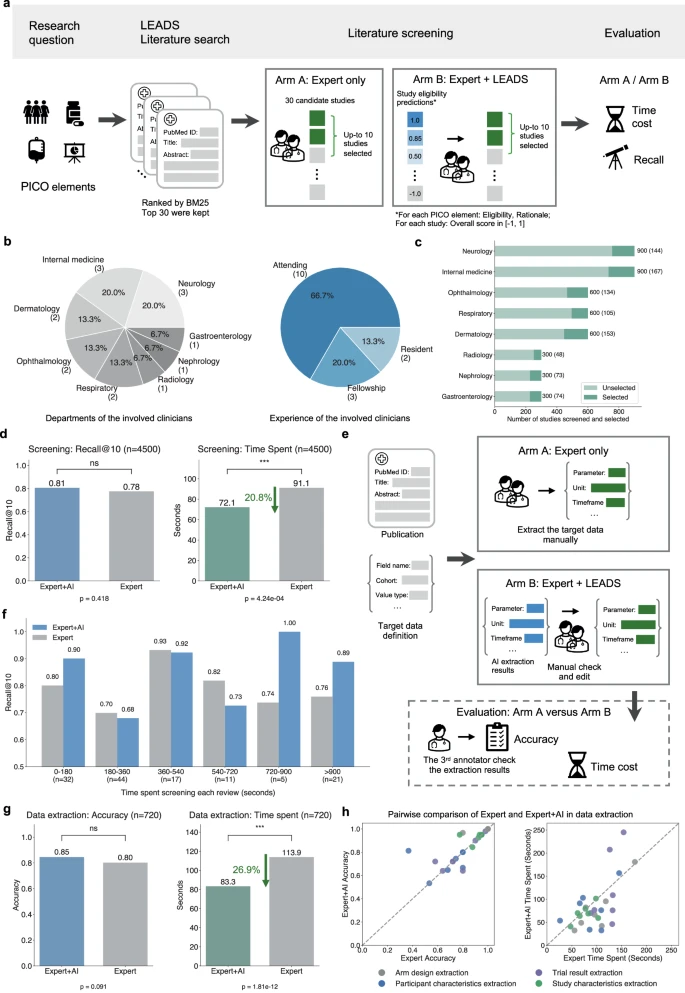
图 3:研究筛选和数据提取的试点用户研究。
在模拟实验中,专家单干的召回率是 0.78,加上 LEADS 提升到 0.81;平均用时从 580 秒降到 449 秒,节省了约 20.8% 的时间。数据提取的准确率由 0.80 提升到 0.85;时间从 113.9 秒降到 83.3 秒,节省了 26.9%。
团队表示:LEADS 排除的几乎所有研究也都被人工审稿人排除,且 LEADS 的 Recall@100 超过 90%,这意味着在实践中,专家可以放心地主要关注前 100 个结果,而不会错过相关研究。
刷文献的好方法
LEADS 的出现,意味着医学研究不再只能靠研究者「手动刨文献」。它不是要取代专家,而是帮他们减轻负担,让结果更快、更准。凭借其设计,LEADS 可以无缝集成到现有的 TrialMind 网络平台作为后端组件,使医学专业人士能够无任何技术障碍地使用它。
但究其本质仍然只是一个挖掘信息的道具,LEADS 还是依赖于从医学文献中获取的培训数据以及指令数据生成管道的质量。不过,既然它已经表现出来优于通用 LLMs 的卓越性能,那不妨就此尝试一下人机协作。


