
如果告诉你,AI在推箱子等游戏场景上训练,能让它在几何推理与图表推理上表现更好,你会相信吗?
复旦NLP实验室联合字节跳动智能服务团队的最新研究给出了一个令人意外的发现:游戏不仅是娱乐工具,更是训练AI推理能力的宝贵资源。

- 标题:Code2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
- 论文链接:https://arxiv.org/abs/2505.13886
- 代码仓库:https://github.com/tongjingqi/Code2Logic
- 数据和模型:https://huggingface.co/Code2Logic
引言
高质量多模态推理数据的极度稀缺,制约了视觉语言模型(VLMs)复杂推理能力的提升。那么,有没有一种低成本又可靠的方法来大规模生成这些数据呢?
复旦与字节的研究团队创新性地提出了一个巧妙的思路:利用游戏代码自动合成视觉推理数据。

图1:GameQA数据集中各游戏类别的代表性游戏:3D重建、七巧板(变体)、数独和推箱子。各游戏展示两个视觉问答示例,包含当前游戏状态图片,相应的问题,以及逐步推理过程和答案。
从游戏代码到推理数据:Code2Logic的奇思妙想
为什么选择游戏代码?研究团队发现,游戏具有三个独特优势:首先,游戏天然具有明确定义的规则且结果易于验证,确保生成数据的准确性;其次,游戏代码编码了状态转换逻辑,天然包含因果推理链;最后,游戏代码可通过大语言模型(LLM)轻松生成,成本极低。
基于这一洞察,团队提出了Code2Logic方法,借助LLM通过三个核心步骤将游戏代码中的隐式推理转化为显式的多模态推理数据,如图2所示:
第一步:游戏代码构建。通过LLM(如Claude 3.5、GPT 4o)自动生成游戏代码,如仅需一行提示词即可构建完整的“推箱子(Sokoban)”游戏逻辑。
第二步:QA模板设计。从游戏代码中提取各种推理模式,设计相应的任务及其问答模板。
第三步:数据引擎构建。构建自动化程序,重用游戏核心代码(如“move”函数逻辑),批量生成符合模板的问答实例。数据生成过程完全自动化,且推理过程与答案正确性由代码执行保证。
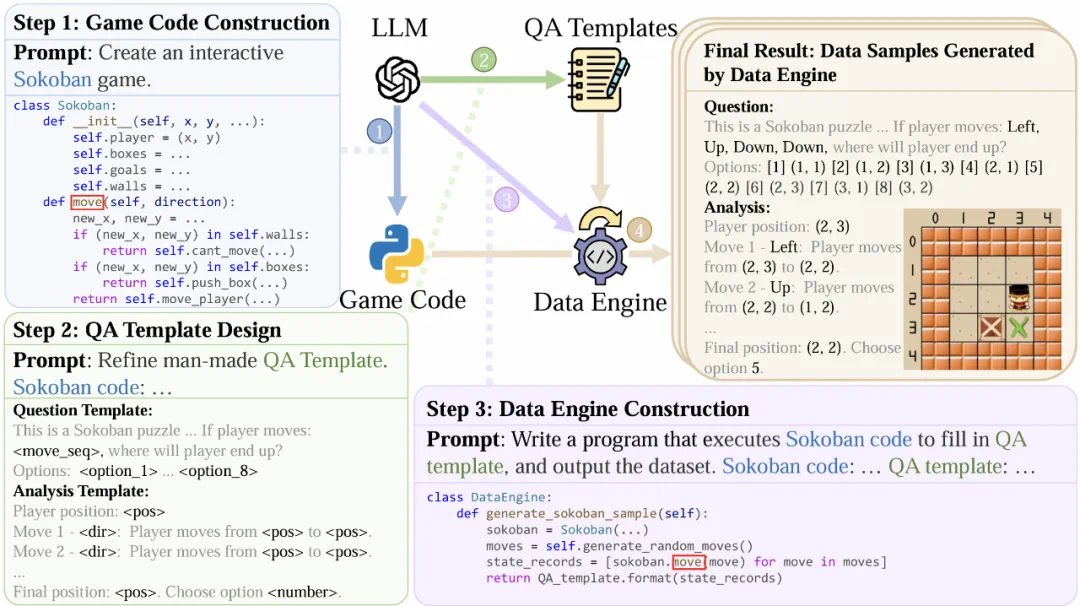
图2:Code2Logic方法流程示意
GameQA:可扩展的多模态推理数据集
利用Code2Logic方法,研究团队构建了GameQA数据集,具有以下核心优势:
大规模且多样。涵盖4大认知能力类别,30个游戏,158个推理任务,14万个问答对,如图1和图3所示。
可扩展和成本极低。数据引擎可用Code2Logic方法低成本构建,代码构建完成后便能无限生成新样本,源源不断地产生数据。
难度设置合理。通过设置代码参数,游戏任务难度可控制为Easy、Medium和Hard三级,同时视觉输入即游戏状态复杂性也有三级的设置。这种细粒度的难度设置便于系统评估模型能力。
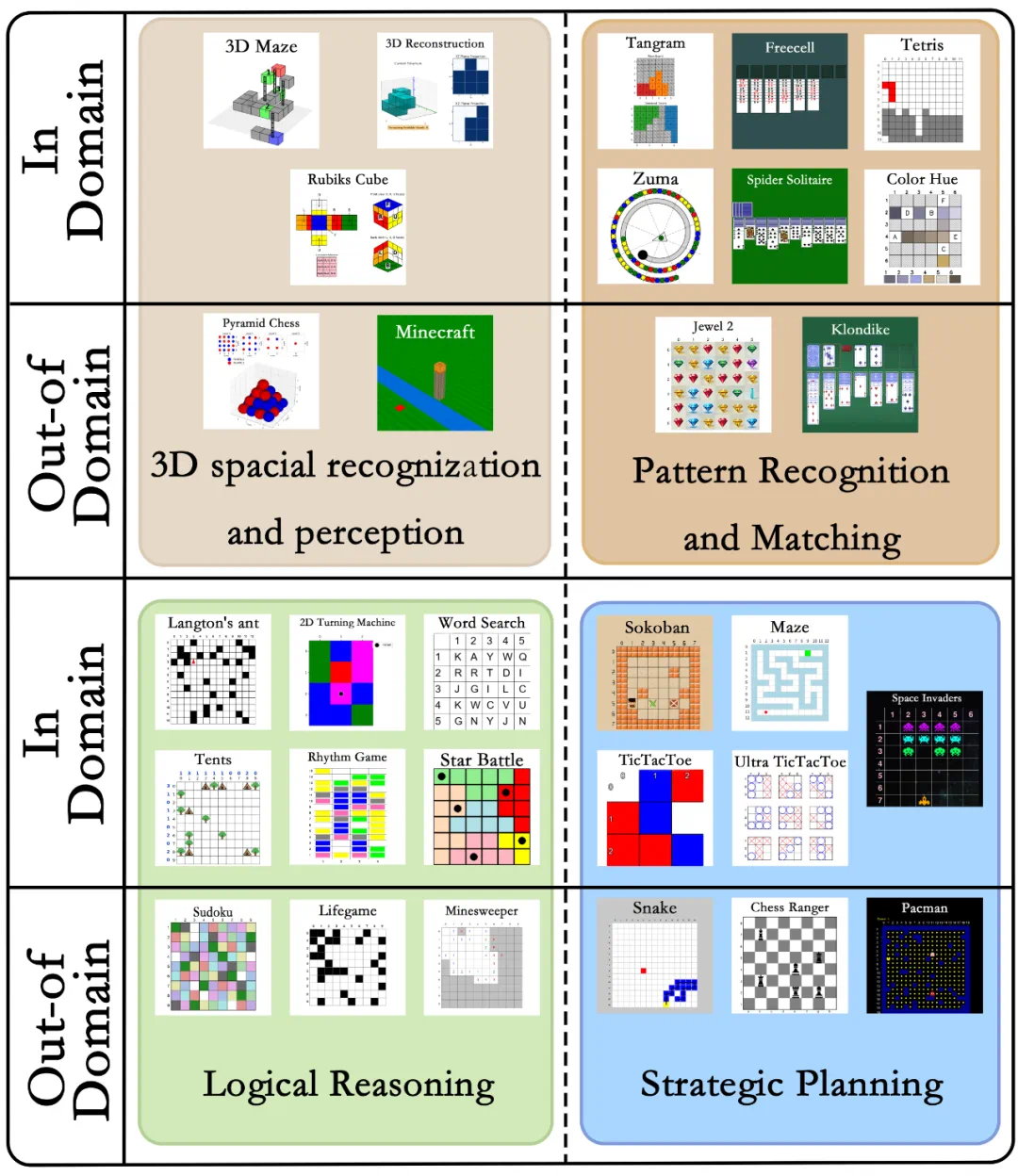
图3:GameQA的30个游戏,分为4个认知能力类别。域外游戏不参与模型训练。
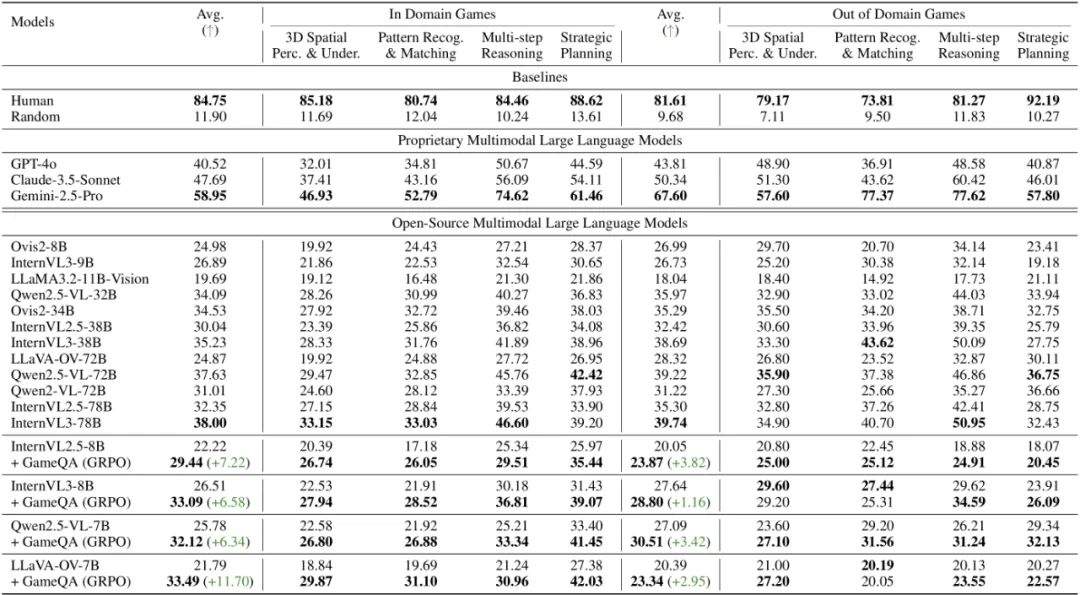
表1:GameQA域内和域外游戏的评测结果。在GameQA域内游戏测试集上,理工科本科生的准确率有84.75%,而先进的Claude-3.5-Sonnet只有47.69%,仅为人类准确率的一半,Gemini-2.5-Pro的58.95%也与人类有较大差距。在GameQA上训练可显著提升模型在域内外测试集上的表现。
核心发现:游戏数据驱动的通用能力提升
在游戏数据上训练后的能力提升泛化效果如何?研究中最令人惊喜的发现是:仅使用GameQA进行强化学习训练,在域内测试集上取得显著提升的同时,模型不但在域外游戏上展现出强大泛化能力(表1),而且还在通用视觉语言推理基准上获得了明显提升。
从表2的从评测结果可见,在GameQA上进行GRPO训练后,四个开源多模态模型均在7个通用视觉语言推理基准上获得性能提升,特别是Qwen2.5-VL-7B,取得了最显著的2.33%平均提升。
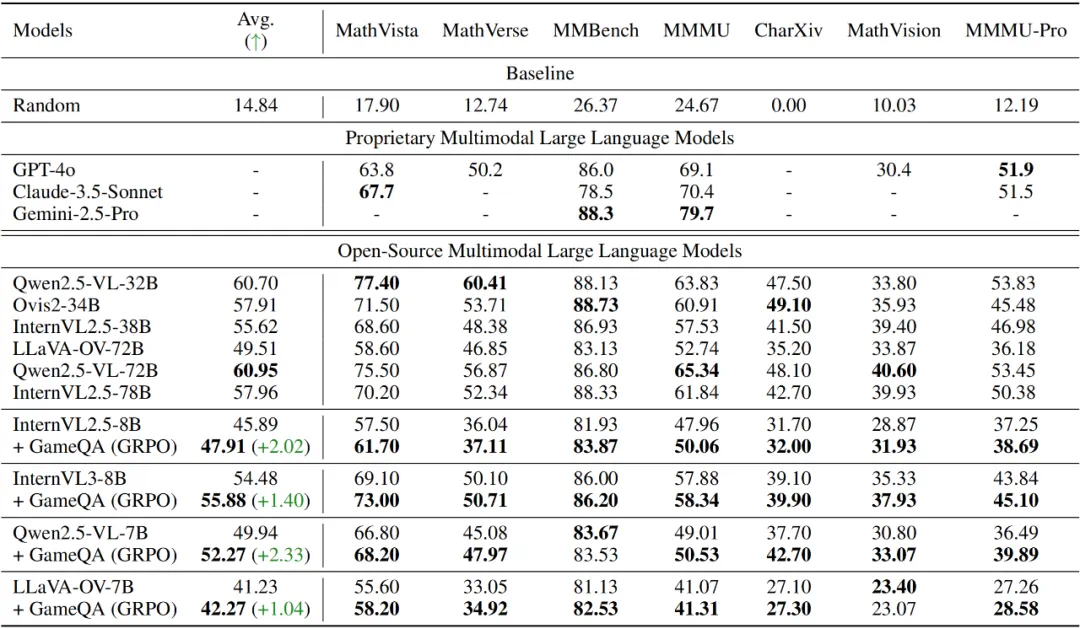
表2:通用视觉语言推理基准上的评测结果。模型在GameQA上GRPO训练后可泛化到通用视觉语言推理基准。
训练效果:GameQA击败几何数据集
为进一步探究GameQA的价值,研究团队设计了对照实验:用5K GameQA样本与8K样本的几何推理数据集进行对比训练,如表3所示。结果出人意料:尽管数据量更少且领域不匹配,GameQA训练的模型在通用视觉语言推理基准上表现更优。
在数学相关测试(MathVista: 68.70% vs 67.63%)中,游戏数据竟然超过了“对口”的几何数据。这一结果表明,游戏中的认知多样性和推理复杂性,具有强通用性和迁移能力。
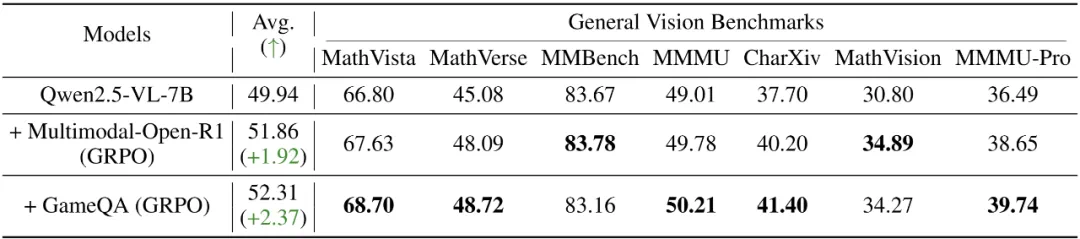
表3:GameQA(5K)与几何推理数据集Multimodal-Open-R1(8K)对比训练评测结果
深度剖析:GRPO如何提升模型能力?
为理解强化学习如何改善模型性能,研究团队随机采样了案例进行了细致的人工分析。结果显示,GRPO训练后,模型在视觉感知和文本推理两个方面都有显著提升。
如图4,从GameQA测试集和通用视觉语言推理基准中随机采样共790个测试样本,人工比较模型在训练前后的回答,最终得出:在GameQA数据上,10.94%的案例视觉感知得到提升,14.95%的案例文本推理得到提升。在通用视觉语言推理基准上,这两个数据分别为13.57%和8.57%。
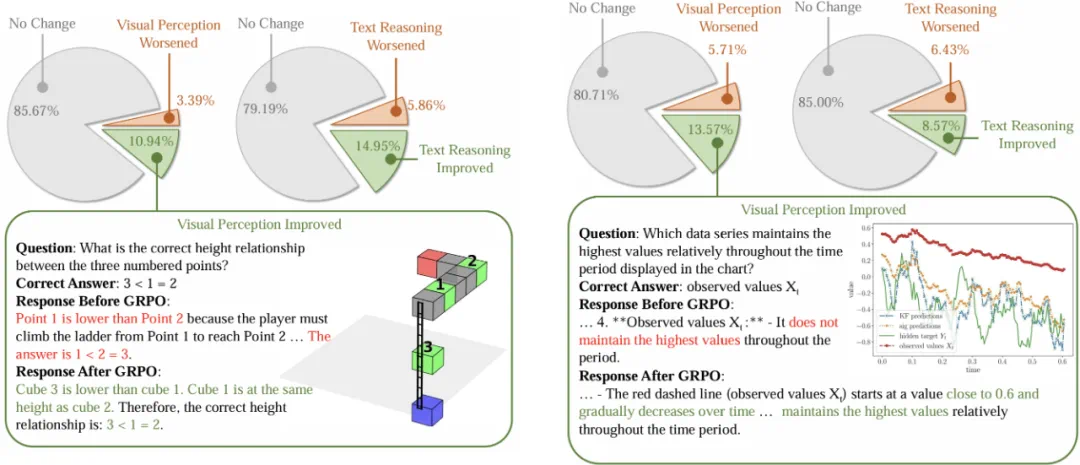
图4:GRPO对视觉感知和文本推理的影响。从GameQA与通用视觉语言推理基准分别随机选取650例与140例进行人工分析。左右两边分别为游戏任务和通用视觉语言推理基准上的表现变化。
Scaling effect:游戏多样性与样本多样性的影响
通过系统性实验,研究团队还揭示了两个重要的Scaling effect,即游戏多样性与样本多样性的影响,如图5所示:
随着游戏种类变多,域外泛化效果变强:使用20种游戏训练的模型在未见游戏上提升1.80%,在通用基准上提升1.20%,均优于使用4种或10种游戏的配置。
样本多样性与域外泛化效果正相关:对比三种训练配置(5K样本×1轮 vs 1K样本×5轮 vs 0.5K样本×10轮),结果显示接触更多不同样本比重复学习少量样本更有效。
这两个Scaling effect表明,GameQA的多样性与可扩展性优势,能够直接带来模型在通用推理任务上更强的泛化性能。
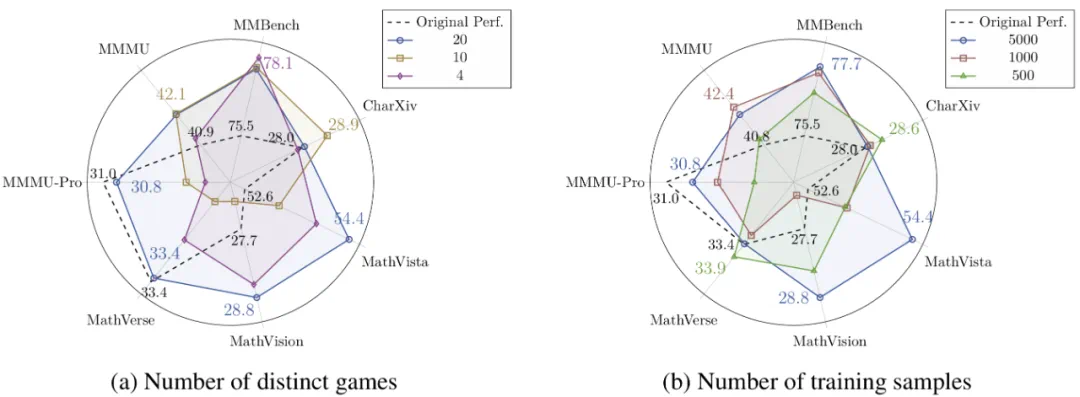
图5:Qwen2.5-VL-3B在GameQA上训练,游戏种类数与样本多样性的Scaling effect
案例分析:VLMs的推理瓶颈在哪里?
通过对模型错误的细致分析,研究团队也发现了VLMs推理能力的关键缺陷,包括:
3D空间感知是最大短板。在3D迷宫等游戏中,模型经常混淆高度关系,将图像中位置较上的物体误判为具有更高的Z坐标。这反映出当前模型在3D空间理解上的根本性缺陷,如图6所示。
在识别模式与定位物体上存在显著困难。在游戏视觉场景不是标准的网格化结构(如“祖玛”、纸牌类游戏)时这一困难还会加剧。
多次看图时容易出错。在需多次识图的任务中,模型起初识别正确,但随后易受已有文本干扰,导致图文不符。
策略规划能力欠缺。面对一些需要寻找最优解的任务(如求解“推箱子”最优策略),模型既缺乏人类的直觉洞察来剪枝无用分支,也无法进行大规模搜索遍历,导致表现不佳。

图6:3D迷宫中GPT 4o混淆物体高度
结论
本研究提出了一种新颖的方法(Code2Logic),首次利用游戏代码合成多模态推理数据。
基于此方法,构建了GameQA数据集,该数据集具有低成本与可扩展、难度设置合理、规模大且多样性高的特点,为多模态大模型的训练与评估提供了理想的数据来源。
同时,研究团队首次验证了仅通过游戏问答任务进行强化学习,便能显著提升多模态大模型在域外任务的通用推理能力,这不仅验证了GameQA的泛化性,也进一步证实了游戏作为可验证环境,用于提升模型通用智能的潜力。


