DeepSeek开源了DeepSeek-OCR,用1张图片的信息,还原10页书的文字,10倍的压缩率,可以做到几乎不丢失信息。
视觉编码器走了不少弯路
大型语言模型记性不好,或者说,能记住的东西太有限。你给它一篇长长的文章,它的计算量呈二次方往上飙。
DeepSeek-AI团队提出了一个脑洞大开的想法:既然文字这么占地方,我们干嘛非得用文字存呢?能不能用图片来“压缩”文字信息?
这个点子基于一个我们都懂的道理,“一图胜千言”。一张印满文字的图片,在模型眼里,可能只需要很少的视觉token(vision tokens)就能表达清楚。而如果把这些文字转换成数字文本,token数量可能多得吓人。这就好比一个压缩包,用视觉的方式把海量文本信息给打包了。
说干就干,他们捣鼓出了一个叫DeepSeek-OCR的模型来验证这个想法。
结果相当惊人,当压缩比,也就是文本token数是视觉token数的10倍以内时,模型居然能把图片里的文字几乎完美地还原出来,准确率高达97%。就算把压缩比拉到20倍,准确率也还有60%。这就等于说,用视觉当媒介,真的可以高效地压缩文本信息。
在DeepSeek-OCR之前,业界在怎么让模型“看”图这件事上,已经摸索了很久,主流的视觉语言模型(VLMs)里,视觉编码器大概有三种玩法,但家家有本难念的经。
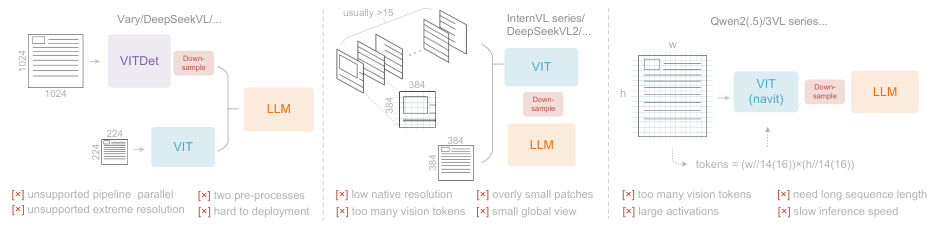
第一种是“双塔架构”,代表是Vary。它搞了两个并行的编码器,像两个塔一样,一个专门处理高分辨率图像。这么做虽然参数和内存都还算可控,但部署起来就麻烦了,等于要预处理两次图像,训练的时候想让两个编码器步调一致也很困难。
第二种是“切片大法”,代表是InternVL2.0。这方法简单粗暴,遇到大图就切成一堆小图块,并行计算。激活内存是降下来了,也能处理超高分辨率的图。但问题是,它本身编码器的原生分辨率太低,一切起图来就刹不住车,一张大图被切得七零八落,产生一大堆视觉token,反而得不偿失。
第三种是“自适应分辨率”,代表是Qwen2-VL。这种编码器比较灵活,能处理各种分辨率的图像,不用切片。听起来很美,可一旦遇到真正的大图,GPU内存就瞬间爆掉。而且训练的时候,要把不同尺寸的图像打包在一起,序列长度会变得特别长,训练效率极低。
这些模型都在各自的路上狂奔,增强文档光学字符识别(OCR)的能力,但似乎都忽略了一个根本问题:一篇一千个单词的文档,到底最少需要多少个视觉token才能完美解码?
DeepSeek-OCR的突破
DeepSeek-OCR的架构设计就是冲着解决这个问题去的。它也是一个端到端的视觉语言模型,一个编码器加一个解码器,结构清晰。
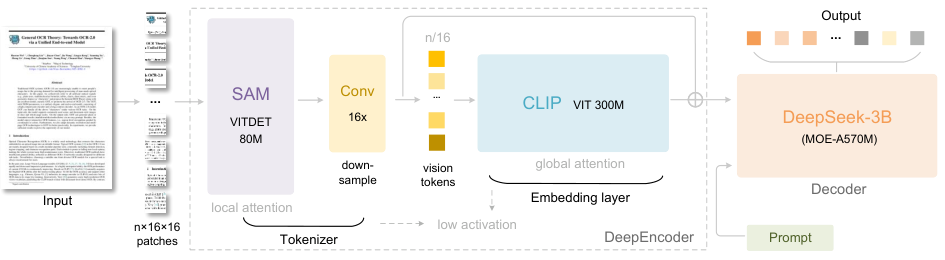
它的核心武器是一个叫DeepEncoder的编码器,参数量大约3.8亿。这编码器是把两个业界大神SAM-base(8000万参数)和CLIP-large(3亿参数)给串联了起来。可以把它想象成一个两级流水线。
第一级主要靠窗口注意力的视觉感知组件,用SAM-base改造。它负责初步提取图像特征。
第二级具有密集全局注意力的视觉知识组件,用CLIP-large改造。它负责深度理解和压缩这些特征。
为了让这两位大神能合作愉快,研究团队在它们中间加了一个2层的卷积模块,作用是把视觉token进行16倍的下采样。
举个例子。一张1024×1024的图像输进去,编码器先把它切成4096个小块(补丁token)。第一级流水线处理这4096个token,因为参数量不大而且主要是窗口注意力,内存还扛得住。在进入第二级全局注意力之前,这4096个token先被压缩模块“挤了一下水分”,变成了256个。这样一来,计算量最大的全局注意力部分处理的token数就大大减少,整体的激活内存就控制住了。
为了能测试不同压缩比下的性能,DeepSeek-OCR还支持多种分辨率模式,跟相机似的,有小、中、大、超大各种档位。
原生分辨率模式下,有四个档位:Tiny(512×512,64个token)、Small(640×640,100个token)、Base(1024×1024,256个token)和Large(1280×1280,400个token)。小图就直接缩放,大图为了保持长宽比会进行填充,保证图像信息不失真。

动态分辨率模式更灵活,可以把几种原生分辨率组合起来用。比如Gundam模式,就是把一张图切成好几个640×640的小块(局部细节),再加一个1024×1024的全局视图。这种方法特别适合处理报纸这种超高分辨率的图像,既能看清细节,又不会因为切片太碎而产生过多token。
有意思的是,所有这些模式都是用一个模型训练出来的,实现了“一机多能”。
编码器负责压缩,解码器就负责解压。DeepSeek-OCR的解码器用的是自家的DeepSeekMoE,一个拥有30亿参数规模、混合专家(MoE)架构的模型。它在推理的时候,只需要激活其中一小部分专家(约5.7亿参数),既有大模型的表达能力,又有小模型的推理效率,非常适合OCR这种专业性强的任务。它的任务,就是看着编码器给过来的那点儿压缩后的视觉token,把原始的文本内容给一字不差地“脑补”出来。
数据是这样喂出来的
一个强大的模型背后,必然有海量且优质的数据。DeepSeek-OCR的“食谱”非常丰富,主要分三大类。
第一类是OCR 1.0数据,占大头。
这是最基础的OCR任务,包括文档和自然场景的文字识别。团队从网上扒了大约3000万页PDF文档,覆盖近100种语言,其中中英文占了绝大多数。
为了让模型学得更扎实,他们准备了两种“教材”:粗糙版的和精细版的。粗糙版就是直接从PDF里提取文字,教模型认识光学文本。精细版则动用了更高级的布局分析模型和OCR模型来做标注,告诉模型哪里是标题、哪里是段落,文字和检测框怎么对应。

对于小语种,他们还玩了一手“模型飞轮”,先用少量数据训练出一个小模型,再用这个小模型去标注更多数据,像滚雪球一样把数据量滚大。
此外,他们还收集了300万份Word文档,这种数据格式清晰,尤其对公式和表格的识别很有帮助。自然场景的OCR数据也搞了2000万,中英文各一半,让模型不光能看懂“白纸黑字”,也能看懂街边的广告牌。
第二类是OCR 2.0数据,这是进阶任务。
主要包括图表、化学公式、平面几何图形的解析。图表数据,他们用程序生成了1000万张,把图表解析定义成一个“看图说话”的任务,直接输出HTML格式的表格。化学公式,利用公开的化学数据库生成了500万张图片。平面几何图形也生成了100万张,还特意做了数据增强,把同一个几何图形在画面里挪来挪去,让模型明白,位置变了,但图形本身没变。
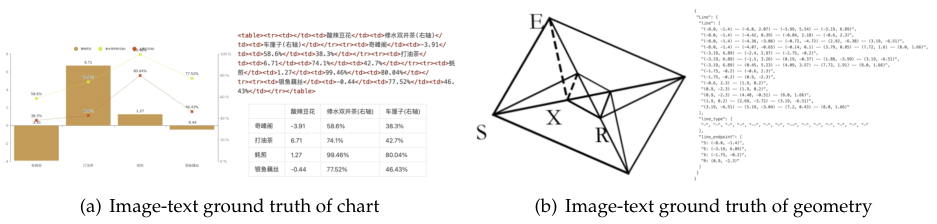
第三类是通用视觉数据,占两成。
为了让它保留一些基本的图像理解能力,比如看图说话、物体检测等,团队也喂了一些通用视觉数据。这主要是为了给未来的研究留个口子,方便大家在这个模型的基础上做二次开发。
最后,为了保证模型的语言能力不退化,还混入了10%的纯文本数据一起训练。整个训练数据里,OCR数据占70%,通用视觉数据占20%,纯文本数据占10%,配比相当讲究。
训练过程分两步走。第一步,单独训练DeepEncoder编码器,让它先学会怎么高效地看图和压缩。第二步,把训练好的编码器和解码器连在一起,用上面说的数据配方,正式训练DeepSeek-OCR。
模型性能测试
核心的视觉-文本压缩能力测试。
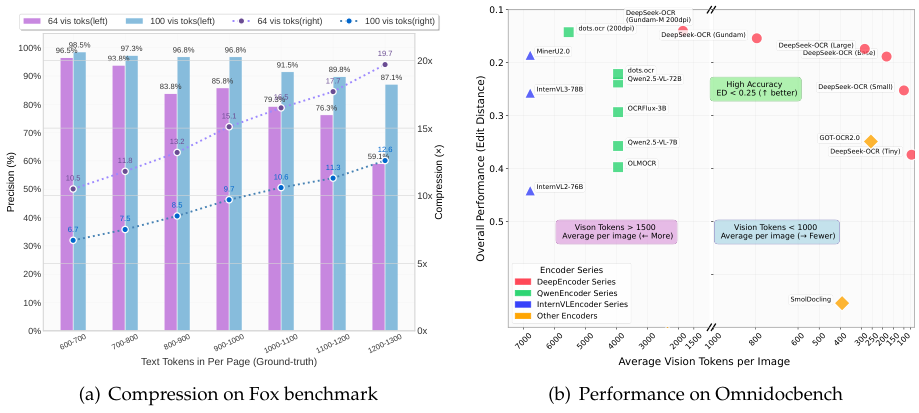
研究团队用了Fox的基准测试集,专门挑了那些文本token数在600到1300之间的英文文档来测试。这个token数,用Tiny模式(64个视觉token)和Small模式(100个视觉token)来处理正合适。
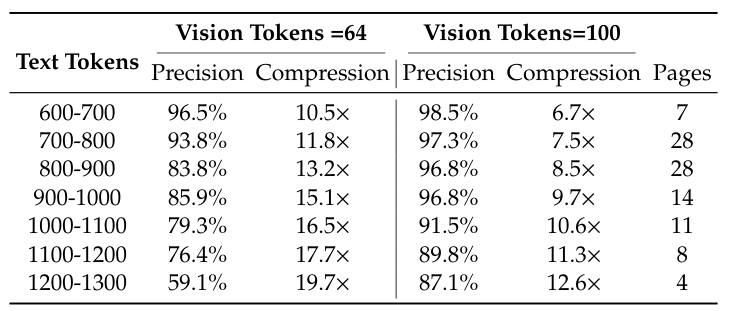
表格里的数据非常直观。在10倍压缩比以内,模型的解码精度几乎没损失,都在97%左右。
这结果让人很兴奋,意味着未来也许真的可以通过“文转图”的方式,实现接近无损的上下文压缩。
当压缩比超过10倍,性能开始下降,原因可能是长文档的排版更复杂,也可能是图片分辨率不够,文字开始模糊了。但即便压缩到近20倍,精度还能保持在60%上下。
这充分证明了,上下文光学压缩这个方向,大有可为。
接下来是实际的OCR性能。在另一个更全面的基准测试OmniDocBench上,它的表现同样亮眼。
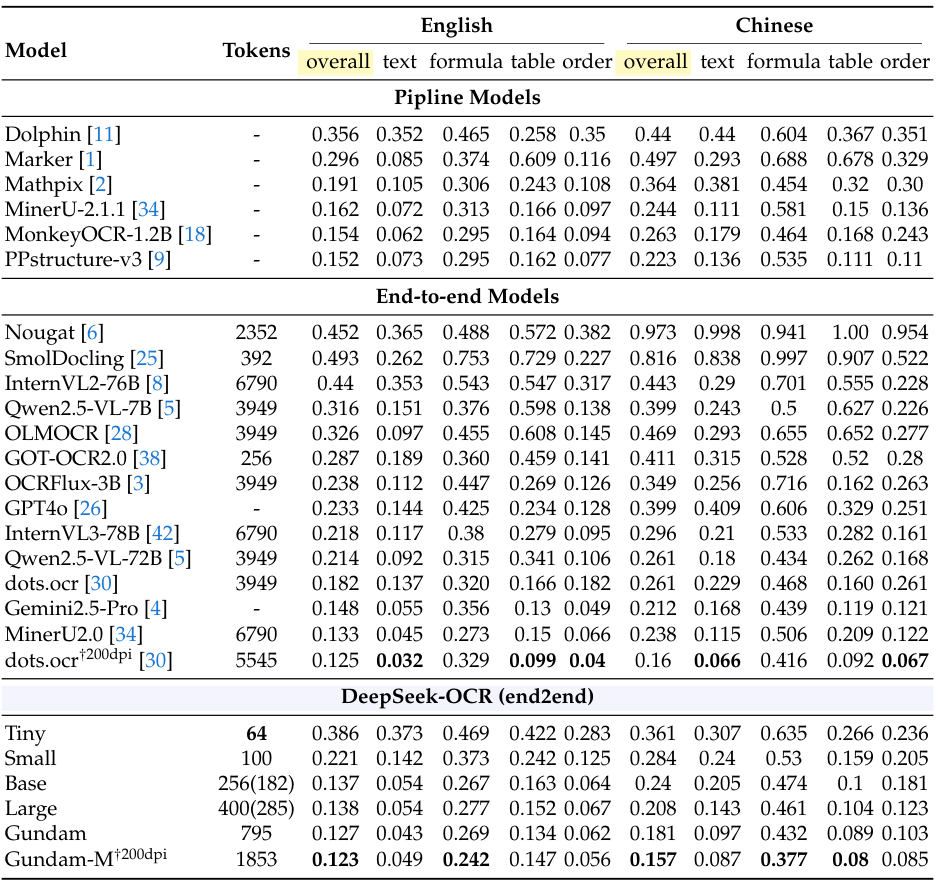
从这张密密麻麻的表里能看出,DeepSeek-OCR只用100个视觉token(Small模式),就超过了用256个token的GOT-OCR2.0。用不到800个token的Gundam模式,更是把需要近7000个token的MinerU2.0甩在身后。这说明DeepSeek-OCR的token效率极高,用更少的资源干了更多的活。
不同类型的文档,对视觉token的需求也不一样。
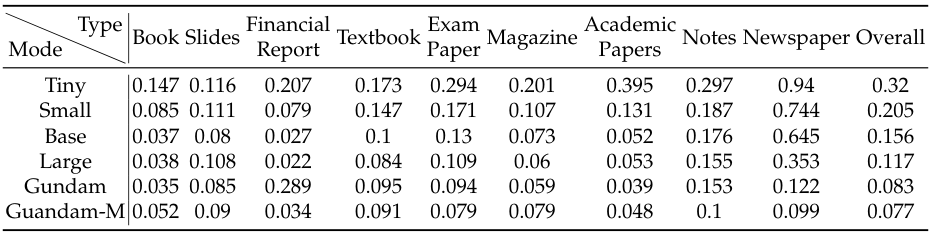
你看,像幻灯片这种格式简单的,64个token的Tiny模式就够用了。书籍和报告,100个token的Small模式也表现不错。
这再次印证了前面的结论,这些文档的文本token数大多在1000以内,没超过10倍压缩比的临界点。但对于报纸这种信息密度极高的文档,文本token动辄四五千,就必须得上Gundam模式甚至更强的模式才行。这些实验清晰地划出了上下文光学压缩的适用边界。
除了能打的性能,DeepSeek-OCR还有很多“才艺”。它能进行“深度解析”,比如识别出文档里的图表,并把它转换成结构化的数据。
还能看懂化学公式,并把它转成SMILES格式。
它还能处理近100种语言的文档。

当然,作为VLM,基本的看图说话、物体检测等通用能力也都在线。

未来的想象空间还很大
DeepSeek-AI团队的这项工作,是对视觉-文本压缩边界的一次成功探索。10倍压缩比下接近无损,20倍压缩比下仍能看,这个结果足够让人兴奋。
这为未来打开了一扇新的大门。
比如,在多轮对话中,可以把几轮之前的对话历史渲染成一张图片存起来,实现10倍的压缩效率。对于更久远的上下文,还可以通过逐步缩小图片分辨率来进一步减少token消耗。
这个过程,很像人脑的记忆机制。刚发生的事情记得清清楚楚,细节分明。时间久远的事情,就只剩下个模糊的轮廓。通过这种光学压缩的方式,我们可以模拟出一条生物学的遗忘曲线,让模型在处理超长上下文时,能把宝贵的计算资源留给最重要的近期信息,同时又不会完全“忘记”过去,实现了信息保留和计算成本之间的完美平衡。
仅靠OCR任务还不足以完全验证光学压缩的全部潜力,未来还需要更多更复杂的测试。
DeepSeek-OCR已经证明,上下文光学压缩是一个非常有前景的新方向,它可能为解决大型语言模型“记性差”这个老大难问题,提供一把全新的钥匙。


