在日益强调“思维能力”的大语言模型时代,如何让模型在“难”的问题上展开推理,而不是无差别地“想个不停”,成为当前智能推理研究的重要课题。
中国科学院自动化研究所联合鹏城实验室提出了一种高效的推理策略,赋予推理大模型根据题目难度自主切换思考模式的能力:
通过一个小小的省略号作为提示词 + 多阶段强化学习,引导大模型自主决定是否深度思考、思考多少。

研究背景:大模型“想太多”,是优点还是负担?
在大语言模型快速发展的今天,越来越多的模型开始具备“深度思考能力”。
比如,DeepSeek-R1系列模型引入了一种特别的提示结构:先<think> ,再<answer>。也就是说,模型在回答之前会“思考”一番,生成一整段包含反复自我反思、自我验证的逻辑推理,然后才给出结论[1]。这种方式是近来提升模型准确率的重要方法。“深度思考”的确带来了好处,模型不再“张口就答”,而是会分析、论证、验证;在复杂问题中,能显著提升答对率,避免“拍脑袋”行为。但是,如果问题本身很简单,模型还有必要“苦思冥想”一大段吗?
答案是:未必。事实上很多情况下,模型在解决简单任务时也会机械地生成一大堆推理语句。这就好比你问一个人“2+3等于几”,他却要从自然数定义讲起,列出加法交换律,甚至反复试错,最后才告诉你答案是5。这种现象称为过度思考(Overthinking)。
过度思考问题在DeepSeek-R1、Claude 3.7、Qwen3等推理模型中广泛存在。尤其是当prompt总是强制模型使用<think>标签时,它就会默认开启“深度思考模式”,不论问题简单或复杂,推理过程长度极长,带来了响应延迟和计算成本上升;甚至在冗余思考中“越想越错”,反而降低了准确率。
目标:教会模型学会「什么时候该思考」
团队认为,推理过程的存在不该是“硬规定”,而应该因题制宜。就像人类一样:面对简单问题能立刻给出答案;面对复杂问题才会进行详细推理与分析。那么,大模型能不能也具备这样的“任务感知能力”?能不能学会自己判断:这道题该不该思考,该思考多少?
这是AutoThink背后的初衷。AutoThink 不再让模型“永远思考”,而是训练它——学会何时该思考,何时可以跳过思考,甚至决定思考多少。
AutoThink:让模型自主决定是否思考
团队提出了一个简单而有效的方案,叫做AutoThink。它有两核心个关键词:
- 最小提示干预(Minimal Prompting)
- 多阶段强化学习(Multi-Stage RL)
通过这两者的结合让模型具备了类似人类的“任务感知能力”:简单问题不浪费思考,复杂问题多加推理,真正做到“按需思考”,如图1所示。相比之下,传统方法要么手动控制思考模型[2],要么不区分题目难度地压缩推理过程[3]。
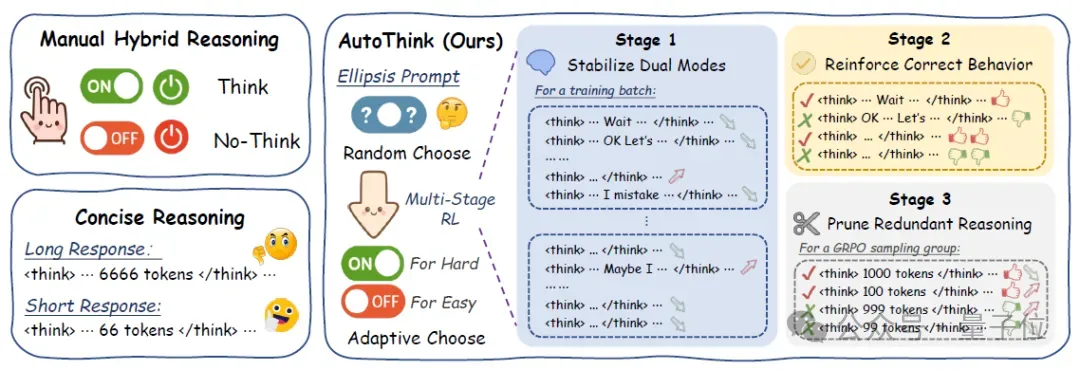
△图1:AutoThink 与手动控制和简洁推理方法的核心差异:根据难度自主切换思考模式。
实现Autothink的第一步,其实很简单:只需要在原有的prompt里,加入一个省略号 “…”,模型就会自行决定是否进行推理。
举个例子:
- 标准提示词(Standard Prompt): <think>→总是进入思考模式
- 不思考提示词(No-Thinking Prompt)[2]:<think> Okay, I have finished thinking. →总是跳过深度思考
- 省略号提示词(Ellipsis Prompt): <think>… →随机进入或跳过思考
实验发现,“省略号提示词”在没有任何训练的情况下,已经能激发出两种模式的随机共存,有些题目模型会写出完整思考,有些则会直接给出简洁的参考答案,如图2(a)所示。用“省略号提示词”进行推理的平均准确率和推理长度都介于标准提示和不思考提示之间。这种“隐式控制”行为打开了一扇门——模型已经有潜力学会“选择是否思考”,只需要再稍作引导。
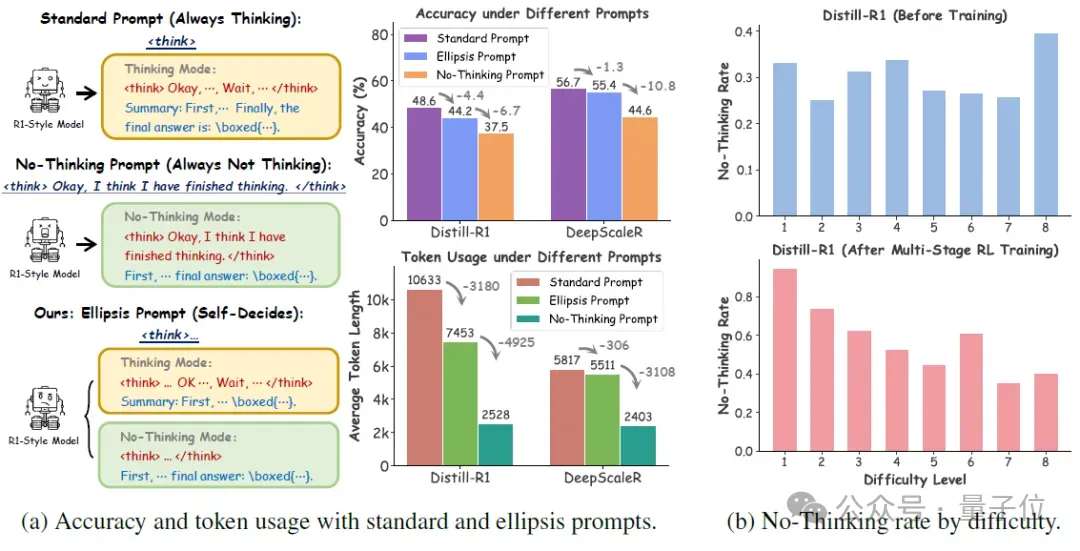
△图2:不同的提示词塑造了模型不同的推理行为和计算消耗
省略号提示能触发模式切换,但不能“因题制宜”
虽然加入 “…” 可以让模型切换推理模式,但模型并不会根据题目的难易程度来自主选择。也就是说,它可能对简单题深度推理,对难题却直接跳过思考。这种随机行为仍然缺乏任务感知能力。如图2b (上)所示。使用省略号提示后,模型在不同难度题目上“跳过思考”的比例分布相对平坦。这说明,虽然省略号提示可以开启“是否思考”的能力,但不能赋予模型“知道何时该思考”的智慧。
为了教会模型自主思考,团队设计了一个三阶段的强化学习策略,从最基础的模式稳定,到行为优化,再到推理剪枝。经过训练后,模型的思考模式变化成图2b (下) 那样:模型不再“随缘”地决定是否思考,而是展现出更符合人类直觉的行为模式:在难度较高的问题上,模型更倾向于进入思考模式;而在容易的问题上,则更愿意跳过思考、直接作答。
AutoThink 三阶段:一步步教会模型“何时该思考”
团队采用GRPO的强化学习方法。为了鼓励模型尽可能在不思考的前提下答对题目,首先设计了一个基础奖励函数 (naive reward),在答对的前提下“不思考”奖励最高(+2),答错且不思考惩罚最重(-1),体现了“能不想还答对最好,答错就该罚”的原则。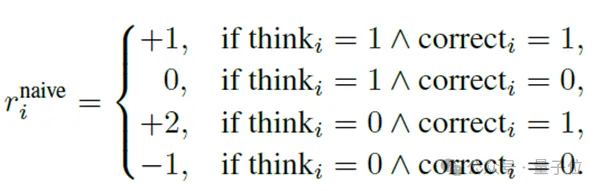
阶段一:防止模式坍缩,稳定思考行为
尽管上述naive reward优雅,但依照基础奖励函数训练的模型可能倾向于“全都思考”或“全都不思考”——这都是不健康的行为。例如,如果模型发现“都不思考”能更快提升平均奖励,就会彻底放弃思考!
为解决这个问题,加一层动态调节机制,根据整个训练过程中每个batch里的思考和不思考的比例,调整每条数据的奖励。这个阶段调整奖励函数如下:
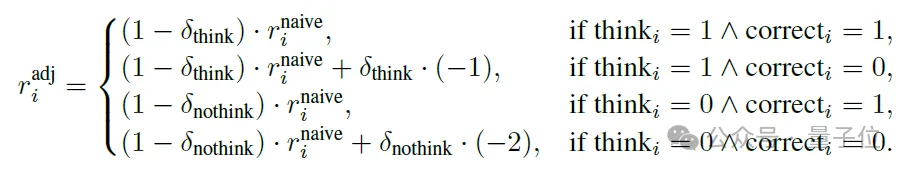
阶段二:在两种模式下分别优化准确率
在稳定模型思考与否的行为后,解除第一阶段的束缚,让模型自由选择是否思考。此时的奖励与 naive reward 一致。这个阶段的目标是放任模型自由发展,鼓励模型对于当前无法解决的问题使用思考模式深度探究,对于已经能够解决的问题使用不思考模式简洁回答。在这个阶段,往往会观察到伴随着训练准确率的提升,不思考和思考的回答长度均上升。
阶段三:在基于响应长度奖励,引导“简洁推理”
虽然第二阶段帮助模型提升了准确率,但也带来一个副作用——推理过程变得越来越长。模型在没有限制的情况下,容易“滔滔不绝”,输出一大段冗长推理。因此,在阶段三引入了一个“长度感知奖励机制” [4],简单来说,把一个 GRPO Group 的回答分为正确和错误的两组,对于回答正确的组,惩罚没必要的长回答;对于回答错误的组,鼓励简洁作答:
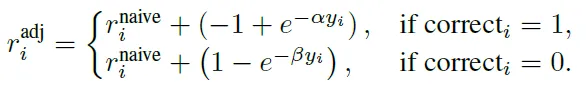
这个阶段在尽可能小地牺牲模型性能的情况下,压缩模型的输出长度,并最终得到一个简洁的、具有针对题目难度自主思考的模型。
为便于理解理解奖励的变化选一个例子可视化了阶段一(左)和阶段三(右)的四个模态的回答的奖励函数情况。
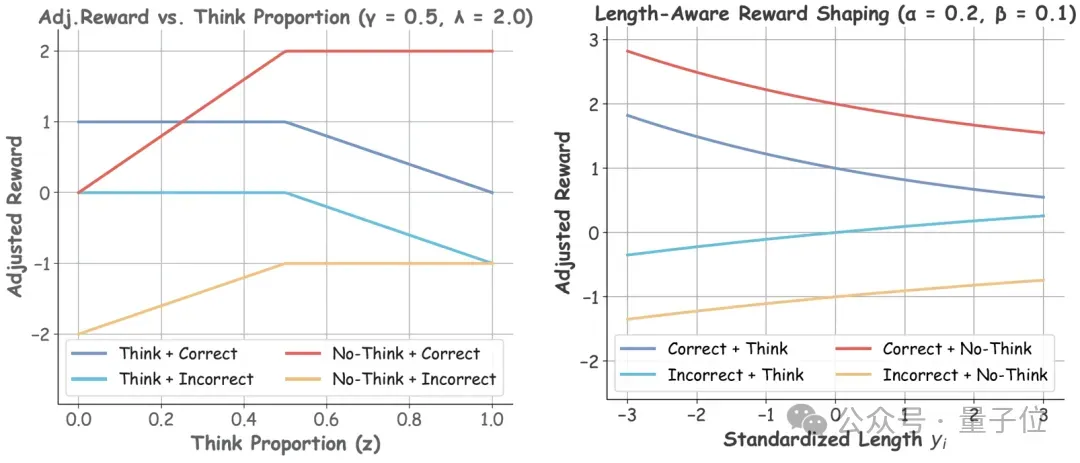
△图3:阶段一和阶段三的奖励函数的可视化
实验结果:AutoThink 更聪明也更节省
在多个数学Benchmark 和多个R1-Style的基础模型上验证了 AutoThink。
实验结果显示:AutoThink 不仅能提升基模的性能,同时大幅减少了推理时的Token消耗,如表1所示。相比之下,大部分的开源模型的性能增强的代价是推理长度(思考过程)的成倍增长;而简洁思考的模型性能往往相比于基础模型几乎无提升甚至下降。特别地:在已经经过大量RL后训练的DeepScaleR[5]上,AutoThink依然能节省额外10%的Token消耗。
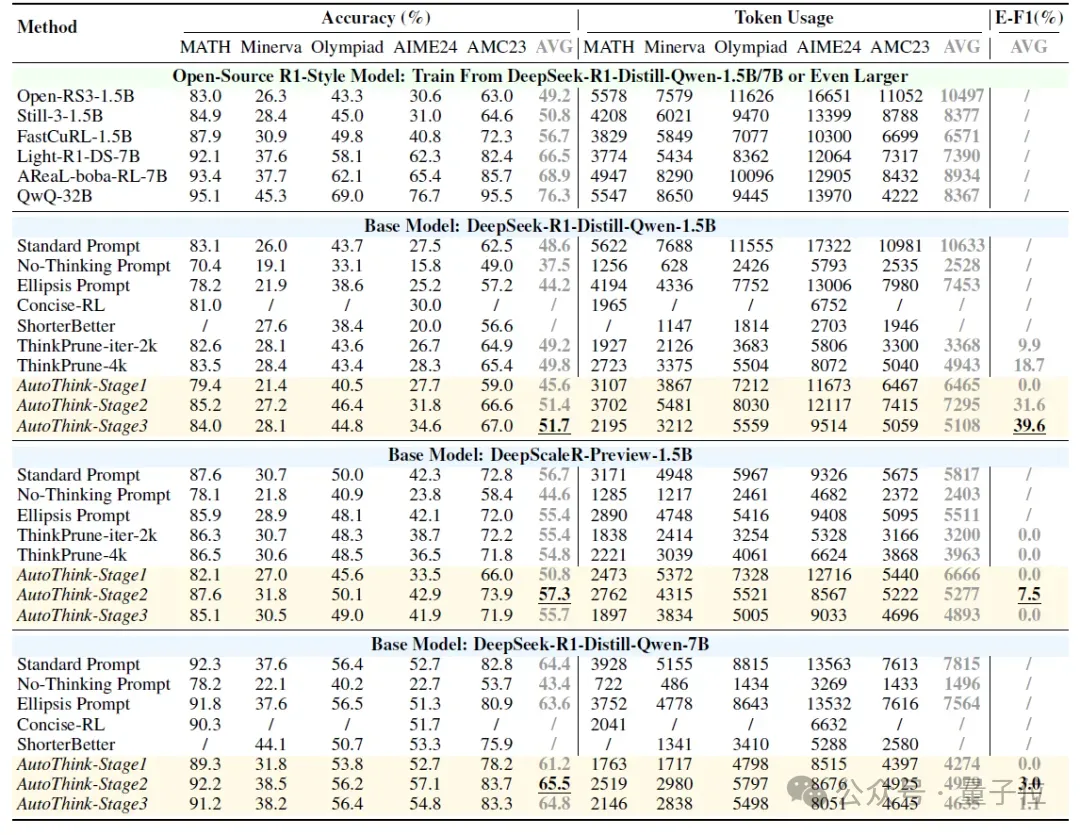
△表1:不同模型和Benchmark上的准确度和推理长度对比
消融实验:三阶段到底有没有用?
为了验证AutoThink多阶段训练设计的必要性,专门设计了两个关键的消融实验。
一方面,移除阶段一中的批次平衡奖励,观察模型是否还能维持“思考”与“不思考”的动态共存;另一方面,尝试直接跳过阶段二,仅保留初始与最终阶段,测试是否还能实现高效推理与准确率提升。
如图4所示,实验结果表明:阶段一的batch奖励平衡是防止模式坍缩、维持推理多样性的关键机制,而跳过阶段二会导致准确率停滞,削弱后续阶段的推理剪枝效果。这验证了三阶段训练方案在稳定性与性能提升上的协同必要性。
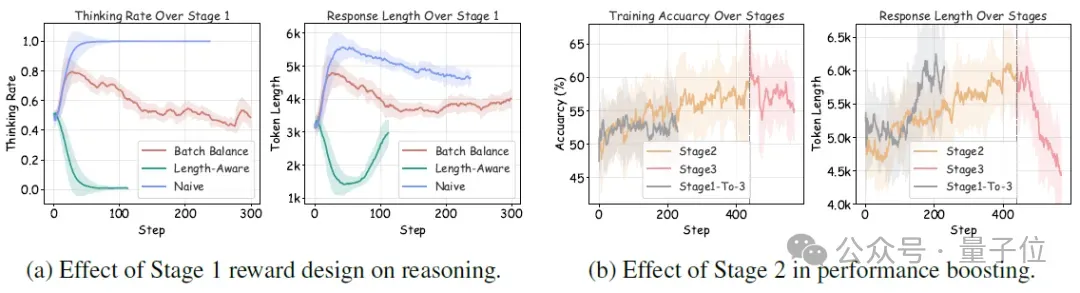
△图4:消融阶段一和阶段二,思考率、准确率和回答长度的变化。
更深入的行为分析:AutoThink 真的是“聪明地不思考”吗?
除了提升准确率和节省token,也从更细致的角度,去理解AutoThink在推理过程中到底发生了什么变化。通过以下三个维度的分析,发现AutoThink并不是“简单粗暴地省略推理”,而是在做有策略的思考选择。
关键词频率分析:不思考 ≠ 胡说八道
统计推理过程中常见的关键词,比如 “Calculate”, “Result”, “Check”等,它们通常用于表达模型的中间推理步骤。结果发现:即使在“不思考模式”下,AutoThink依然频繁使用这类词语。如图5(左)所示,这表明它并非“跳过推理直接乱猜”,而是在内部快速做出判断后,简洁地表达结果。
行为与难度匹配:越难越思考,越简单越跳过
将测试数据按难度划分,并观察AutoThink在不同难度上的“思考比例”。如图5 (右) 所示,结果表明:经AutoThink训练后,模型更倾向于在简单题(如Math)上快速给出答案,而在复杂题上主动开启推理模式,分配更多的推理 token。
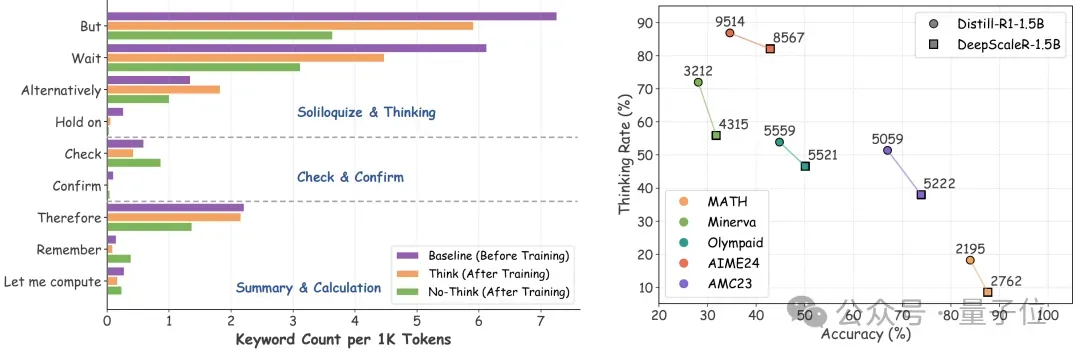
△图5:行为分析——关键词频率和思考与难度的匹配评估
案例展示:轻松应对简单题,灵活应对中等题,深度钻研复杂题
我们进一步选取了三个代表性问题,比较AutoThink在不同提示和模式下的表现。如图6-8所示,在不同难度上AutoThink展现出灵活的、根据题目难度自适应的自主思考行为。

△图6:简单题,AutoThink 在不思考模式下就能快速得出正确答案,高效又准确。

△图7:中等题,模型可能在多个rollouts 中出现“思考”和“不思考”的混合情况,展现出策略灵活性。

△图8:复杂题,AutoThink会启用完整的推理流程,反复验证、严谨解题,最终给出正确答案。
总结:离“任务自觉”的模型更近了一步
AutoThink 提供了一种简单而有效的推理新范式:通过省略号提示配合三阶段强化学习,引导模型不再“逢题必思”,而是根据问题难度自主决定是否思考、思考多少。在多个数学数据集上,AutoThink 实现了优异的准确率–效率平衡,既提升性能,又节省算力,展示出强的适应性和实用性。该研究成果也集成于一站式智能科研平台ScienceOne,并将用于训练ScienceOne的基座大模型S1-Base。
局限与展望
当然,AutoThink 还不是完美的,也能观察到:
- 奖励规避(Reward Hacking):模型可能在“不思考模式”中偷偷加入思考推理内容;
- 推理预算不可控(Uncontrolled Reasoning Budget):目前无法精确控制整体输出长度;
这些问题是后续工作的重点方向,团队相信,让大模型“更聪明地思考、更简洁地表达”,是未来通用智能演进的重要一步。
论文地址:https://arxiv.org/abs/2505.10832代码仓库:https://github.com/ScienceOne-AI/AutoThink模型地址:https://huggingface.co/collections/SONGJUNTU/autothink-682624e1466651b08055b479


