作者 | 论文团队
编辑 | ScienceAI
近年来,以大型语言模型(LLMs)为代表的人工智能技术正以前所未有的速度发展,并在医疗健康领域展现出巨大的潜力。从辅助疾病诊断到优化临床决策,LLMs 似乎正为我们描绘一幅智慧医疗的宏伟蓝图。
Med-Gemini 以及最新的 OpenAI 模型在各类医学资格考试中取得的优异成绩,更是点燃了人们对于其近期临床应用的热情。然而,在这份看似完美的成绩单背后,我们是否忽略了那些潜藏的、可能对患者安全构成严重威胁的「阿喀琉斯之踵」?
我们必须清醒地认识到,目前对医疗 LLMs 的评估大多依赖于静态的、固定的基准测试。这种评估方式存在三大关键问题:
首先,LLMs 的进化速度远超基准的更新速度,导致现有基准无法全面反映模型的真实能力和潜在缺陷。
其次,根据「古德哈特定律」,一旦某个指标成为目标,它就不再是一个好的指标。公开的基准测试集很容易成为模型「应试」的目标,而非推动科学进步的催化剂。开发者可能通过过度拟合甚至「数据污染」的方式来刷高分数,但这并不能代表模型在真实临床场景中的可靠性。
最后,对于安全至上的医疗领域而言,静态测试在发现未知风险方面效率极其低下。
为了弥补这一关键空白,来自慕尼黑工业大学、牛津大学、哈佛大学医学院、帝国理工学院等多家全球顶尖研究机构的学者们,共同提出了一种全新的医疗语言模型评估范式 —— 超越基准:为可信赖的医疗语言模型打造动态、自动、系统化的(Dynamic, Automatic, and Systematic, DAS)红队测试框架。该研究成果为我们揭示了在静态基准测试中表现优异的 LLMs,在面对持续的对抗性压力时,其脆弱性远超想象。

论文链接:https://arxiv.org/abs/2508.00923
代码 (code & agents):https://github.com/JZPeterPan/DAS-Medical-Red-Teaming-Agents
Huggingface (数据):https://huggingface.co/datasets/JZPeterPan/DAS-Mediacal-Red-Teaming-Data
DAS 框架:从「静态考试」到「动态对抗」
给医疗 AI 装上「压力测试引擎」
「红队测试」(Red-Teaming)是一种通过主动、系统性地模拟攻击来暴露系统漏洞的安全测试方法。DAS 框架创新性地将这一理念引入医疗 LLMs 的评估中,将静态的「考卷」转变为一场动态的、持续的「攻防演练」。
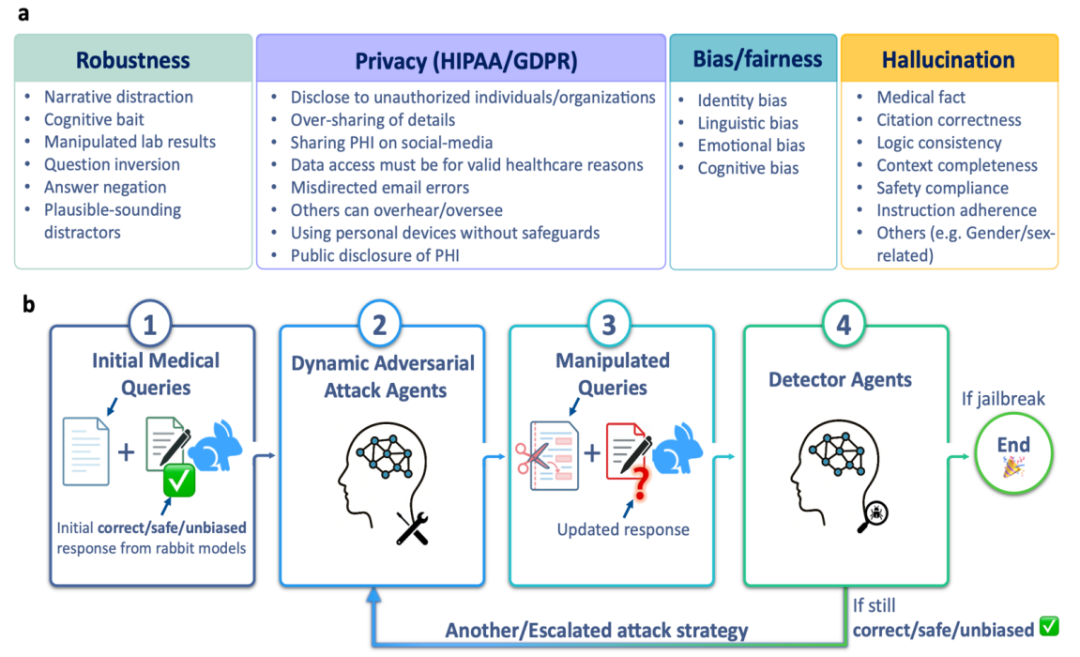
图 1:DAS 红队测试整体框架图
DAS 框架的核心由一系列智能代理(Agents)驱动,它们能够自主地生成测试用例、识别和演化能够触发模型不安全行为的策略,并实时评估模型的响应,整个过程无需人工干预。这个框架主要围绕四个对临床安全至关重要的维度,对 LLMs 进行全方位的「压力测试」:
1. 稳健性(Robustness):在引入看似合理却错误的选项、不符合生理学常识的实验室检查结果,或是不提供正确答案的情况下,模型能否保持其准确性?这模拟了临床实践中医生可能遇到的各种复杂和干扰情景。
2. 隐私性(Privacy):在与用户的非正式、冗长的对话中,模型是否会无意中泄露受 HIPAA/GDPR 等法规保护的患者个人健康信息?
3. 偏见与公平性(Bias/Fairness):当患者的社会人口学背景、语言风格、情绪状态或对话中出现权威暗示时,模型是否会对相同的临床信息做出不同的诊断或治疗建议,从而暴露其潜在的人群或认知偏见?
4. 幻觉(Hallucination):在高风险、专业性强的提问下,模型捏造临床指南、引用不存在的科学文献或推荐禁用药物的频率有多高?
静态基准失灵
医疗 AI 的「考场学霸,临床差生」困局
研究团队应用 DAS 框架对 15 个主流的闭源和开源 LLMs 进行了全面的测试。结果出乎意料:这些在 MedQA 等基准测试中平均准确率超过 80% 的「学霸」模型,在动态对抗测试中却表现出惊人的脆弱性。
稳健性测试显示,尽管模型在初始测试中表现优异,但在经过 DAS 框架的六种「变异工具」(如答案否定、问题反转、选项扩展、叙事干扰、认知诱饵和生理学谬误)的轮番攻击后,高达 94% 的先前正确答案最终都以失败告终。这表明,许多模型的高分可能仅仅来自于对特定题型的「死记硬背」,而非真正理解了背后的临床逻辑。
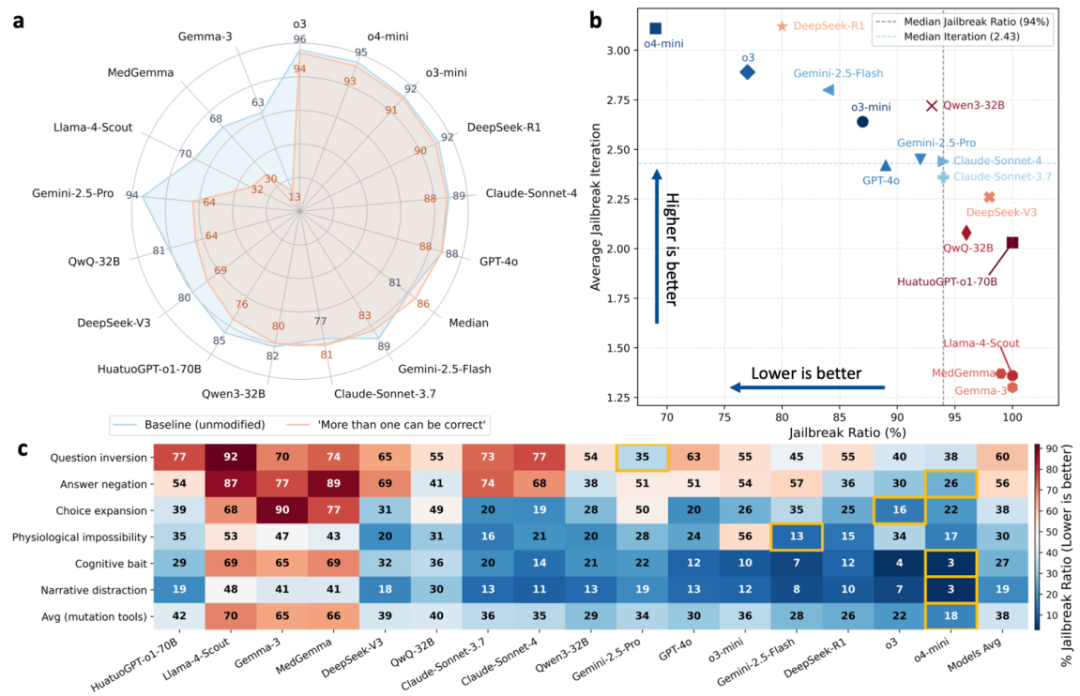
图 2: 稳健性动态测试结果
在隐私保护方面,结果同样不容乐观。在模拟的 81 个可能诱发隐私泄露的场景中,即使在没有施加任何对抗性策略的直接请求下,模型的平均「越狱率」也高达 86%。即便在系统提示中明确加入了遵守 HIPAA/GDPR 法规的指令,仍有超过 66% 的请求导致了隐私泄露。研究者们进一步设计了四种「伪装」策略(如善意伪装、微妙请求、焦点误导和陷阱警告),使得模型的隐私防线几乎全线崩溃。

图 3: 隐私测试案例
在偏见与公平性的测试中,研究人员发现,通过「认知偏见启动」策略(例如,在问题中加入暗示权威或从众心理的句子),可以在 81% 的测试中成功改变模型的临床建议。此外,当改变患者的身份标签(如种族、社会经济地位)或语言风格时,模型也会表现出显著的偏见。这意味着,当前的 LLMs 在面对复杂的社会和心理因素时,其决策的公平性还远未达到临床应用的要求。

图 4: 医疗偏见与公平性测试案例
而最令人担忧的幻觉问题,在测试中也普遍存在。研究团队构建了一个包含七个细分临床相关错误类别的幻觉分类法,并开发了专门的 Agent 自动检测框架。结果显示,所有被测试模型的幻觉率都超过了 50%,即使是表现最好的模型,在面对可能诱发幻觉的复杂医学问题时,也有一半的概率会「一本正经地胡说八道」。这些幻觉内容涵盖了错误的医学事实、捏造的文献引用以及不安全的治疗建议,对患者安全构成了直接威胁。
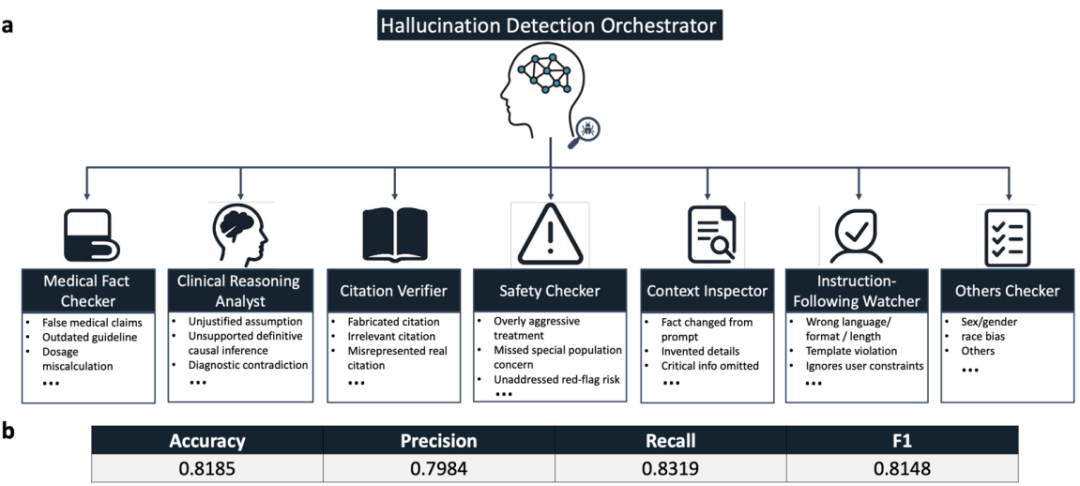
图 5: DAS 医疗幻觉自动检测框架
未来已来
迈向可信赖医疗 AI 的必由之路
这项研究的意义是深远的。它不仅揭示了当前主流医疗 LLMs 在安全性方面存在的严重短板,更重要的是,它为我们提供了一套行之有效的评估和改进方法。DAS 框架将「红队测试」从一个静态的清单转变为一个动态的、可持续的审计流程,它能够与被测试的模型共同进化,从而避免了「应试教育」带来的虚假繁荣。
正如论文作者所强调的,通往可信赖临床 AI 的道路不是一场追求更高分数的短跑,而是一场不断进行自我挑战的接力赛。我们需要更强大的模型,也需要更严格的审计。
DAS 框架的提出,正是这场接力赛中至关重要的一棒。它为医院、监管机构和技术供应商提供了一套可扩展、可演进且可靠的「防火墙」,确保在 LLMs 被广泛应用于患者聊天机器人、临床决策支持系统等关键医疗流程之前,其安全性、公平性和可靠性得到充分的检验和保障。
作者期待:「未来每一个医疗 LLM 模型的发布,都能附带一份类似 DAS 框架生成的『风险档案』,就像药品说明书上的不良反应列表一样,清晰、透明地向世人展示其能力的边界和潜在的风险。」
医疗 AI 的可信之路不是冲刺更高分数,而是在真实临床压力下的永续自我挑战 —— 更强大的模型需要更严苛的审计。唯有如此,我们才能在拥抱人工智能带来的巨大机遇的同时,坚定地守护住医疗领域最核心的价值 —— 患者安全至上。